

Строительный блок ИИ, о котором вы никогда не слышали (но используйте каждый день)
20 августа 2025 г.Системы на основе искусственного интеллекта - это разговоры о городе, а процессы и системы, помогающие ИИ, создаются как никогда раньше. Хотя создание таких систем включает в себя многочисленные сложности, одна вещь, которая лежит на основе, - это крупные языковые модели. В этой статье мы будем обсуждать один ключевой аспект LLMS, который является представлением предложения.
Формально мы можем определить представления предложения как плотные векторные кодировки, которые помогают нам захватить значения полных предложений. Они отличаются от встроенных слов тем, что помогают нам понять и моделировать семантику, синтаксис и контекст всего предложения. Эта возможность помогает нам в кластеризации и классификации предложений и в их сравнении.
Сегодня мы используем ИИ для перефразирующих предложений, генерируя резюме и выполняем семантические поиски и т. Д., А представления предложения - это строительные блоки. Их способность помочь нам понять долгосрочные зависимости-это то, что движет этими LLMS и помогает нам генерировать когерентный текст. Некоторые модели, которые эффективны в представлениях о обучении предложения, включают Bert, в частности, предложение BERT.
Перед архитектурой на основе трансформатора у нас было что -то известное как сети глубокого усреднения или даны. Хотя, не доминирующая архитектура в сегодняшнем сценарии, они были решающими строительными блоками в отношении LLMS и по -прежнему оказываются ценными, где вычислительные ресурсы ограничены. Как правило, в производственных средах, где мы обеспокоены ограничениями ресурсов, мы должны применять такие методы, как перегонка знаний к моделям на основе трансформаторов, чтобы они могли быть применимыми. Однако, сделав это, мы заметили, что производительность DANS становятся сопоставимыми с ними и гораздо менее интенсивно становятся вычислительными, что делает их удобной альтернативой.
Кроме того, в таких задачах, как призыв варианта генома, которые имеют решающее значение в определении вариаций в генетической информации, мы должны проявлять максимальную веру в наши прогнозы и интерпретацию модели, становится критическим. Именно здесь такие сети, как Dans, становятся критическими, поскольку их сетевая архитектура обеспечивает прозрачность в объяснении модели. Можно определить влияние и влияние конкретного встраивания на выход.
Но когда дело доходит до понимания более длинных последовательностей и нюансов, мы наблюдали, как Дэн борется.
В таких сценариях, в которых мы хотим захватить последовательности и их зависимости, но все еще не можем позволить себе соответствовать вычислительным требованиям трансформаторов, рецидивирующие сети единиц по -прежнему являются нашим лучшим другом и часто используются в таких задачах, как прогнозирование временных рядов, распознавание речи и т. Д. Основным преимуществом GRU является их способность поддерживать свою память на различных шагах, что позволяет им собирать контекст. Однако с точки зрения интерпретации они менее прозрачны по сравнению с датами и с точки зрения эффективности, которые они лежат в середине, то есть тяжелее по сравнению с данами, но намного легче, чем трансформаторы, тем самым становясь идеальным кандидатом для поддержания баланса между производительностью и эффективностью.
Они предпочитают задачи, которые требуют сохранения порядка, таких как переводы, последовательное прогнозирование данных и т. Д. По сравнению с данами, которые более предпочтительны для задач, напоминающих структуру слов.
Чтобы быстро оценить эти две сети, давайте быстро рассмотрим, как их можно настроить.
