Это видео является сокращенной версией этого сообщения. Если вы ищете видео, содержащее весь этот пост, пролистайте вниз в конец этой страницы, чтобы найти его.
Оглавление
- Что такое модель клиент-сервер?
- Ограничения модели клиент-сервер
- Единый источник правды
- Адресация на основе местоположения
- Единая точка отказа
- Затратно масштабировать
-
Контент с ограниченным доступом и цензурой
* Распределенная сеть * Централизованная, децентрализованная и распределенная * Адресация содержания * Состав CID * Ненадежная проверка и сохранение * Unstoppable Data & Услуги * Масштабирование & Межпланетный
* Ссылки * Начало работы * Учебные ресурсы * Видео * Примеры использования * Другие ресурсы
Что такое модель клиент-сервер?

Ограничения модели клиент-сервер
Сегодня всего несколько компаний отвечают за обслуживание большей части Интернета. У нас есть Google, Amazon, Facebook и Fastly, и это лишь некоторые из них. Эти компании в совокупности предоставляют нам нашу рекламу, веб-страницы, социальные сети, видео, изображения и позволяют нам размещать серверы и службы в своей инфраструктуре. Чтобы взаимодействовать с этими сервисами, мы также должны использовать их API. Мы отправляем некоторые данные на их серверы и ждем ответа. Затем мы обрабатываем этот ответ и делаем все необходимое для создания наших приложений и веб-сайтов.
С этим дизайном есть несколько проблем, от затрат до конфиденциальности. Например, бесплатные услуги часто финансируются за счет рекламы. Реклама может нарушить конфиденциальность, поскольку все наши данные проходят через несколько центральных точек и продаются третьим лицам. По сути, бесплатные услуги оплачиваются нашим вниманием и конфиденциальной информацией.

Единый источник правды
Если вы хотите просмотреть видео, отправить сообщение, сотрудничать с удаленными товарищами по команде или вообще сделать что-либо в Интернете, вы проходите через чей-то центральный сервер. Этот принцип лежит в основе модели клиент-сервер. Мы используем клиент, например веб-браузер или приложение для чата, и общаемся с одним объектом, который является сервером в модели клиент-сервер. Если мы полагаемся только на одну точку в качестве источника истины, возникает целый ряд проблем, таких как доверие. Сегодня у нас есть сертификаты TLS для проверки того, кем они себя называют, однако это не принесет нам много пользы, если эта служба будет скомпрометирована. Даже если мы уверены в том, что это за объект, это все равно не поможет нам узнать, как рекламодатели или другие лица используют наши данные или даже какие данные собираются.
Разработчики, создающие приложения, часто полагаются на API, которыми управляют крупные централизованные организации (например, Stripe, Google, Cloudinary, Auth0). Чем больше API использует ваше приложение, тем оно более хрупкое. Если какой-либо из API недоступен, ваше приложение перестанет работать. Сегодня популярным способом построения является использование API другого удаленного сервиса, что делает Интернет в целом очень уязвимым.
Адресация на основе местоположения
В модели клиент-сервер, если вам нужны данные, вы должны знать, где они находятся. Если вам нужно изображение, вам обычно нужен полный URL-адрес этого изображения, чтобы получить его и поделиться им. Если это изображение больше недоступно, вам нужно либо найти его, либо загрузить копию на другой сервер, чтобы снова сделать его доступным (при условии, что у вас есть собственная копия). После загрузки вы также должны сообщить новое местоположение этого изображения. Этот принцип называется адресация на основе местоположения, и именно так сегодня функционирует большая часть всемирной паутины. Вы переходите на веб-сайт с URL-адресом, и все данные с этого веб-сайта адресуются по местоположению данных. Если аналогия с изображением слишком сложна для понимания, подумайте, как бы вы поделились видео на своей любимой видеоплатформе; скорее всего, вы просто поделитесь URL-адресом видео, также известным как местонахождение видео.
