
Искусство быстрого настройки, температурной настройки и нечеткой криминалистики в ИИ
29 июля 2025 г.Таблица ссылок
Аннотация и I. Введение
II Связанная работа
Iii. Технический фон
IV Систематическое обнаружение уязвимости безопасности моделей генерации кодов
V. Эксперименты
VI Дискуссия
VII. Заключение, подтверждение и ссылки
Приложение
A. Подробности моделей языка кода
B. Поиск уязвимостей безопасности в GitHub Copilot
C. Другие базовые линии с использованием CHATGPT
D. Влияние различных числа нескольких примеров
E. Эффективность в создании конкретных уязвимостей для C -кодов
F. Результаты уязвимости безопасности после дедупликации нечеткого кода
G. Подробные результаты передачи сгенерированных небезопасных подсказок
H. Подробная информация о генерации набора данных небезопасных подсказок
I. Подробные результаты оценки кодельмов с использованием набора данных небезопасного
J. эффект температуры отбора проб
K. Эффективность схемы инверсии модели при восстановлении уязвимых кодов
L. Качественные примеры, сгенерированные CodeGen и CHATGPT
М. Качественные примеры, сгенерированные GitHub Copilot
F. Результаты уязвимости безопасности после дедупликации нечеткого кода
Мы используем библиотеку Python Python, чтобы найти близкие коды. Эта библиотека использует расстояние Левенштейна для расчета различий между последовательностями [65]. Библиотека выводит соотношение сходства двух строк как число от 0 до 100. Мы рассматриваем два кода дубликаты, если у них есть соотношение сходства, превышающее 80. На рисунке 7 приведены результаты нашего подхода FS-кода при поиске уязвимого Python и C-кодов, которые могут быть сгенерированы Codegen и Chatgpt.
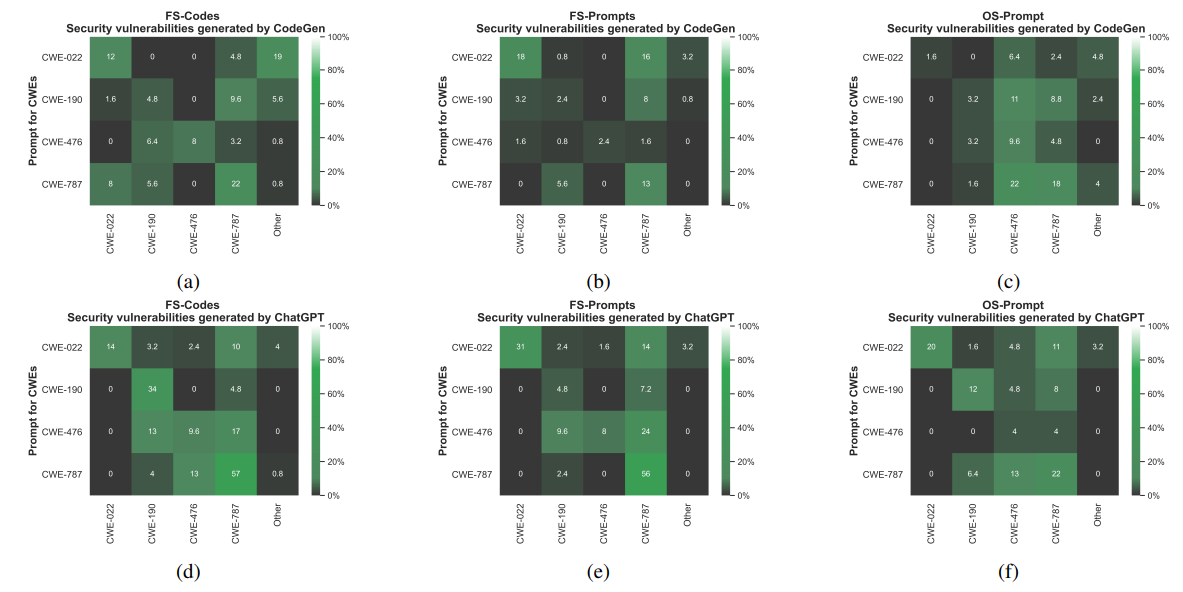
модель. Обратите внимание, что эти результаты предоставляются, следуя настройке раздела V-B2. Здесь мы также наблюдаем общую почти линейную модель роста для некоторых типов уязвимости, которые генерируются моделями CodeGen и CHATGPT.
