

Артистизм эффективных разговоров с ИИ
16 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 терминология
3 Изучение пространства дизайна моделей на языке зрения и 3.1. Все ли предварительно обученные основы эквивалентны VLMS?
3.2 Как полностью ауторегрессивная архитектура сравнивается с архитектурой перекрестного активации?
3.3 Где повышение эффективности?
3.4 Как можно вычислить торговлю на производительность?
4 IDEFICS2-открытая современная модель Фонда зрения и 4.1 многоэтапное предварительное обучение
4.2 Инструкция тонкая настройка и 4.3 оптимизация для сценариев чата
5 Заключение, подтверждение и ссылки
Приложение
A.1 Дальнейшие экспериментальные детали абляций
A.2 Детали инструкции тонкая настройка
A.3 Детали оценок
A.4 Красная команда
3.2 Как полностью ауторегрессивная архитектура сравнивается с архитектурой перекрестного активации?
Насколько нам известно, не существует надлежащего сравнения между полностью авторегрессивным и перекрестной архитектурой. Мы стремимся заполнить этот пробел, рассмотрев их компромиссы, а именно производительность, количество параметров и стоимость вывода.
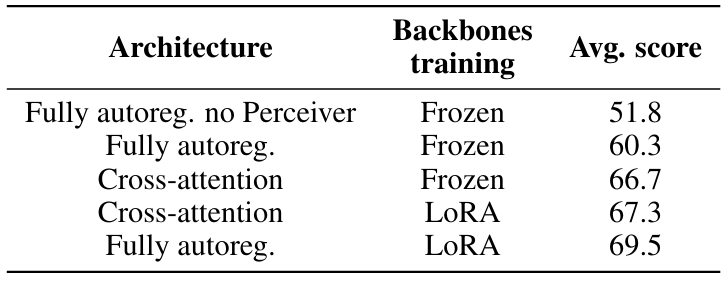
Следуя (Alayrac et al., 2022), мы сначала сравниваем две архитектуры, замораживая унимодальные магистрали и обучая только недавно инициализированные параметры (перекрестное привлечение с одной стороны и проекция модальности вместе с изученным пулом на другой стороне), одновременно исправляя количество учебных данных. Alayrac et al. (2022) показывает, что чем чаще блоки перекрестного привязанности чередуются с языковыми модельными слоями, а тем выше производительность языка зрений. Таким образом, мы отмечаем, что в соответствии с этой настройкой архитектура перекрестного активации имеет на 1,3B больше обучаемых параметров (всего 2B-тренировочных параметров), чем полностью авторегрессивная архитектура. Кроме того, во время вывода первый использует на 10% больше провалов, чем последняя. В этих условиях мы отмечаем, что архитектура перекрестного сопротивления выполняет 7 баллов лучше в таблице 3.
Из общего количества параметров, приблизительно 15% для полностью авторегрессивной архитектуры и 25% для перекрестного привлечения обучаются. Мы предполагаем, что эта низкая доля ограничивает экспрессивность обучения и препятствует производительности. Чтобы проверить эту гипотезу, мы сравниваем две архитектуры, размогая все параметры (вновь инициализированные параметры и параметры предварительно обученных унимодальных магистралей). В этих условиях обучение полностью авторегрессивной архитектуре принесет расхождения потерь, и мы не были успешными в стабилизации обучения даже путем агрессивного снижения уровня обучения или постепенно разведывательного разведывания различных компонентов. Чтобы преодолеть эту проблему стабильности, мы используем адаптацию с низким уровнем ранга (Hu et al., 2022) для адаптации предварительно обученных параметров при использовании стандартной полной настройки для вновь инициализированных.
Эта настройка дает значительно больше стабильных тренингов, и, что более важно, мы наблюдаем увеличение на 12,9 балла под полностью авторегрессивной архитектурой и 0,6 балла под архитектурой перекрестного привлечения. В то время как архитектура по перекрестному взаимодействию работает лучше, чем полностью авторегрессивная архитектура с замороженными магистралью, это хуже, когда мы добавляем степени свободы для предварительно обученных основополагающих. Кроме того, использование LORA позволяет обучать унимодальные магистрали на долю от стоимости памяти GPU полной настройки, а слои LORA могут быть объединены обратно в исходные линейные слои, не давая дополнительных затрат при выводе. Поэтому мы выбираем полностью авторегрессивную архитектуру в остальной части этой работы.
Интересно отметить, что это открытие противоречит (Karamcheti et al., 2024), в котором авторы наблюдали, что разведывающие предварительно обученную визуальную основу значительно ухудшат производительность. Мы предполагаем, что использование эффективных методов точной настройки параметров является ключевым отличием.