Единая точка отказа
Вспомните, когда AWS, Fastly, Facebook или YouTube отключатся. Эти события рассматриваются как новости и часто замедляют или даже останавливают производительность. Когда одна из этих служб отключается, это гораздо важнее, чем просто потеря одного изображения или видео, теперь вы вообще потеряли доступ к своей возможности делать новые данные доступными! Все данные, которые вы разместили в этих центральных узлах, временно полностью недоступны или, что еще хуже, навсегда. Доступ к местоположению данных невозможен, поскольку он находится в автономном режиме. Вы не можете запросить данные из более широкой сети и ожидать их получения, даже если у другой связанной сущности есть те самые данные, которые вы ищете.
Конечно, вы можете разместить свой собственный сервис. Возможно, распределите расположение ваших серверов таким образом, чтобы предотвратить прекращение работы вашего сервиса из-за одного сбоя. Допустим, вам даже пришла в голову следующая большая идея для веб-сайта или платформы, где вы контролируете всю свою инфраструктуру, не полагаясь на какой-то другой центральный объект для своих нужд…
Дорожно масштабировать
Это приводит к моему следующему замечанию: Масштабирование может быть очень дорогим. Эти расходы не всегда или, может быть, даже обычно не происходят линейно. Это означает, что взрыв трафика может привести к взрыву затрат. Независимо от того, размещаете ли вы свою собственную инфраструктуру или платите кому-то еще, вы будете платить за нее, если хотите, чтобы она масштабировалась и работала эффективно. Чем больше у вас пользователей, тем больше генерируется трафика, увеличиваются расходы на ЦП, ОЗУ и пропускную способность. Кроме того, если пользователи в конечном итоге зависят от вашей службы, вы обязаны поддерживать эту службу в рабочем состоянии и доступной, если хотите удержать пользователей и сделать их счастливыми. Не каждый может позволить себе такие расходы, и они могут быть весьма пугающими, особенно если вы просто хотите создать забавный проект, технологию или даже блог. Многие компании, упомянутые ранее, обращаются к рекламе, чтобы покрыть эти расходы. Это приводит к тому, что многие люди продают свою личную информацию в обмен на бесплатные онлайн-услуги.

Контент с ограниченным доступом и цензурой
Создатели контента часто полностью привязаны к нескольким платформам, таким как YouTube, Instagram и другим. На них также может распространяться целый ряд правил и положений, гораздо более строгих, чем те, которые могут быть разрешены вашим местным правительством, и вы не имеете права голоса в том, когда и как эти правила изменятся.
Если вы хотите разместить какой-либо контент на одной из этих платформ, вы должны убедиться, что соблюдаете их правила и нормы. Это может быть очень неприятно, когда популярный контент теряется из-за изменения или обновления правил, что довольно часто встречается сегодня с видео и графическими медиа. Как создатель контента иногда может показаться невероятно сложной задачей решить эту проблему. Вы можете настроить свои собственные службы, как упоминалось ранее, однако не все знают, как это сделать эффективно, и не готовы к затратам времени и средств, связанных с этим.
Мы можем сделать лучше; Отказ от модели клиент-сервер означает переосмысление того, как работает Интернет в том виде, в каком мы его знаем сегодня. Модель клиент-сервер представляет Web2 в том виде, в каком мы его знаем сегодня. Нравится вам это или нет, но есть четкий и сильный аргумент в пользу того, как можно улучшить модель web2, относящуюся к модели клиент-сервер. Как мы назовем эту новую модель?
Распределенная сеть

Эта новая модель относится к распределенной сети, так что давайте поговорим об этом и о том, как в нее вписывается IPFS. Но сначала, для непосвященных, давайте кратко обсудим, что такое распределенная сеть и что такое это значит для тебя. Являетесь ли вы пользователем или разработчиком, вы можете извлечь выгоду из распределенной сети, которую я называю web3.
