

Наука данных, стоящая за просягами R/Antipwork
17 июня 2025 г.Таблица ссылок
Аннотация и 1. Введение
2. Связанная работа
3. Методология
4. Результаты
5. Обсуждение
6. Заключение, ссылки и приложение
3 Методология
3.1 Данные
Мы загрузили все сообщения и комментарии на R/Antipwork Subreddit с 1 января 2019 года по 31 июля 2022 года, используя API Pushshift [9] [3]. Мы рассматривали только сообщения, по крайней мере, с одним ассоциированным комментарием в качестве прокси для дублирования сообщений, ссылающихся на одно и то же событие, не по тематическому и спам-сообщениям, а также посты, которые не получали вовлечения пользователей по другим причинам. Набор данных содержал 304 096 постов и 12 141 548 комментариев. Эти сообщения были сделаны 119 746 пользователями (плакатами), и комментарии были сделаны 1298 451 пользователями (комментаторы).
Мы предварительно обработали набор данных для удаления комментариев, которые потенциально могут сметить наш анализ. Мы отфильтровали комментарии о том, что: (i) были удалены пользователями или модераторами, но остаются в наборе данных в качестве заполнителей (комментарии обычно удаляются для нарушения руководящих принципов сообщества) или (ii) были комментариями от ботов (например«Я бот ...»,Как многие делают по соглашению). После фильтрации 11 665 342 комментариев остались в наборе данных (96,1%). Мы удалили сообщения, которые имели нулевые комментарии после фильтрации, оставив 284 449 постов (93,5%)
3.2 Определения
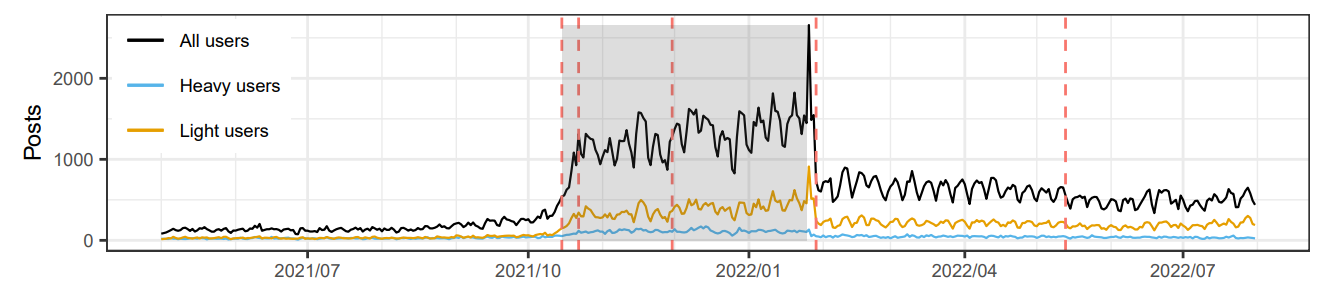
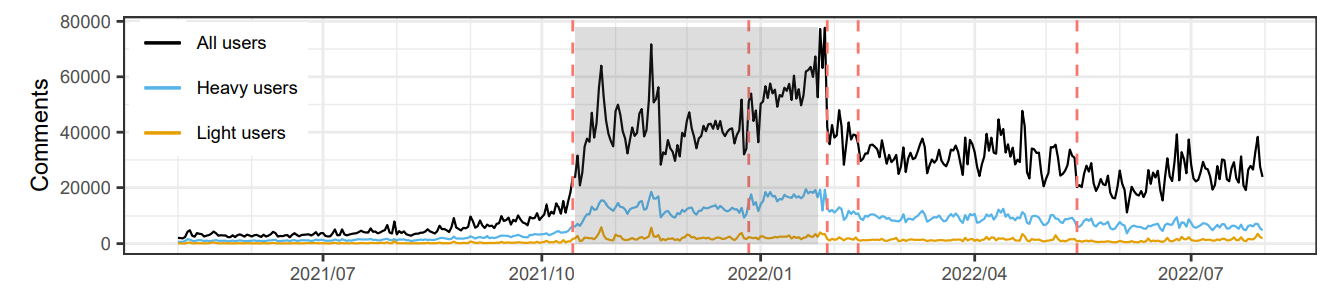
3.2.1 Типы пользователей.В нашем анализе мы сравниваем поведение двух групп пользователей, которые мы называем «легкими» и «тяжелыми» пользователями R/Antipwork. Мы определяемлегкие плакаты или комментаторыКак те, у кого есть только один пост или комментарий в наборе данных, соответственно. Большинство плакатов представляют собой легкие плакаты (75,1%), а высокий процент комментаторов - легкие комментаторы (42,5%). Мы определяемтяжелые плакаты или комментаторыКак 1% пользователей, занявшие порядок по количеству сообщений или комментариев, соответственно. В целом, тяжелые плакаты сделали 10,1% постов, а тяжелые комментаторы были ответственны за 29,8% комментариев.