3.3 Где повышение эффективности?
Количество визуальных токеновНедавние VLMS обычно направляют всю последовательность скрытых состояний кодера видения непосредственно в проекционный слой модальности, который впоследствии вводит в языковую модель, без пула. Это мотивировано предыдущими работами, в которых было обнаружено, что добавление стратегии объединения, например, среднее объединение, ухудшает производительность (Vallaeys et al., 2024). Это приводит к большому количеству визуальных токенов для каждого изображения в диапазоне от 576 для DeepSeek-VL (Lu et al., 2024) до 2890 для Sphinx-2K (Lin et al., 2023). Благодаря полученной длине последовательности обучение является вычислительно дорогостоящим, а в контекстном контексте обучение с чередующимися изображениями и текстами является сложной задачей, потому что оно требует модификаций языковых моделей для обработки очень больших контекстов.
Мы уменьшаем длину последовательности скрытых состояний каждого изображения, используя воспринимающий Resampler (Jaegle et al., 2021; Alayrac et al., 2022; Bai et al., 2023) в качестве формы обучения пулу на основе трансформаторов. Количество запросов (также называемых скрытыми) соответствует количеству полученных визуальных токенов после объединения. Мы наблюдаем, что ученый пул эффективен двумя способами: он увеличивает производительность на 8,5 баллов в среднем и уменьшает количество визуальных токенов, необходимых для каждого изображения с 729 до 64 (см. Таблицу 3).
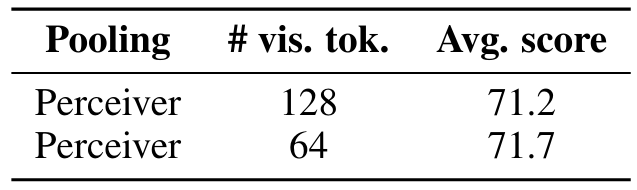
В отличие от (Vallaeys et al., 2024; McKinzie et al., 2024), которые обнаруживают, что чем больше визуальных токенов, тем выше производительность, мы не наблюдаем прибыли при использовании более 64 визуальных токенов. Мы предполагаем, что в гипотетическом сценарии бесконечного обучения по неограниченным данным производительность может в конечном итоге улучшиться за счет более длительного обучения. Другие вариации по сравнению с архитектурой восприятия (Mañas et al., 2023; Darcet et al., 2024; Vallaeys et al., 2024) привели к снижению производительности.