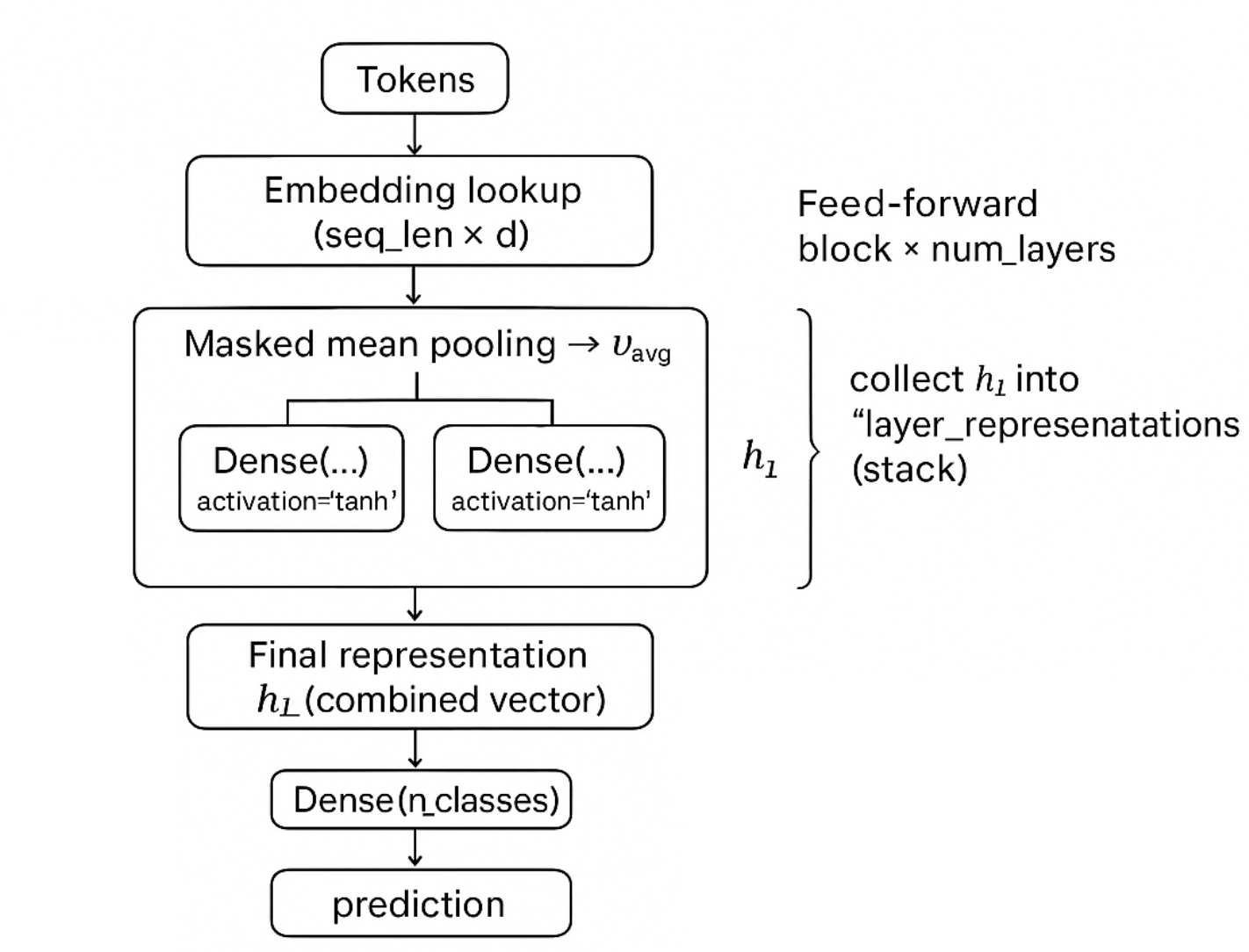
Сеть глубокого усреднения:
- Среднее значение встроения слова может быть представлено в виде вектора фиксированной длины и может быть получено с помощью функции «уменьшить_mean».
- Теперь, когда у вас есть вектор с фиксированной длиной, вы можете применить не линейные преобразования, чтобы получить выход.
- Тогда мы складываем сетей подачи вперед с нелинейной TANH. Вы можете думать об этом как о сложенной модели логистической регрессии, которая дает окончательный прогноз. Затем построите Netowrks Forward с плотными слоями и активацией = 'tanh'.
- Чтобы настроить отсечение, обновите маску последовательности с помощью соответствующих значений отсева.
- Вам нужно будет запустить петлю так же, что и num_layers.
- Для каждого цикла вы будете сохранять выходной сигнал каждого слоя и сложить их, чтобы сформировать представления слоя. Как только вы достигнете окончательного слоя, возьмите последнее состояние последнего слоя в качестве комбинированного вектора.
Одна из проблем, с которой вы можете возникнуть, заключается в том, что усреднение может уменьшить важные различия; Но если вы добавите больше преобразований, то эти различия могут быть восстановлены в последующих слоях.
