

Четыре типа машинного обучения | Часть 2
3 декабря 2022 г.В предыдущем сообщении мы видели первые два виды машинного обучения. В этом посте мы обсудим два других типа машинного обучения. Это — полууправляемое машинное обучение и обучение с подкреплением.
Обучение под наблюдением
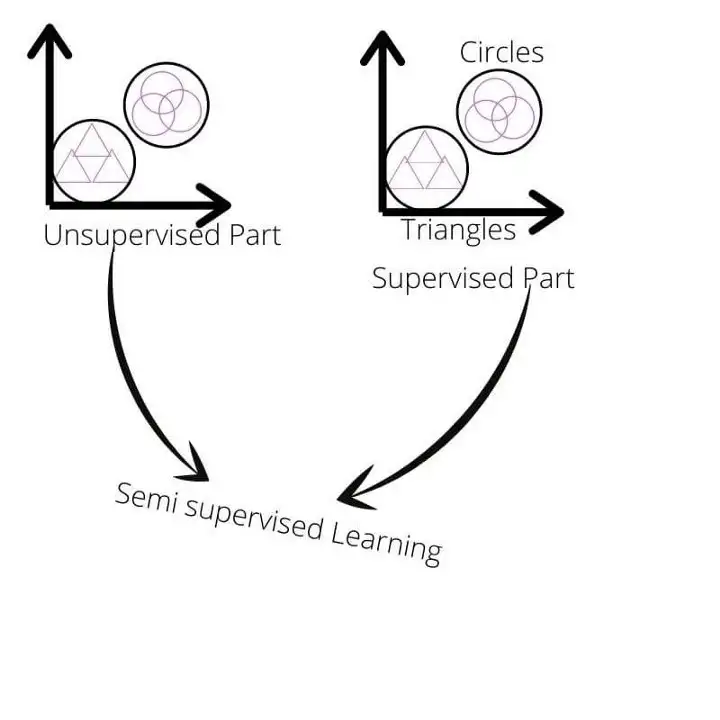
Это новый тип обучения, который является важной частью области машинного обучения. Мы используем этот тип обучения, когда у нас есть несколько размеченных данных и много неразмеченных данных в процессе обучения. Этот тип обучения находится между контролируемым и неконтролируемым обучением. Та часть, где у нас есть помеченные данные, относится к контролируемому домену, а количество немаркированных данных относится к неконтролируемому домену.
Получение размеченных данных очень дорого и требует много времени, в то время как получение неразмеченной информации является простым и недорогим. Использование неразмеченных данных с размеченными данными привело к значительному повышению точности обучения.
Таким образом, могут возникнуть ситуации, когда у нас есть небольшое количество размеченных данных и большое количество неразмеченных данных. Тогда в таких случаях мы не можем перейти ни к контролируемой, ни к неконтролируемой стратегии обучения. Так что в таких случаях нам на помощь приходит полууправляемое обучение. Мы можем значительно повысить точность и сэкономить время и силы при маркировке каждой точки данных.
Аналогия.
На языке непрофессионала или словами, которые легко понять, полуконтролируемое обучение похоже на наблюдение за учеником в течение короткого промежутка времени, а затем позволяет ему идти и бродить по полю самостоятельно.
Он решает задачи классификации. Это означает, что вам понадобятся некоторые контролируемые детали. Затем в то же время вам нужно обучать модель на больших наборах неразмеченных данных, для чего вам нужна неконтролируемая часть машинного обучения.
Основная идея состоит в том, чтобы сгруппировать разные точки данных в одних и тех же кластерах, а затем использовать контролируемое обучение, чтобы назвать точки данных или экземпляры в этих группах.