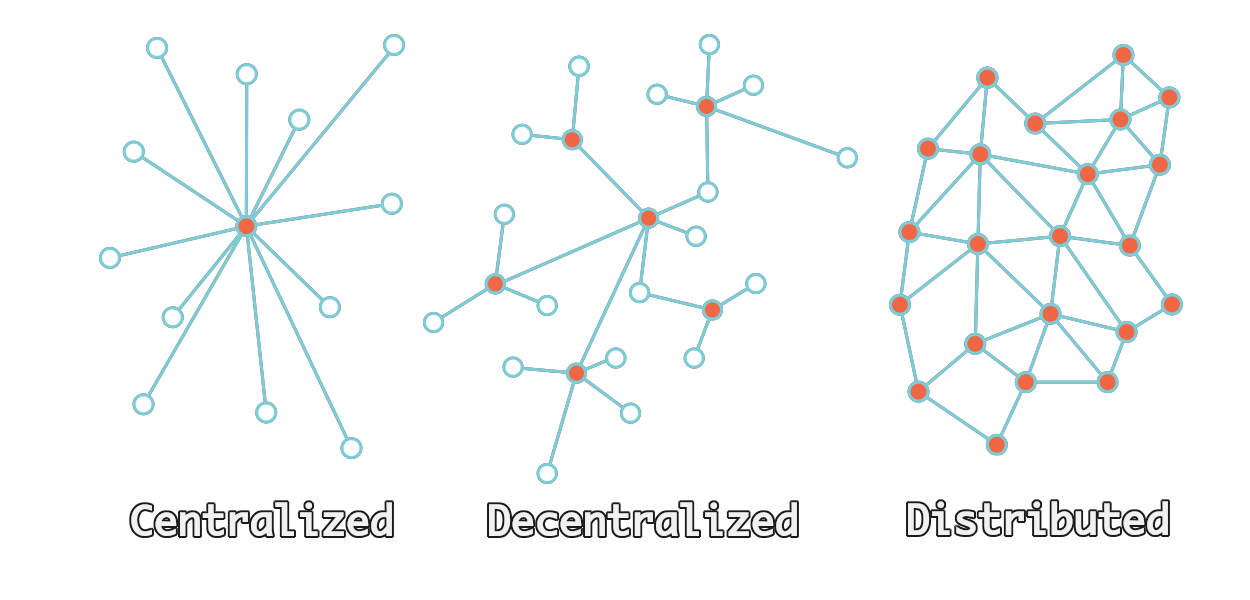
Централизованное, децентрализованное и распределенное
На изображении выше показаны 3 модели сети. Модель клиент-сервер представляет собой централизованную модель. Вот почему мы всегда говорим о центральных серверах и единых точках отказа. Вы видите центральную точку оранжевым цветом, это сервер. Тогда спицы — это клиенты, которые часто являются пользователями. На этом рисунке должно быть легко увидеть, как, если эта центральная точка когда-либо будет удалена, пользователи больше не смогут общаться друг с другом.
Децентрализованная модель — это значительное улучшение по сравнению с централизованной моделью. Он по-прежнему работает по типу клиент-сервер, когда вы получаете концентраторы, которые обслуживают пользователей, и если концентратор выходит из строя, теряется только часть сети. Хотя это хорошее улучшение, оно все же не решает всех проблем, связанных с моделью клиент-сервер. Сегодня мы видим, что эта модель используется во многих вещах, таких как ActivityPub и Matrix. Когда эти службы выходят из строя, это затрагивает только часть сообществ, которые они представляют, а не всю социальную сеть или службу чата.
В распределенной модели каждый пользователь также предоставляет часть самой сети. Если пользователь выходит из сети, сеть работает как обычно. Если основной узел выходит из строя, сеть все еще может функционировать, используя локальные одноранговые узлы. Это лидер устойчивости и модель, которая продвинет нас вперед. Некоторые узлы могут быть больше других, но ни один сбой не может вывести из строя всю сеть. Давайте посмотрим, как IPFS вписывается во все это, а также углубимся в саму распределенную модель.