3.2.2 периоды времени.Для нашего анализа моделирования тем, мы разделили набор данных на три периода времени:
• Период 1:1 января 2019 г. - 14 октября 2021 г.
• Период 2:15 октября 2021 г. - 24 января 2022 года
• Период 3:25 января 2022 года - 31 июля 2022 года
Эти периоды определены двумя событиями в основных средствах массовой информации: публикация статьи Newsweek [10], которая была первым примером основной статьи в СМИ, ссылаясь на вирусную пост [11] на R/противодействие (15 октября 2021 года) и интервью Fox News с Doreen Ford (25 января 2022 года). Период 2 выделен как серая коробка во всех фигурах, где ось 𝑥 представляет время.
3.3 Обнаружение точки изменения
Мы используем деревья классификации и регрессии (CART) для обнаружения точек изменения [5]. CART-это непараметрический метод, который использует дерево решений для рекурсивного сегментации предиктора на более чистые, более однородные интервалы (часто называемые «расщеплением»). Этот процесс сегментации завершается параметрами сложности
Это регулирует стоимость выращивания дерева, добавив штраф за добавление дополнительных разделов («обрезка»). В нашем случае мы устанавливаем дерево регрессии с зависимой переменной в качестве количества постов или комментариев, а также пространство предикторов, как каждый день с 1 января 2019 года - 31 июля 2022 года. Мы использовали пакет RPART R для создания регрессионных моделей [32], индекса Джини для разделения и параметра сложности 0,01 для обрезки.
3.4 Тематическое моделирование
Мы используем скрытое распределение Dirichlet (LDA) для моделирования тем [4]. LDA-это генеративная модель, которая определяет набор скрытых тем, оценивая дистрибутирование тематического документа и тематического слова в документах для предопределенного количества тем. В нашем случае мы считаем, что каждый пост является документом и содержимым этого документа как объединение всех комментариев для этого поста. Мы не включаем текст Post как часть документа, потому что большая доля пост -тел состоит из изображений. Мы предприняли комментарии к моделированию тем, удаляя URL -адреса и останавливаем слова, заменив акцентированных символов на их эквиваленты ASCII, заменив сокращения своими составными словами и лемматизировали все слова. Наконец, мы отфильтровали посты с менее чем 50 комментариями, оставив 11 368 863 комментариев (97,5%) в 181 913 посты (64,0%) для тематического моделирования.
LDA применяли к каждому из трех периодов времени отдельно (см. Раздел 3.2.2). Периоды 1, 2 и 3 содержали 40 794; 71 470 и 69 649 постов соответственно. Мы оцениваем качество тематических моделей с использованием оценки когерентности [24], чтобы выбрать оптимальное количество тем. Каждая тема была помечена человеческим аннотатором со знанием R/противоказано, и темы были выровнены между моделями, использующими эти этикетки, и расстоянием Дженсена-Шаннона между распределением тематического слова. Тематическое моделирование было выполнено с использованием библиотеки Gensim Python [26].
Авторы:
(1) Алан Медлар, Университет Хельсинки, Финляндия (Alan.j.medlar@helsinki.fi);
(2) Ян Лю, Университет Хельсинки, Финляндия (yang.liu@helsinki.fi);
(3) Дорота Гловака, Университет Хельсинки, Финляндия (dorota.glowacka@helsinki.fi).
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
[9] https://pushshift.io/
[10] https://www.newsweek.com/1639419
[11] https://www.reddit.com/r/antiwork/comments/q82vqk/
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)