

Скрытый язык компьютеров и необходимость говорить
30 декабря 2023 г.n В истории человеческого существования общение служит незаменимой нитью, сплетающей связи, понимание и знание. Представьте себе: в уголке мира комиксов 7 ноября 1989 года Кэлвин из «Кельвина и Хоббса» разговаривает по телефону со своим отцом. В этой, казалось бы, обычной сцене заключена универсальная истина – необходимость говорить.

Никто не всеведущ, см. Кальвин не знал 11 + 7. Сложности жизни, мириады опыта и богатство информации, которая нас окружает, требуют непрекращающегося поиска понимания. Время от времени нам нужно разговаривать с другими, чтобы искать ответы, точки зрения или просто делиться своими мыслями. Однако этот акт общения не случаен; он следует набору негласных правил, указаний и этикета, которые превращают его в тонкое искусство. Коммуникация, по сути, является мостом, который соединяет умы, позволяя течь идеям, делиться эмоциями и передавать знания. Однако овладение этим искусством – немалый подвиг. Сложности языка, тонкости тона и все эти невербальные сигналы способствуют богатству человеческого взаимодействия.
Теперь, как программист, я нахожу параллельную привлекательность в переводе этого сложного общения в мир машин, разговаривающих с машинами. В огромном пространстве программирования, где точность и ясность имеют первостепенное значение, общение принимает другую форму.
API
Акроним «Интерфейс прикладного программирования», хотя и звучит слишком техническим, на самом деле представляет собой всего лишь термин, обозначающий машины, разговаривающие с машинами. Как и любое общение, оно также имеет различные виды. SOAP (простой протокол доступа к объектам), ReST (передача репрезентативного состояния), RPC (удаленные вызовы процедур) и т. д. и это лишь некоторые из них. .
Стоит отметить, что общение в цифровой сфере не ограничивается только API. Существует также интригующая сфера взаимодействия, управляемого событиями – асинхронный обмен данными, который не всегда носит заметный ярлык API. Тем не менее, он играет решающую роль в организации бесперебойного взаимодействия между различными компонентами, делая системы гибкими и отзывчивыми.
ReST
Я имею дело с веб-API, разновидностями ReST, вот уже почти два десятилетия. И я говорю о разновидностях ReST, поскольку ReST не так упрям, как другие протоколы, такие как SOAP, просто потому, что это не протокол, а просто набор рекомендаций или архитектурного стиля. Это существенно отличает ReST от других.
ReST делает межмашинное общение более гуманным, простым и естественным. Детализация API ReST является скорее философской, чем технической, поскольку при разработке API ReST всегда начинают с существительных.
Что содержится в Имени?
Серьезно, что в названии? почему мы так одержимы именами и называнием вещей? Я писал об этом в блоге десять лет назад. Я считал и до сих пор считаю, что имена — это не что иное, как абстракция к деталям. Без имен разговор был бы слишком многословен, многословен и все равно не очень понятен. Мы склонны давать вещам имена и, чтобы сделать их более понятными, мы добавляем более разборчивые имена. Чем больше существительных, тем богаче словарный запас. У эскимосов есть двадцать с лишним названий разных видов льда. Имена не ограничиваются вещами или местами, но также охватывают множество действий.
Действия
Но между именами и действиями существует огромная разница. Если имена и действия представляют собой наборы, математические наборы, вы заметите, что кардинальность, количество элементов в наборе, имен увеличивается со временем, тогда как для действий это не так. Действие «Вырезать» имеет одно и то же название, когда вы режете бумагу и режете овощи. Действия, таким образом, полиморфны в
природа. Одно и то же действие может быть связано с несколькими существительными.