Закрытые повторяющиеся единицы:
Для создания закрытых повторяющихся единиц позвольте нам понять некоторые основные отличия от длинной краткосрочной памяти. Grus не использует затвор Farge and Input, как в LSTMS, и фактически объединяет их с одним затвором обновления. Многочисленные преобразования происходят на многих слоях в GRU. Но обычно 2-3 слоя считаются хорошими, поскольку добавление большего количества слоев уменьшает результат, а также замедляет тренировку.
Мы можем использовать встроенные рамки из Tensorflow или Pytorch для реализации GRU и изменить параметр возврата к True и использовать TANH в качестве функции активации.
Чтобы сравнить вышеупомянутые с сети, мы используем определенные исследования, такие как анализ настроений.
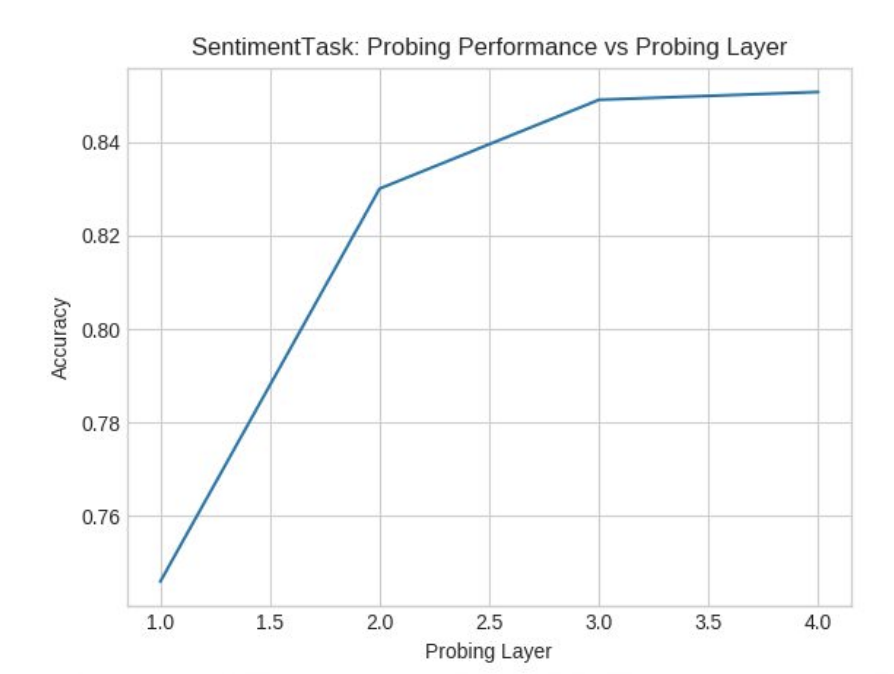
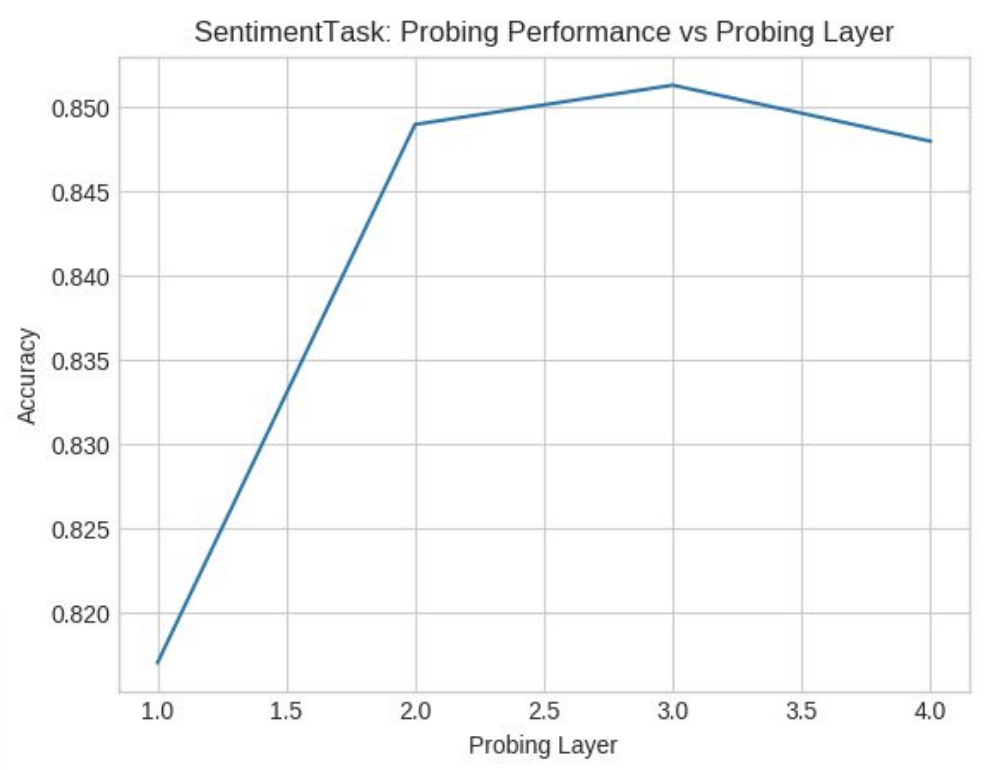
Мы не будем вдаваться в подробности набора данных, но для стандартного набора данных анализа настроений мы наблюдали, как Дан дал точность около 84,5%. Мы наблюдали, что с увеличением количества слоев в DAN точность увеличилась так, как и должна, потому что большее количество сетей прямой связи, тем больше логистической регрессии, как и действие, и улучшает производительность.
