
ИИ текст до рейса превращает тексты в вокал, жесты и выражения лица
8 августа 2025 г.Таблица ссылок
Аннотация и 1. Введение
Связанная работа
2.1 Текст на вокальное поколение
2.2 Текст на генерацию движения
2.3 Аудио до генерации движения
Раскоростный набор данных
3.1 Рэп-вокальное подмножество
3.2 Подмножество рэп-движения
Метод
4.1 Составление проблемы
4.2 Motion VQ-VAE Tokenizer
4.3 Vocal2Unit Audio Tokenizer
4.4 Общее авторегрессивное моделирование
Эксперименты
5.1 Экспериментальная установка
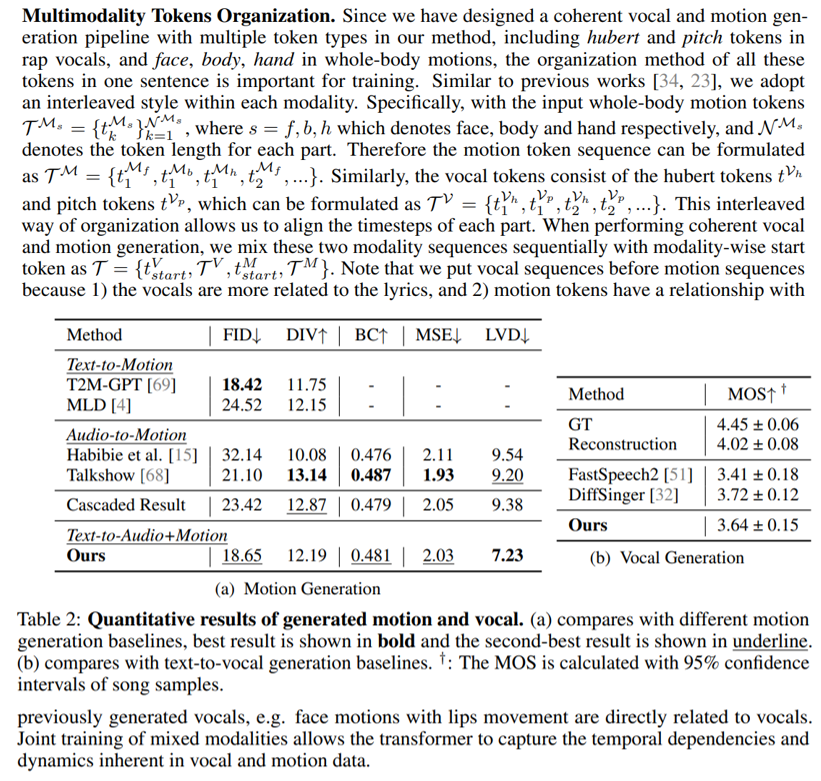
5.2 Анализ основных результатов и 5.3 исследование абляции
Заключение и ссылки
А. Приложение
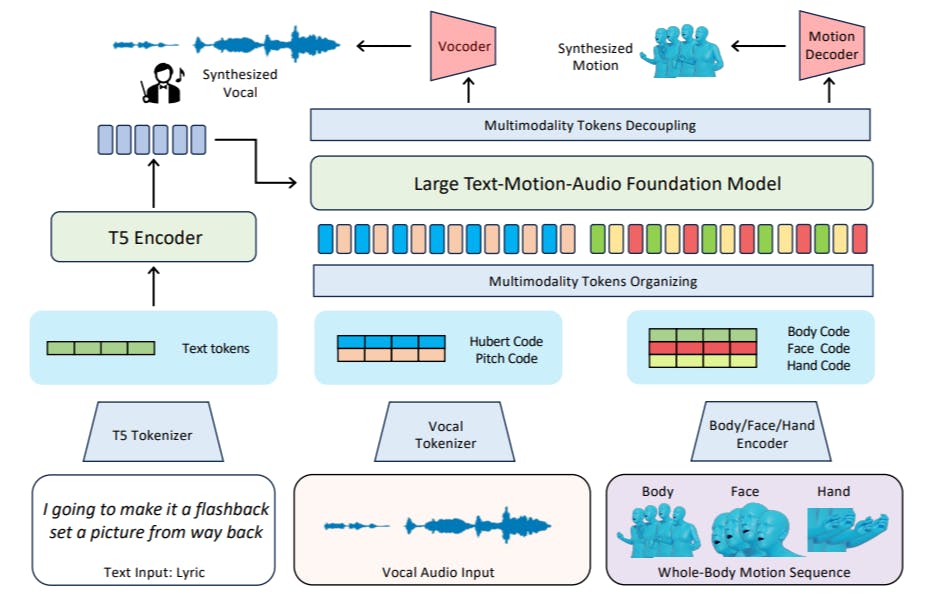
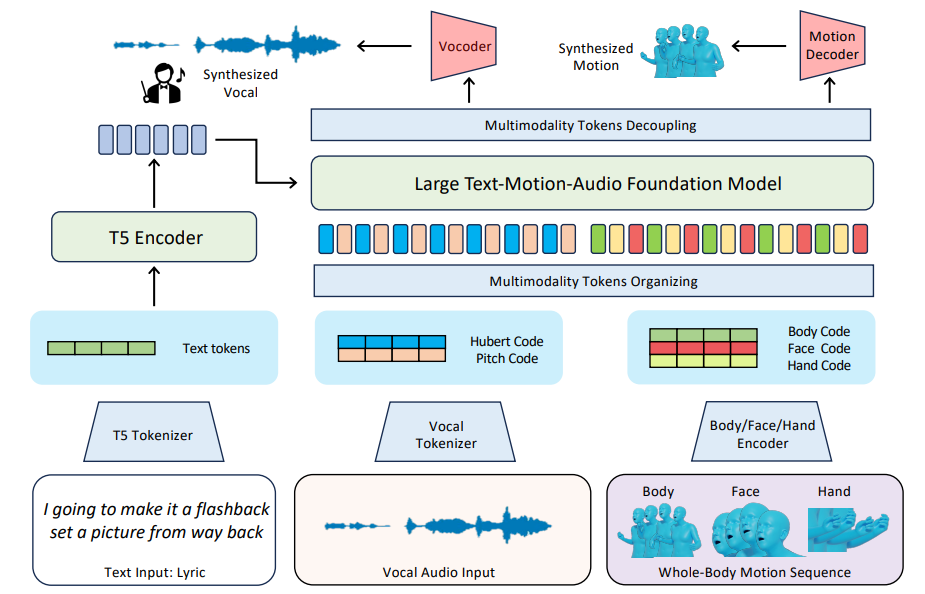
Учитывая текст текста, наша цель-генерировать вокал в стиле рэп и движения всего тела, включая движения тела, жесты рук и выражения лица, которые резонируют с текстами. С помощью нашего быстрого набора данных мы предлагаем новую структуру, которая не только представляет тексты, вокал и движения в качестве единых форм токенов, но также интегрирует моделирование токенов в унифицированную модель. Как показано на рис. 3, наша модель состоит из множества токенизаторов для движения (раздел 4.2) и вокальных (сек. 4.3) преобразования токенов, а также общую модель фонда с большой текстовой фондом-аудио (раздел 4.4), которая предназначена для синтеза звука и создания токена движения, основанной на рэп.
4.1 Составление проблемы