HTTP
Хватит философии, давайте теперь сосредоточимся на технических вопросах. ReST появился вместе с HTTP, и это тесное взаимодействие. Есть несколько недопониманий по поводу HTTP, в основном по поводу его использования. Большинство людей рассматривают HTTP как транспортный протокол, но они не виноваты, вы можете загружать файлы с помощью HTTP, так что можно легко на него попасться. Путаница в том, что HTTP является транспортным протоколом, связана с тем, что эта аббревиатура буквально
:::совет Протокол передачи гипертекста
:::
Когда вы выполняете действие с использованием HTTP, оно обычно включает в себя своего рода перетасовку документов, вы либо отправляете документ на сервер или получение его с сервера. Слово, на котором вам действительно стоит сосредоточиться, — это Гипертекст. Поскольку большую часть времени содержание предложения обычно находится в середине, к сожалению, многие отдали предпочтение Переносу, а не Гипертексту, и использовали как синоним Транспорт вместо Переноса, где оба являются буквально разные термины.
:::совет Дело в том, что HTTP — это «Протокол приложений»
.:::
Он работает поверх реальных транспортных протоколов, таких как TCP/IP (ориентированный на соединение) или UDP или QUIC (без соединения) в случае HTTP2.
HTTP-глаголы (методы)
Чтобы перетасовать документ, HTTP определяет очень мало команд, ограничивающихся GET, PUT, DELETE и POST
- GET — получение документа
- PUT — размещение документа
- DELETE — удаление документа
И давайте пока не будем говорить о POST, вернемся к этому позже.
Диалог
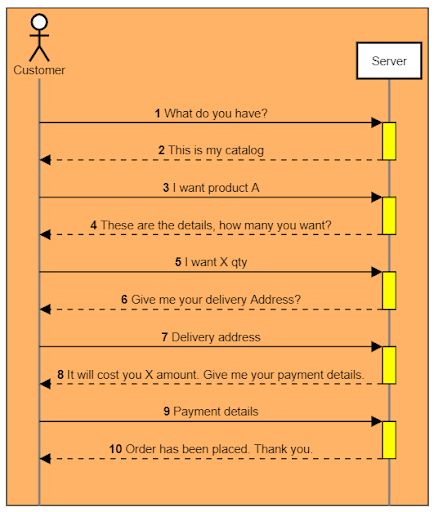
На изображении выше изображен простой диалог между пользователем и некоторым веб-приложением. Каждое сообщение в этом диалоге представляет собой своего рода документ, передаваемый между сторонами. Давайте пока не будем беспокоиться о том, что перетасовано. Он отслеживает рабочий процесс веб-приложения.
Типы медиа
Данные, которые передаются между сервером и пользователем, соответствуют определенному согласованному формату, чтобы обе стороны могли их понять. Это форматирование определяется типом носителя. Давайте рассмотрим несколько примеров.
* текстовый/обычный * текст/html * изображение/jpg * приложение/xml * application/vnd.example+xml
Выглядит знакомо, за исключением, возможно, последнего, и я не имею в виду форматирование.
Давайте прочитаем последний тип носителя
- приложение
Мультимедиа предназначены для использования приложением, а не людьми * внд
Это пользовательский тип носителя, определенный поставщиком. * пример
Это имя типа носителя, указанное поставщиком * +xml
Этот тип носителя основан на уже известном типе носителя xml
Гипер-Типы медиа
Теперь мы рассмотрели типы мультимедиа. Что означает Гипер? Пользователь использует какое-то приложение, которое обращается к серверу от имени пользователя. Приложения, используемые пользователями, называются пользовательскими агентами. Веб-браузер является примером пользовательского агента. Эти пользовательские агенты понимают и понимают медиа, которые передаются на сервер и с него.
Подталкивание
Приложение на сервере должно иметь повестку дня, поскольку диалог должен иметь завершение. Оно должно закончиться либо успешно, либо неудачно. Как и в любом диалоге, пользовательский агент и приложение на сервере по очереди делают следующий шаг в соответствии с выбором пользовательского агента, фактически от имени пользователя. Веб-приложение просто подталкивает пользователя к прекращению текущего взаимодействия.
