
Потолок согласования: объективное несоответствие в обучении с подкреплением на основе обратной связи с людьми
17 января 2024 г.:::информация Авторы:
(1) Натан Ламберт, Институт искусственного интеллекта Аллена;
(2) Роберто Каландра, Технический университет Дрездена.
:::
Таблица ссылок
Понимание несоответствия целей
АННОТАЦИЯ
Обучение с подкреплением на основе обратной связи с человеком (RLHF) стало мощным методом, позволяющим сделать большие языковые модели (LLM) более простыми в использовании и более эффективными в сложных условиях. По своей сути RLHF предоставляет новый набор инструментов для оптимизации LLM, помимо прогнозирования следующего токена, что позволяет интегрировать качественные цели обучения. Попытка сопоставления между предпочтениями пользователя и производительностью последующих этапов, которая происходит в модели изученного вознаграждения, приводит к созданию среды оптимизации, в которой метрики обучения и оценки могут оказаться коррелирующими. Очевидная корреляция может привести к неожиданному поведению и историям о «слишком большом количестве RLHF». В RLHF проблемы возникают из-за того, что следующие подмодули не согласуются друг с другом: обучение модели вознаграждения, обучение модели политики и оценка модели политики. Это несоответствие приводит к тому, что модели иногда избегают запросов пользователей с помощью ложных флажков безопасности, их трудно направить на заданные характеристики или они всегда отвечают в определенном стиле. Поскольку оценка модели чата становится все более детализированной, зависимость от предполагаемой связи между оценкой модели вознаграждения и производительностью последующего процесса приводит к проблеме объективного несоответствия. В этой статье мы иллюстрируем причину этой проблемы, просматривая соответствующую литературу по обучению с подкреплением на основе моделей, и обсуждаем соответствующие решения, чтобы стимулировать дальнейшие исследования. Устранив несоответствие целей в RLHF, LLM будущего будут более точно соответствовать инструкциям пользователя с точки зрения безопасности и полезности.
1 Введение
Обучение с подкреплением на основе обратной связи между людьми (RLHF) — это мощный инструмент для интеграции качественных стилей и ценностей в большие модели машинного обучения (Бай и др., 2022; Кристиано и др., 2017; Оуян и др., 2022). RLHF стал популяризирован благодаря его использованию для интеграции человеческих ценностей в большие языковые модели (LLM) для согласования инструментов чата (Шульман, Зоф, Ким и другие, 2022). При этом RLHF стала важным методом в процессе улучшения моделей, лучше реагирующих на запросы пользователей, часто называемых «настраиваемыми инструкциями», «управляемыми», «чат-моделями» и т. д. Методы RLHF обычно работают в двухэтапном процессе после При обучении модели базового языка сначала они изучают модель человеческих предпочтений, которая действует как функция вознаграждения, а затем используют эту модель в цикле оптимизации обучения с подкреплением (RL). В процессе RLHF эти два шага часто выполняются независимо, при этом точная модель вознаграждения обучается на данных о предпочтениях человека, а затем используется оптимизатор RL для извлечения максимальной информации в модель чата. Общей проблемой современных LLM, обучающихся с помощью RLHF, являются трудности с извлечением предполагаемого поведения из модели. Иногда модели отклоняют безобидные запросы по соображениям безопасности, а иногда им требуется оперативная настройка для достижения полной производительности.
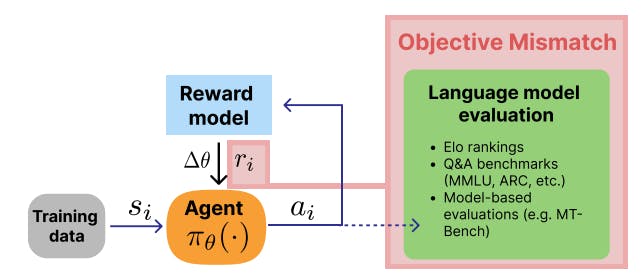
В этой статье мы подробно описываем фундаментальную проблему современных схем обучения RLHF: проблему объективного несоответствия. В RLHF три важные части обучения численно разделены: разработка показателей оценки, обучение модели вознаграждения и обучение генерирующей модели. Это несоответствие между моделью вознаграждения и обучением RL показано на рис. 1, однако существуют и другие связи между целями оценки и моделированием человеческих ценностей. В частности, существует множество способов лучше согласовать обучение модели вознаграждения с литературой по количественной оценке предпочтений (Ламберт, Гилберт и Зик, 2023), и в практиках RLHF необходимо решить фундаментальные проблемы оптимизации (Casper et al., 2023). ChatGPT, самая популярная модель, обученная с помощью RLHF, демонстрирует признаки этого ограничения через такие проблемы, как многословие, неуверенность в себе и отказ от вопросов, повторяющиеся фразы, хеджирование и многое другое (Шульман, 2023). Эти черты чрезмерной оптимизации являются результатом тонкой прокси-целевой проблемы, которую несоответствие целей обеспечивает основу для изучения и решения: модель вознаграждения приписывает избыточную ценность фразам, которые не приносят пользу пользователю, что и использует оптимизатор RL, например, флажки безопасности. С другой стороны, нынешние схемы обучения не полностью соответствуют инструментам оценки, поскольку модели RLHF по-прежнему нуждаются в сложных методах подсказок, таких как «думать шаг за шагом» (J. Wei et al., 2022) или «сделать глубокий вдох». (Янг и др., 2023) для достижения максимальной производительности. Устранение несоответствия целей устранит необходимость в этих передовых методах и снизит вероятность отказа в получении степени LLM за пределами объема работ.
Фраза «целевое несоответствие» возникла из обучения с подкреплением на основе моделей (MBRL), когда агент итеративно изучает динамическую модель, которую он позже использует для решения задачи управления (Ламберт, Амос, Ядан и Каландра, 2020; Р. Вэй, Ламберт , Макдональд, Гарсия и Каландра, 2023). В этом контексте несоответствие заключается в изучении точной динамической модели, а не модели, оптимизированной для высокого вознаграждения за выполнение задания. В RLHF проблема аналогична, но с дополнительной сложностью, поскольку модель вознаграждения оптимизирована для данных о предпочтениях, а не для закрытого распределения, которое не соответствует конечным пользователям. Во-вторых, задача создания открытого языка менее специфична для понятия вознаграждения, чем задача политики контроля RL. По этим причинам, как мы исследуем в этой статье, проблема объективного несоответствия является более тонкой и критичной для RLHF.
В этом позиционном документе мы вносим три вклада:
• Четко объясняйте причины и потенциальные проявления несоответствия целей в LLM, настроенных в чате.
• Объедините соответствующие работы из литературы по НЛП и RL вокруг несоответствия целей.
• Предложить направления исследований, чтобы устранить несоответствие и способствовать улучшению практики RLHF.
:::информация Этот документ доступен на arxiv по лицензии CC 4.0.
:::
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)