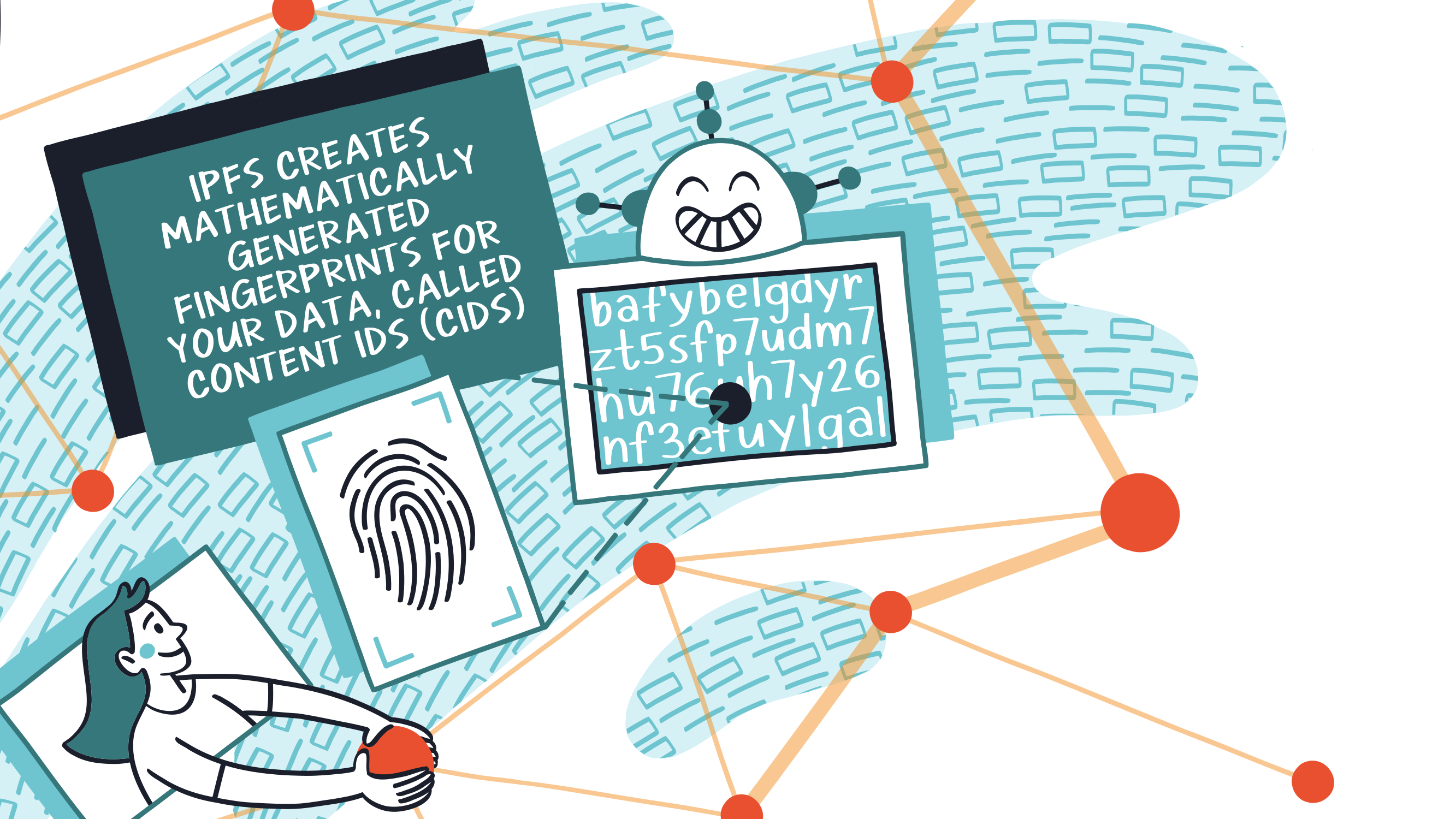
Адресация содержимого
Мы рассмотрели адресацию на основе местоположения, теперь давайте поговорим об одном из фундаментальных строительных блоков альтернативы, которая называется адресация контента. IPFS создает математически сгенерированные отпечатки пальцев для данных, называемых идентификаторами контента или сокращенно CID. Этот шаг относится к тому, что называется IPLD или межпланетными связанными данными, что является фундаментальным для того, как IPFS работает, чтобы дать нам адресацию контента, освободив нас от адресации на основе местоположения.