Рассмотрим следующее взаимодействие, которое представляет собой один запрос-ответ.
Запрос
POST /orders
Host: example.org
Content-type: application/vnd.example+xml
Accept: application/vnd.example+xml
<order xmlns=“http://schemas.example.org/”>
<item qty=“2”>ITEM-1</item>
</order>
Ответить
HTTP/1.1 201 Order created
Location: http://example.org/orders/1234
Content-Type: application/vnd.example+xml
<order xmlns=“http://schemas.example.org/”>
<item qty=“2”>ITEM-1</item>
<next xmlns=“http://schemas.example.org/state-machine”
rel=“payment”
uri=“http://example.org/orders/1234/payment”
/>
<next xmlns=“http://schemas.example.org/state-machine”
rel=“self”
uri=“http://example.org/orders/1234”
/>
</order>
Давайте посмотрим, какой пользовательский агент отправляет запрос
- Метод запроса
Один из HTTP-глаголов в приведенном выше запросе — POST * URI запроса
URI ресурса. В приведенном выше запросе это /orders * Заголовки запросов
Accept позволяет серверу узнать, какой тип мультимедиа интересует пользовательского агента
Content-Type сообщает серверу, в каком формате отправляются данные в запросе * Тело запроса
И, наконец, данные, отправляемые на сервер.
Давайте разберем ответ, полученный от сервера
- Координация действий пользователя и агента <ли>
Здесь говорится о последствиях запроса
HTTP/1.1 ==201==* Заказ создан***
201 — это код состояния, сообщающий пользовательскому агенту, что запрос успешно выполнен и, как следствие, создается ресурс. Ресурс может показаться слишком техническим, но на самом деле это просто означает, что на сервере создается новый объект. * Местоположение: http://example.org/orders/1234
Местоположение – это заголовок ответа. Он сообщает пользовательскому агенту, что если он заинтересован, он может перейти по ссылке в заголовке и перенаправить пользовательского агента, в данном случае, на вновь созданный ресурс. * Тип контента: application/vnd.example+xml
Он просто сообщает пользовательскому агенту, что отправляемые ему данные используют тип носителя application/vnd.example+xml. * Носители или сами данные. * Остальные байты, отправленные сервером, представляют собой просто фактические данные.
Теперь, поскольку тип носителя в данном случае является пользовательским, все зависит от пользовательского агента, чтобы понять его. В этом примере пользовательский агент может быть достаточно умен, чтобы проанализировать данные ответа и * Переходим к платежам * Или просто взаимодействуйте с новым созданным ресурсом заказа.
В любом случае пользовательский агент может использовать различные HTTP-глаголы для взаимодействия с этими ресурсами.
Сервер просто подталкивает пользователя через пользовательский агент к завершению рабочего процесса размещения заказа.
Поскольку решение, принятое пользовательским агентом, имеет два результата, возможны два взаимодействия.
Предположим, пользователь хочет отменить заказ
Запрос
DELETE /orders/1234
Host: example.org
Accept: application/vnd.example+xml
Ответить
HTTP/1.1 200 Okay
Content-Type: application/vnd.example+xml
<order xmlns=“http://schemas.example.org/”>
<item qty=“2”>ITEM-1</item>
<status>Cancelled</status>
</order>
Или пользователь хочет продолжить оплату
Запрос
POST /orders/1234/payment
Host: example.org
Content-Type: application/vnd.example+xml
Accept: application/vnd.example+xml
<payment orderId=“1234” xmlns=“http://schemas.example.org/”>
…
</order>
Ответить
HTTP/1.1 201 Receipt generated
Location: http://example.org/orders/1234/receipt
Content-Type: application/vnd.example+xml
<order xmlns=“http://schemas.example.org/”>
<item qty=“2”>ITEM-1</item>
<next xmlns=“http://schemas.example.org/state-machine”
rel=“self”
uri=“http://example.org/orders/1234”
/>
<status>Not Ready</status>
</order>
Во всех этих взаимодействиях пользователю предоставляется достаточная координация и сами средства массовой информации, чтобы он мог успешно завершить рабочий процесс.
