

Tencent Music переходит с ClickHouse на Apache Doris
15 марта 2023 г.Эта статья написана в соавторстве с моим коллегой Кай Даем. Мы оба инженеры платформы данных в Tencent Music (NYSE: TME), поставщике услуг потоковой передачи музыки с колоссальными 800 миллионами активных пользователей в месяц. Упомянуть здесь номер — значит не похвастаться, а намекнуть на море данных, с которыми мне и моим бедным коллегам приходится иметь дело каждый день.
Для чего мы используем ClickHouse
Музыкальная библиотека Tencent Music содержит данные всех форм и типов: записанная музыка, живая музыка, аудио, видео и т. д. Наша работа как разработчиков платформы данных состоит в том, чтобы извлекать из данных информацию, на основе которой наши товарищи по команде могут принимать лучшие решения для поддержки наших пользователей и музыкальных партнеров.
В частности, мы проводим всесторонний анализ песен, текстов, мелодий, альбомов и исполнителей, превращаем всю эту информацию в активы данных и передаем их нашим внутренним пользователям данных для подсчета запасов, профилирования пользователей, анализа показателей и группового таргетинга. .
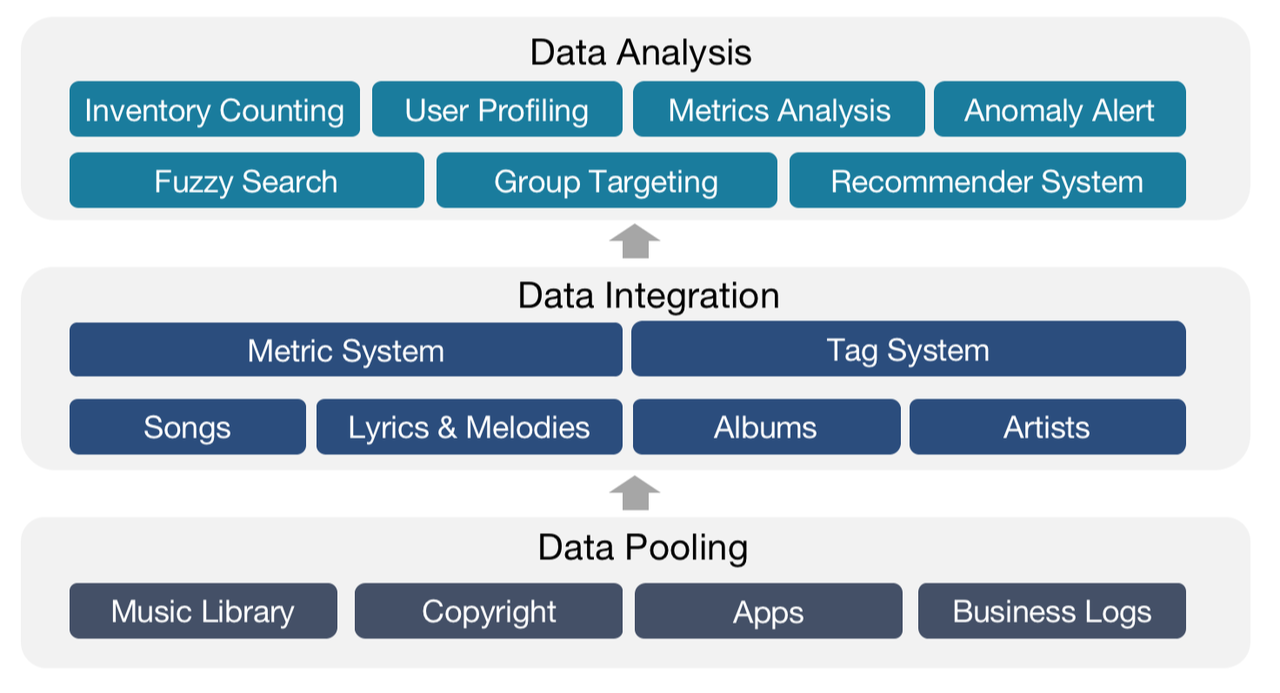
Мы хранили и обрабатывали большую часть наших данных в Tencent Data Warehouse (TDW), автономной платформе данных, где мы помещали данные в различные системы тегов и показателей, а затем создавали плоские таблицы, центрируя каждый объект (песни, исполнители и т. д.).
Затем мы импортировали плоские таблицы в ClickHouse для анализа и в Elasticsearch для поиска данных и группового таргетинга.