Состав CID
На изображении выше показана структура CID версии 1, представленная в двоичном формате. В крайнем левом углу изображения, здесь не показан многобазовый префикс. Это на самом деле опущено, потому что при работе с двоичным кодом на самом деле нет многобазового префикса, вы можете сохранить этот байт. Что делает многобазовый префикс, так это позволяет нам узнать, какая базовая кодировка использовалась для создания CID, поскольку IPLD поддерживает многие из них.
Затем у нас есть идентификатор версии, который представляет собой любой номер версии, с которой мы работаем, в данном случае мы работаем с CID версии 1.
Затем у нас есть мультикодек, dag-pb, который указывает, что этот DAG (ориентированный ациклический граф) закодирован буфером протокола. Поле мультикодека само по себе является беззнаковым вариантом. Список поддерживаемых кодеков доступен в репозитории мультиформатов github.
Далее следует мультихеширование, которое включает в себя 3 вещи: алгоритм мультихэширования, длину мультихэширования и, наконец, сам дайджест хеширования. Здесь вы можете видеть, что мы работаем с хэшем sha2 длиной 32 байта, после чего сам хеш выходит за пределы экрана. спецификация мультихэширования также доступна в многоформатном репозитории github.

Надежная проверка и сохранение
Как мы уже говорили, вам не нужно доверять тому, кто отправляет вам данные, поскольку вы можете запустить хэш-функцию CID и проверить ее самостоятельно. IPFS использует CID, либо просматривая CID в распределенной хеш-таблице (DHT), либо используя битовый обмен и спрашивая своих локальных пиров «у вас есть этот CID?». При этом больше не имеет значения, где находятся данные, поскольку мы точно знаем, чего хотим, поэтому не имеет значения, у кого они есть, важно только то, что они есть у кто-то. Теперь мы избавились от адресации на основе местоположения.
Если вы хотите поделиться веб-страницей, изображением, видео или статьей, вы знаете, что если вы отправите этот CID своему другу, он сможет загрузить ту же версию данных, которую вы видели. Если хотя бы у вашего узла или у кого-то еще есть копия, вы можете поделиться ею. Не имеет значения, удалил ли первоначальный хостер данные, важно только то, что у вас или у кого-то еще есть копия данных. Благодаря этому данные могут жить до тех пор, пока кто-то этого хочет. С помощью Filecoin вы даже можете заплатить поставщикам хранилищ, чтобы они криптографически гарантировали, что ваши данные будут жить какое-то время, может быть, даже вечно, но это погружение в другую статью.
Тем временем, если вы ищете службу для хранения ваших данных, я рекомендую проверить web3.storage , nft.storage и lighthouse.storage . Все они — помощники в хранении, которые хотят, чтобы ваши данные были доступны через IPFS и резервировались в Filecoin.