В случае, если пользовательский агент следил за платежами и они были успешно обработаны, будет сгенерирована квитанция о побочном эффекте. Данные координации сообщают об этом 201 и дают uri для получения в качестве заголовка Location. Теперь клиент может опросить собственный uri, чтобы узнать, готов ли заказ.
Опрос может показаться глупым, но при использовании кэшей он чрезвычайно эффективен. Эти кеши уменьшают нагрузку на сервер, так как чаще всего заказ просто не готов сразу, так как для работы с заказом требуется время.
Любопытный случай POST
Важным моментом является то, что у клиента есть некоторая часть состояния приложения, кэшированная локально или по всей цепочке.
Теперь о POST, который был введен немного по-другому. Я рассматриваю это после других глаголов. Создание в основном связано с POST, хотя на самом деле эту работу может выполнить GET, за которым следует PUT.
Например, создание нового заказа может представлять собой серию операций:
- Получить последний заказ
- Создать новый заказ локально и вернуть его.
Тогда почему POST?
Ответ совершенно очевиден, я просто сейчас его уточняю. Важно отметить, что это многопользовательское приложение
.Допустим, новый идентификатор заказа является функцией количества заказов в коллекции + 1. Поскольку это многопользовательское приложение, одновременно может быть несколько пользователей, желающих создать новый заказ. Все эти пользователи запрашивают GET идентификатор последнего заказа, и все в конечном итоге получают одинаковый результат. Когда эти пользователи PUT создают новый заказ, побеждает тот, кто сделает это последним. Пользователи узнают о неудаче или успехе, только GETпроверив заказ по идентификатору заказа и сверив его с локально созданным заказом. Неудачливые пользователи просто должны повторять ту же последовательность действий, пока не добьются успеха. Скорее, если пользователи просто сообщат серверу о своем намерении создать новый заказ, и всемогущий сервер, имеющий целостное состояние приложения, будет лучше знать, как обрабатывать запросы. GET / PUT / DELETE или любая их последовательность будет недостаточной для выражения такого намерения, поэтому POST. Неудивительно, что это звучит и кажется чуждым.
Согласованность кэша
Однако кэши создают проблему согласованности. Допустим, клиенту было приказано кэшировать ответ на несколько секунд, а тем временем заказ готов. Клиент на основании кэшированного ответа принял решение отменить заказ. В этом случае состояние клиента и сервера разошлось. Чтобы сделать отмену безопасной, клиент может добавить условие в виде заголовка If-Match. Сервер, в случае, если условие не соответствует, просто отказывается обрабатывать запрос, сообщая клиенту, что предварительное условие для выполнения запроса не выполнено. В маловероятном случае клиент не отправил заголовки If-Match, сервер все равно может сообщить об этом как о конфликте 409. Или 406 неприемлемо.
Запрос
DELETE /orders/1234
Host: example.org
If-Match: status=Not Ready
Accept: application/vnd.example+xml
Ответить
HTTP/1.1 412 Precondition failed.
Content-Type: application/vnd.example+xml
<order xmlns=“http://schemas.example.org/”>
<item qty=“2”>ITEM-1</item>
<next xmlns=“http://schemas.example.org/state-machine”
rel=“self”
uri=“http://example.org/orders/1234”
/>
<status>Ready</status>
</order>
Отменил заказ, но ==Почему?==
Как бизнес-пользователь, разве вы не хотели бы знать, почему заказ был отменен? Эти причины выходят за рамки проектирования API и больше углубляются в бизнес-задачи. Если API реализовал DELETE для отмены заказа, типичное взаимодействие может выглядеть следующим образом.