4.2 Motion VQ-VAE Tokenizer

4.3 Vocal2Unit Audio Tokenizer
В целом, мы используем самоотверженную структуру [45] в области речевого ресинтеза, чтобы изучить вокальные представления из аудио последовательностей. В частности, мы тренируем аудио -токенизатор Vocal2Unit, чтобы создать дискретное токеновое представление для человеческого пения. Вокальный токенизатор состоит из трех энкодеров и вокаду. Кодеры включают три разные части: (1) семантический энкодер; (2) энкодер F0; и (3) энкодер певца. Мы представим каждый компонент модели отдельно.

4.4 Общее авторегрессивное моделирование

После оптимизации с помощью этой цели обучения наша модель учится прогнозировать следующий токен, который может быть декодирован в различные функции модальности. Этот процесс похож на генерацию текстовых слов в языковых моделях, в то время как «слово» в нашем методе, например, <face_02123>, не имеет явной семантической информации, но может быть декодирована в непрерывные функции модальности.
Вывод и развязкаПолем На стадии вывода мы используем разные токены начала, чтобы указать, какой метод генерировать. Текстовый ввод кодируется как функции, направляемые к выводу в токен. Мы также принимаем алгоритм Top-K для управления разнообразием сгенерированного контента путем настройки температуры, поскольку генерирование вокала и движения, основанные на текстах, является процессом создания с несколькими возможными ответами. После прогнозирования токена алгоритм отделения используется для обработки выходных токенов, чтобы убедиться, что токены от разных методов отделяются и временно выровняются. Эти дискретные жетоны будут дополнительно расширены в вокалы и движения с выравниванием текста
Авторы:
(1) Цзябен Чен, Университет штата Массачусетс Амхерст;
(2) Синь Ян, Университет Ухана;
(3) Ихан Чен, Университет Ухан;
(4) Сиюань Сен, Университет штата Массачусетс Амхерст;
(5) Qinwei MA, Университет Цинхуа;
(6) Хаою Чжэнь, Университет Шанхай Цзяо Тонг;
(7) Каижи Цянь, MIT-IBM Watson AI Lab;
(8) ложь Лу, Dolby Laboratories;
(9) Чуан Ган, Университет штата Массачусетс Амхерст.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)