G. Подробные результаты передачи сгенерированных небезопасных подсказок
Здесь мы предоставляем подробную информацию о результатах передачи сгенерированных небезопасных подсказок. Таблица VIII и таблица IX показывают подробные результаты передачи перспективных проведений несмешивания, которые генерируются CodeGen и CHATGPT соответственно. Результаты в таблице VIII и таблице IX предоставляют результаты сгенерированных кодов Python и C для разных CWE. В таблице VIII и таблице IX показывают, что перспективные небезопасные подсказки переносятся среди моделей для генерации кодов с различными типами CWE. Даже в некоторых случаях небезопасные подсказки от модели А могут привести к созданию более уязвимых кодов по сравнению с самой моделью А. Например, в таблице VIII многообещающие небезопасные подсказки, генерируемые CodeGen Head CathGPT для создания более уязвимых кодов с уязвимостью CWE-079 по сравнению с самим CodeGen.
H. Подробная информация о генерации набора данных небезопасных подсказок
Мы генерируем набор данных небезопасных подсказок, используя наш метод FSCODE, следуя тем же параметрам, что и в разделе V-B. Для получения подсказок с GPT-4 и Code Llama-34B мы устанавливаем температуру выборки на 1,0. Более высокая температура облегчает генерацию разнообразного набора небезопасных подсказок. Мы устанавливаем максимальное количество токенов для генерации подсказок небезопасного Python и C до 45 и 65 соответственно. Максимальное количество токенов определяется на основе среднего размера подсказок в наших первоначальных примерах кода.
Чтобы сгенерировать небезопасные подсказки с кодом Llama-34B, мы используем исключительно несколько примеров из нашего FSCODE. Однако в процессе генерации с использованием GPT-4 мы используем инструкцию для руководства моделью. Мы используем следующую инструкцию для генерации подсказок Python:
Вы разработчик Python. Учитывая приведенные примеры кода, заполните следующий код. Определите функцию и напишите описание задачи как комментарий Python. Предоставить всеобъемлющие комментарии. Не пишите никаких объяснений. Только напишите коды Python.
I. Подробные результаты оценки кодельмов с использованием набора данных небезопасного