Запрос
DELETE /orders/1234
Host: example.org
Accept: application/vnd.example+xml
Ответить
HTTP/1.1 200 Okay
Content-Type: application/vnd.example+xml
<order xmlns=“http://schemas.example.org/”>
<item qty=“2”>ITEM-1</item>
<status>Cancelled</status>
</order>
Проблема с вышеуказанным взаимодействием заключается в том, что DELETE не принимает никакого тела. Как мы можем решить эту проблему?
Давайте попробуем использовать POST
Запрос
POST /orders
Host: example.org
Accept: application/vnd.example+xml
OrderId=14
&Operation=Cancel
&Reason=Just to annoy you
Ответить
HTTP/1.1 200 Okay
Content-Type: application/vnd.example+xml
<order xmlns=“http://schemas.example.org/”>
<item qty=“2”>ITEM-1</item>
<status>Cancelled</status>
</order>
Это даже не выглядит правильно с самого начала. Такое ощущение, что мы выполняем бизнес-операцию, указанную в Operation. Операция теперь является ключевым словом, которое необходимо обрабатывать за пределами ограниченного набора HTTP-глаголов. Таким образом, API будет продолжать добавлять все больше и больше глаголов, требующих специальной обработки.
Можем ли мы добиться большего?
Как только мы начнем ограничивать себя только четырьмя глаголами, которые предоставляет HTTP, мы определенно сможем добиться большего. Давайте вернемся к той же проблеме с ограничениями проектирования API.
Не забывайте, что у вас ==безграничный запас существительных==. И мы естественным образом запрограммированы постоянно создавать случайные имена.
Запрос
POST /CancelledOrders
Host: example.org
Accept: application/vnd.example+xml
OrderId=14
&Reason=Just to annoy you
Ответить
HTTP/1.1 200 Okay
Content-Type: application/vnd.example+xml
<order xmlns=“http://shemas.example.org/”>
<item qty=“2”>ITEM-1</item>
<status>Cancelled</status>
</order>
Хотя кажется, что придумывать имена просто, это очень утомительно. Неудивительно, что ярый сторонник ReST, Марк Бейкер или Тим-Бернерс Ли, предложил не делать этого. добавить какое-либо значение к URI и сделать их непрозрачными.
Непрозрачные URI избавляют нас от необходимости время от времени создавать новые существительные за счет понятного API. Это также затрудняет документирование API, поскольку конечные точки API определяются во время выполнения. Кроме того, безопасность и соответствующие функции могут быть полезны только после установки непрозрачного URI.
Рой Филдинг, с другой стороны, считает, что ури имеют смысл и в некотором роде имеют больше смысла. Непрозрачные URI — для ленивых.
Представления
Теперь давайте сосредоточимся на ==ReST==. Это не ресурс, который отправляется пользовательскому агенту. Пользовательский агент запрашивает конкретный тип мультимедиа, который он может понять. Давайте рассмотрим следующее HTTP-взаимодействие.
Запрос
GET /orders/1234
Host: example.org
Accept: text/plain
Ответить
Если веб-приложение не понимает запрошенный тип носителя, оно может просто указать эту неспособность как
HTTP/1.1 415 Unsupported Media Type.
Or if it does indeed supports the requested media type
HTTP/1.1 200 Okay
Content-Type: text/plain
Order 1234 is not ready
Если пользовательский агент запрашивает типы мультимедиа, которые поддерживаются веб-приложением, он может отправить данные ресурса, соответствующие запрошенному типу мультимедиа. Здесь это один и тот же ресурс, но отформатированный как разные типы мультимедиа, и все эти варианты одного и того же ресурса называются представлениями. Поскольку данные, которые передаются между пользовательским агентом и сервером, могут представлять собой разные представления, они известны как ==Re==presentational ==S==tate ==T==transfer или просто ReST.
Дополнительная литература
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27222)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)