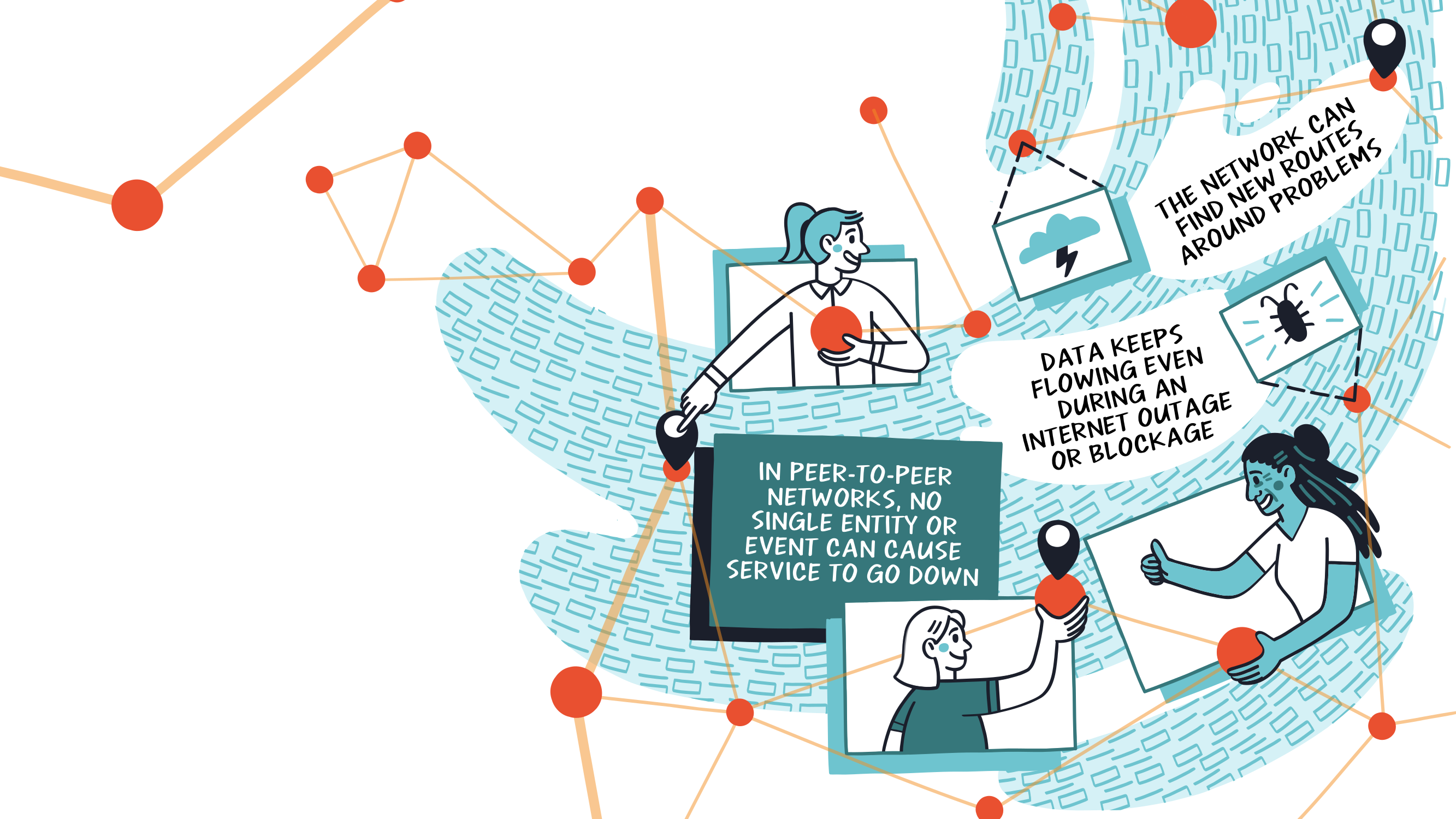
Непрекращающиеся данные & Услуги
Теперь, когда мы отказались от адресации на основе местоположения и перешли к адресации контента, что это значит для нас? Это означает, что теперь сеть может прозрачно находить новые маршруты вокруг проблем. Проблемы в этом случае могут быть сбоями, мы знаем, что если наш узел выходит из строя в течение определенного периода времени, мы в ясности, если мы получили наши данные на некоторые другие узлы. Или даже если у пользователя, работающего на узле IPFS, есть копия наших данных.