Принимая во внимание, что GRU дал точность около 85,5% точность, увеличившись с количеством слоев до 3, но затем он уменьшился, как и должно быть. Это потому, что больше слоев снижает производительность GRU.
Чтобы иметь параллельное сравнение, мы построили построение биграма и наблюдаем, что Гру работает лучше, когда он помнит упорядочение последовательностей и использует слоистые стеки.
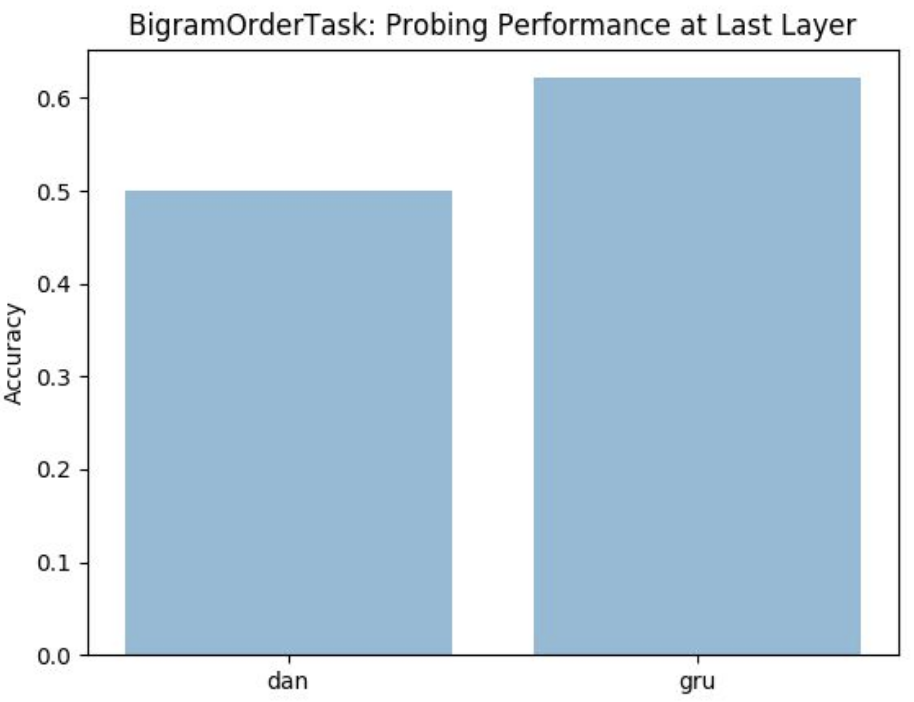
Но для более простых задач, таких как классификация бинарных настроений, мы наблюдали, как Дэн работал лучше, чем Гру, поскольку Гру не подходит для изучения простых языков, поскольку он не может выполнять несвязанный подсчет.
Если вы заинтересованы больше в анализе этих сетей, то проведение анализа возмущений может дать больше информации об этих сетях. Несмотря на то, что эти сети проще по сравнению с сегодняшними сложными LLM, но они все еще являются одними из наиболее эффективных сетей, способных поддерживать баланс между производительностью и эффективностью, а также обеспечивают прозрачную интерпретацию.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)