Например, предположим, что у нас есть набор данных из 1000 изображений различных транспортных средств. И у нас есть четыре категории, и 100 точек данных или экземпляров помечены именами этих категорий. Затем мы используем концепцию полуконтролируемого обучения. Во-первых, нам нужно создать кластеры изображений, содержащих одинаковые автомобили. Как только группа кластеров была сформирована с использованием подхода к обучению без учителя, вступает в игру задача обучения с учителем. Затем мы присваиваем имена различным коллекциям и, следовательно, нескольким экземплярам в этих кластерах. Таким образом, мы используем частично контролируемое обучение для обучения модели с использованием обеих стратегий обучения, т. е. контролируемого и неконтролируемого обучения.
Обучение с подкреплением
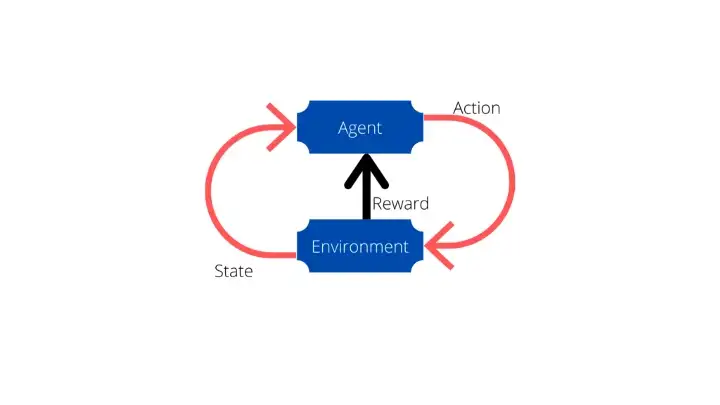
В этой стратегии машинного обучения нас интересует, как агент максимизирует вознаграждение. В этом обучении есть несколько важных концепций, которые необходимо понять.
Первый — Агент.
Агент — это исполнитель действия — машина, которая выполняет действие в среде. Вся цель агента состоит в том, чтобы сделать вознаграждение максимальным, выполняя действия правильно. Если агент выполняет действие неправильно, то агент получает наказание, то есть вознаграждение уменьшается из общего хранилища вознаграждений агента.
Второй — действие.
Это действия, которые агент выполняет в среде. Некоторые примеры: робот ходит, робот играет в теннис и т. д.
Третий — Окружающая среда.
Среда — это игровое поле для агента. Здесь он совершает действия. Среда может быть разной. Для игрового ИИ это игра. Для робота-уборщика это дом, а для марсохода — Марс.
Четвертый — Награда.
Награда — это достижение, которое увеличивает счет агента. В процессе обучения непрерывно циркулируют награды. Агент пытается максимизировать вознаграждение, и он делает это так, чтобы его отношения встали. Примером награды может быть увеличение счета во время игры.
Пятое — состояние.
Состояние означает обновленную среду. Когда агент выполняет какое-либо действие в среде, среда обновляется. Эта обновленная среда возвращается агенту и называется состоянием.
Это использование этого типа обучения происходит, когда у нас нет данных для начала. В обучении с подкреплением агент начинает выполнять задачи, и если он выполняет задачи правильно, агент получает вознаграждение, а если он ошибается, его наказывают. Как и в приведенном выше примере, увеличение счета – это награда, а снижение – наказание.
Для аналогии, это как оставить человека в машине и сказать ему, чтобы он научился водить. Он будет учиться вождению самостоятельно, делая ошибки и исправляя их. Здесь наградой могут быть деньги. Если водитель не ошибется, он получит 1$, а если ошибется, то даст 50 центов.
Выводы
Это четыре типа стратегий машинного обучения. Все алгоритмы машинного обучения попадают в одно из вышеперечисленных обучений. Они предлагают чрезвычайно значительное количество алгоритмов, которые могут быть реализованы. Мы обсудим их в следующих сообщениях.
Если вам понравился контент, поделитесь им 🙂 , а если вы считаете, что контент нуждается в улучшении, оставьте комментарий ниже с предложениями.
Также опубликовано Здесь
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27156)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)