С IPFS ваш узел будет кэшировать новые данные до тех пор, пока они не будут удалены сборщиком мусора, что помогает автоматически повышать доступность связанных CID. Это может помочь при перебоях в работе Интернета в регионах и даже по всей стране, потому что, пока какой-то узел в локальной сети имеет копию данных, он все еще может обслуживаться. Более того, он показывает, как в одноранговой сети отключение одного узла не может привести к отключению всей службы.
Эти знания важны при разработке вашего приложения. Вы можете использовать шлюз, и если у вас мало времени на хакатон, это имеет смысл. Если вы действительно хотите создать отказоустойчивое одноранговое приложение web3, важно подумать о том, как добиться отказоустойчивости. Для этого вы должны использовать одноранговую природу IPFS. Когда вы полагаетесь на шлюз, особенно на один, то, если этот шлюз замедлится или выйдет из строя, все ваше приложение будет работать вместе с ним. Если вместо этого вы используете IPFS напрямую, используя его возможности одноранговой связи, то вы на пути к созданию практически бесперебойной службы.
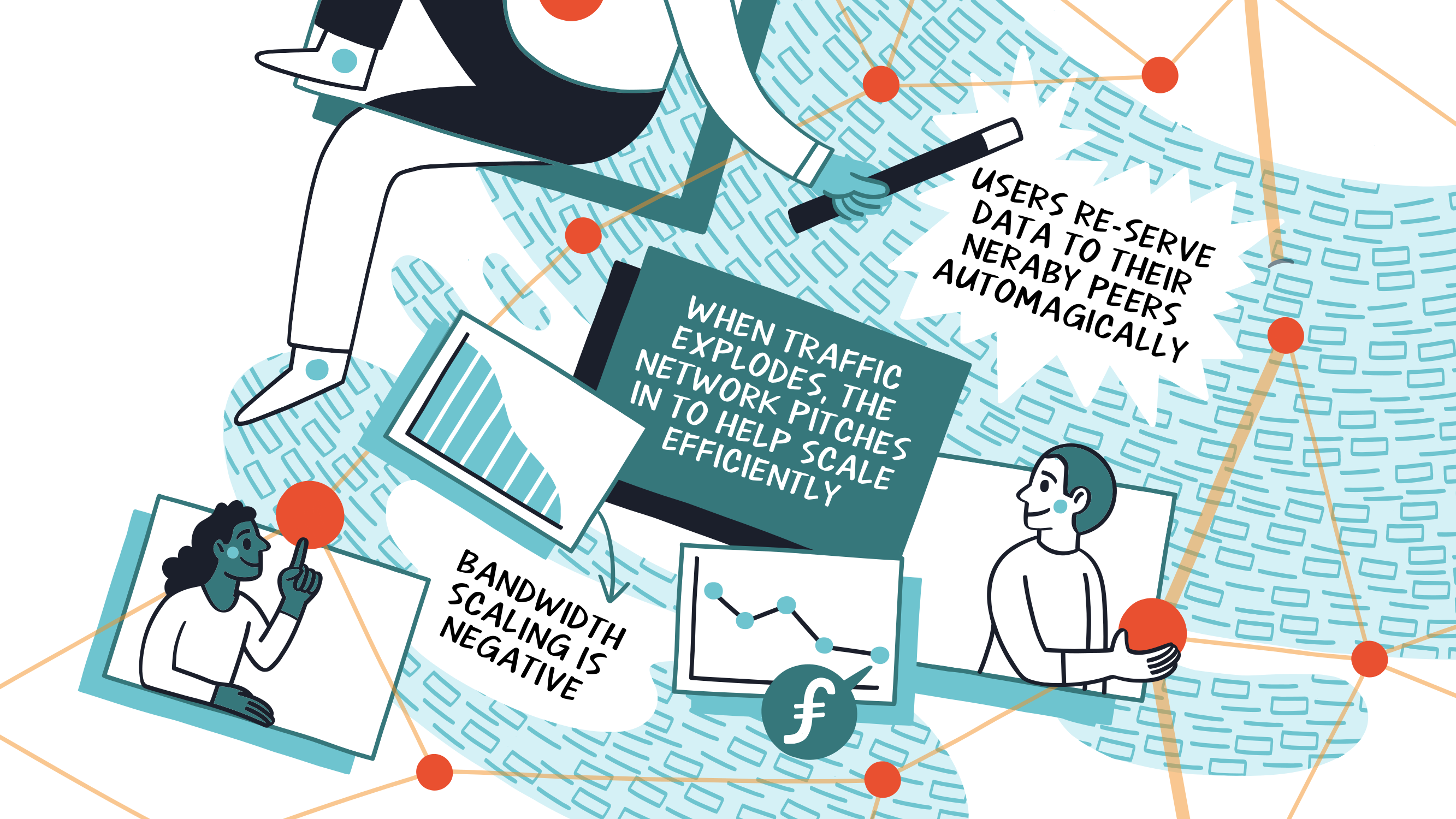
Масштабирование и расширение Межпланетный
Мы коснулись того, как пользователи IPFS помогают повторно передавать интересующие их данные ближайшим одноранговым узлам. Это происходит, когда пользователь запрашивает данные из сети через CID, его узел кэширует их, а затем делает доступными для остальной части сети. Это помогает не только обеспечить устойчивость, вы можете видеть, что сеть помогает вам эффективно масштабироваться. Подумайте о проблеме клиент-сервер, когда вы создаете популярное приложение, и ваш трафик резко возрастает. Эта ситуация фактически переворачивается с ног на голову с помощью IPFS, что приводит к отрицательным затратам на масштабирование пропускной способности.