Сохранение исходного соотношения сторон и разрешения изображенияКодеры зрения, такие как сиглип, обычно обучаются на квадратных изображениях фиксированного размера. Изменение размера изображений изменяет их исходное соотношение сторон, что является проблематичным, например, для задач, требующих чтения длинных текстов. Кроме того, кондиционирование обучения по размеру одного разрешения по своей сути вводит ограничения: низкое разрешение пропускает важные визуальные детали, в то время как высокое разрешение приводит к неэффективности в обучении и выводе. Разрешение модели кодировать изображения в различных разрешениях позволяет пользователям решать, сколько вычислений тратится на каждое изображение.
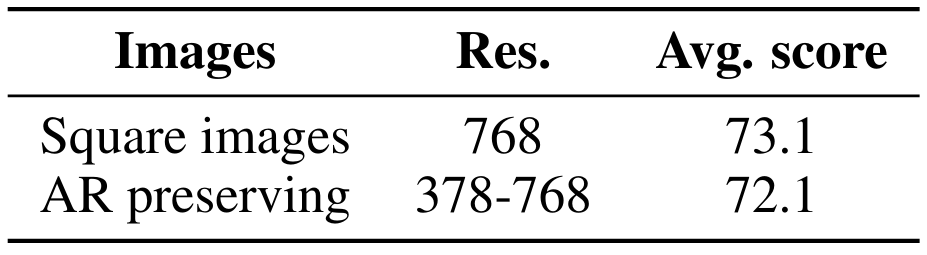
После Ли и соавт. (2023); Dehghani et al. (2023), мы передаем патчи изображения в энкодер видения, не изменяя размер изображения и не изменяя его соотношение сторон. Учитывая, что Siglip был обучен квадратным изображениям с низким разрешением с фиксированным размером, мы интерполируем предварительно обученные позиционные встраивания, чтобы обеспечить более высокое разрешение и обучать кодер зрения с параметрами LORA для адаптации к этим модификациям. [2] Наши результаты показывают, что стратегия сохранения соотношений сторон поддерживает уровни эффективности в нижестоящих задачах, одновременно разблокируя вычислительную гибкость как во время обучения, так и при выводе (см. Таблицу 5). В частности, отсутствие необходимости изменения размера изображений до того же высокого разрешения позволяет сохранять память GPU и обрабатывать изображения в разрешении, которое им требуется.

3.4 Как можно вычислить торговлю на производительность?
(Lin et al., 2023; Li et al., 2024; Liu et al., 2024; McKinzie et al., 2024) показывают, что разделение изображения на подмозаемы позволяет повысить производительность нисходящих по течению без изменений в подписи модели. Изображение разлагается на подметки (например, 4 равных подмозаемых), которые затем объединяются с исходным изображением, чтобы сформировать последовательность из 5 изображений. Кроме того, суб-изображения изменяются до размера исходного изображения. Эта стратегия, однако, поступает за счет гораздо более высокого количества токенов, чтобы кодировать изображения.
Мы принимаем эту стратегию на этапе точной настройки обучения. Каждое отдельное изображение становится списком из 5 изображений: 4 культуры и исходное изображение. Таким образом, при выводе модель способна иметь дело с автономными изображениями (64 визуальных токенов на изображение), а также искусственно дополненные изображения (320 визуальных токенов по общему мнению на изображение). Мы замечаем, что эта стратегия особенно полезна для тестов, таких как TextVQA и DocVQA, которые требуют достаточно высокого разрешения для извлечения текста в изображение (см. Таблицу 9).
Более того, когда мы применяем плюты изображения только на 50% обучающих образцов (вместо 100% образцов), мы наблюдаем, что он не ухудшает повышение производительности, которое обеспечивает разделение изображения. Удивительно, но мы обнаруживаем во время оценки, что увеличение разрешения суб-изображений (и автономного изображения) обеспечивает лишь незначительное повышение производительности по сравнению с улучшением, полученным в результате расщепления единственного изображения: 73,6% при увеличении разрешения подметок до максимальной точности 73,0% на нашем наборе валидации в течение 72,7 против 72.9.

Авторы:
(1) Хьюго Лоренсон, обнимающееся лицо и Sorbonne Université, (порядок был выбран случайным образом);
(2) Léo Tronchon, обнимающее лицо (порядок был выбран случайным образом);
(3) шнур Matthieu, Sorbonne Université;
(4) Виктор Сан, обнимающееся лицо.
Эта статья есть
[2] Поскольку сиглип обучается с фиксированным разрешением, позиционные встраивания могут интерпретироваться как абсолютные или относительные положения. С соотношением сторон и сохранением разрешения эти позиции становятся относительными позиционными встраиваниями.
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)