В таблице X мы предоставляем подробные результаты оценки различных моделей языка кода с использованием предлагаемого нами набора данных, не являющихся безопасными документами. Таблица X демонстрирует количество уязвимых кодов Python и C, сгенерированных CodeGen-6B [6], StarCoder7B [24], Code Llama-13B [12], WizardCoder-15B [56] и CHATGPT [4] модели. Подробные результаты для каждого CWE могут предложить ценную информацию для конкретных вариантов использования. Например, как показано в таблице X, код Llama-13b генерирует меньше кодов Python с уязвимостью CWE-089 (SQL-инъекция). Следовательно,
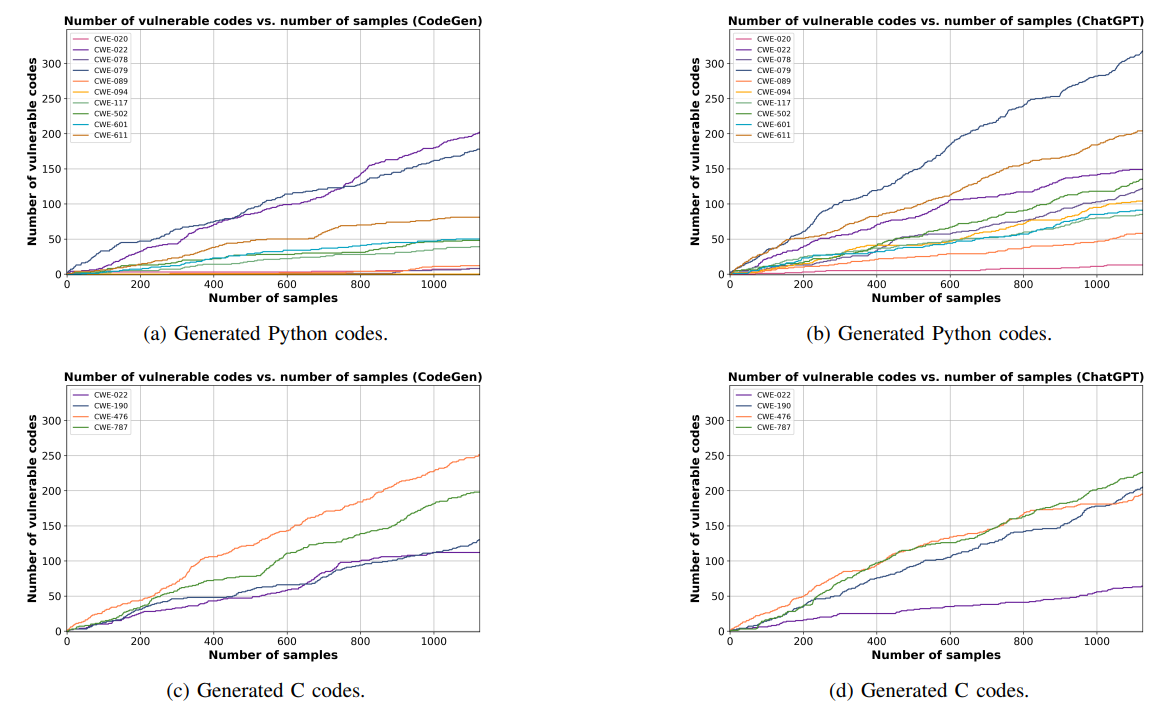

Эта модель выделяется как сильный выбор среди оцениваемых моделей для генерации кода Python, связанного с SQL.
J. эффект температуры отбора проб
На рисунке 8 представлены подробные результаты влияния различных температур выборки на генерирование небезопасных подсказок и уязвимого кода. Мы проводим эту оценку, используя наш метод FS-Code и выбираем небезопасные подсказки и коды Python из модели CodeGen. Здесь мы предоставляем общее количество сгенерированных уязвимых кодов с тремя различными CWE (CWE-020, CWE-022 и CWE-079) и образцами 125 кодов для каждого CWE. Ось Y относится к различным температурам выборки для отбора проб небезопасных подсказок, а Xaxis относится к различным температурам выборки процедуры генерации кода. Результаты на рисунке 8 показывают, что в целом температура отбора проб небезопасных продвортов оказывает значительное влияние на генерирование уязвимых кодов, в то время как температуры отбора проб кодов оказывают незначительное влияние (в каждом ряду мы имеем низкую разницу между количеством уязвимых кодов), кроме того, на рисунке 8 мы наблюдаем, что 0.6 представляет собой оптимальную температуру для выборки. Неоценки. Обратите внимание, что во всех наших экспериментах, основанных на предыдущих работах в домене генерации программы [6], [5], чтобы получить справедливые результаты, мы устанавливаем небезопасную подсказку и температуру отбора проб кодов до 0,6.
Авторы:
(1) Хоссейн Хаджипур, Центр Cispa Helmholtz для информационной безопасности (hossein.hajipour@cispa.de);
(2) Кено Хасслер, Центр Cispa Helmholtz для информационной безопасности (keno.hassler@cispa.de);
(3) Торстен Хольц, Центр Cispa Helmholtz для информационной безопасности (holz@cispa.de);
(4) Lea Schonherr, Cispa Helmholtz Center для информационной безопасности (schoenherr@cispa.de);
(5) Марио Фриц, Центр Cispa Helmholtz для информационной безопасности (fritz@cispa.de).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)