Если несколько узлов пытаются загрузить ваш CID, они также автоматически повторно обмениваются данными. В то время как ваш трафик увеличивается от людей, запрашивающих ваш CID, эти самые люди также помогают автоматически отправлять сами данные своим друзьям или коллегам. Чем популярнее ваш CID, тем легче людям получить данные от кого-то, кто может быть ближе к ним.
Это свойство очень важно для межпланетного аспекта IPFS. Если у кого-то на Марсе есть какие-то данные, которые он изначально получил с Земли, другому пользователю Марса не придется ждать, чтобы получить те же данные с Земли. Сеть должна автоматически определить, что на Марсе есть другой узел, готовый предоставить эти данные. Адресация контента и распределенная сеть помогают нам открыть такое будущее на сетевом уровне, прозрачно.
Заключение
Технологии Web3, такие как IPFS, помогают нам выйти из мира централизации. Это дает больше возможностей потребителю и меньше компаниям, желающим получить вашу личную информацию. IPFS также помогает нам повысить отказоустойчивость и функциональную совместимость наших данных благодаря надежной распределенной структуре.
Если вы хотите узнать больше, ниже приведены несколько ссылок о том, как начать использовать IPFS для новых пользователей и для разработчиков, желающих глубже изучить эту технологию.
Ссылки
Начало работы
- Настольный компьютер IPFS
- Компаньон IPFS (дополнение для браузера)
Учебные ресурсы
- Начало работы с IPFS & Файлкойн
- Документы IPFS
- Ресурсы сообщества IPFS (Discord, форумы и т. д.)
Видео
- Отказ от модели клиент-сервер (полная версия, онлайн)
- Отказ от модели клиент-сервер (сокращенная версия)
- Введение в IPFS & Файлкойн
Примеры использования
Другие ресурсы
Впервые опубликовано по адресу: https://blog.ipfs.tech/ipfs-breaking-free- клиент-сервер/