После этого наши аналитики данных использовали данные по нужным им тегам и метрикам для формирования наборов данных для разных сценариев использования, в ходе которых они могли создавать свои собственные теги и метрики.
Конвейер обработки данных выглядел так:
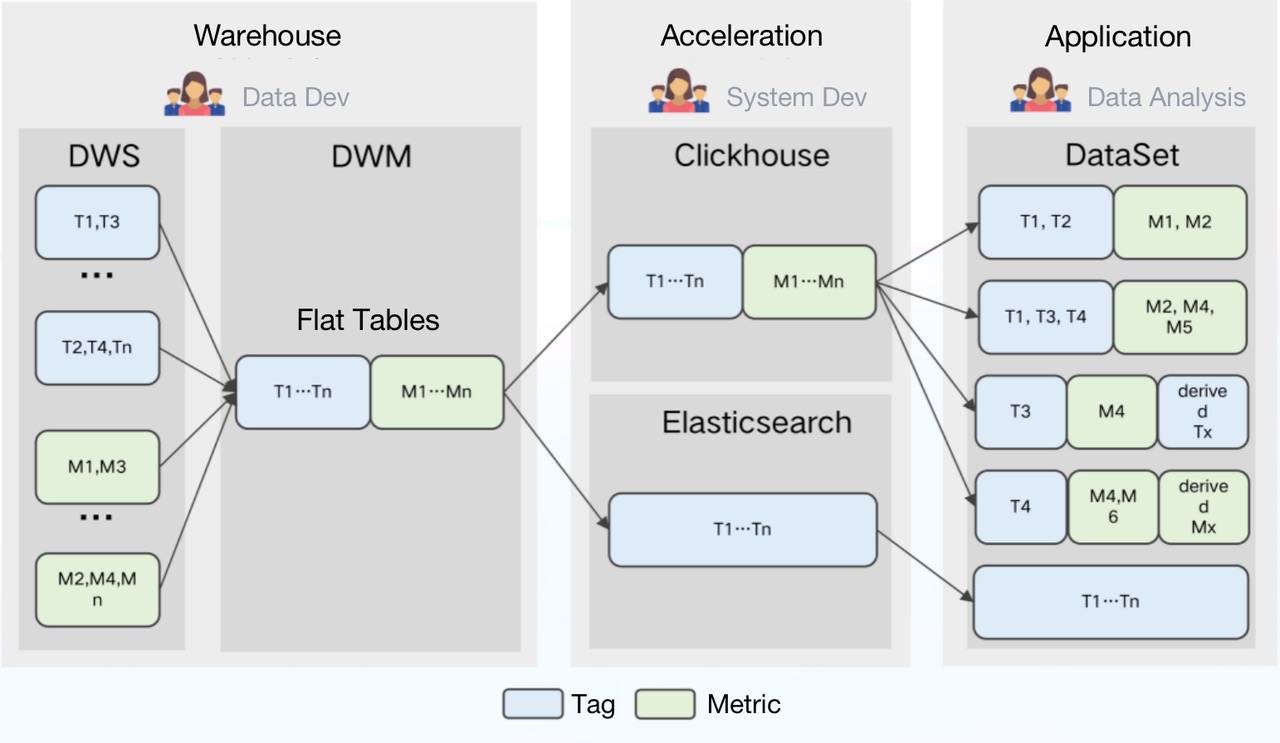
Проблемы с ClickHouse
При работе с вышеуказанным пайплайном мы столкнулись с несколькими трудностями:
- Частичное обновление: частичное обновление столбцов не поддерживалось. Таким образом, любая задержка из любого из источников данных может привести к задержке создания плоских таблиц и, таким образом, нарушить своевременность данных.
2. Высокая стоимость хранения: данные по разным тегам и показателям обновлялись с разной частотой. Несмотря на то, что ClickHouse преуспела в работе с плоскими таблицами, это была огромная трата ресурсов хранения, чтобы просто поместить все данные в плоскую таблицу и разделить ее по дням, не говоря уже о связанных с этим затратах на обслуживание.
3. Высокая стоимость обслуживания. С точки зрения архитектуры ClickHouse характеризовался сильной связью узлов хранения и вычислительных узлов. Его компоненты были сильно взаимозависимы, что увеличивало риски нестабильности кластера. Кроме того, для федеративных запросов в ClickHouse и Elasticsearch нам приходилось решать огромное количество проблем с подключением. Это было просто утомительно.
Переход на Apache Doris
Apache Doris, аналитическая база данных в режиме реального времени, может похвастаться несколькими функциями, которые нам нужны для решения наших задач:
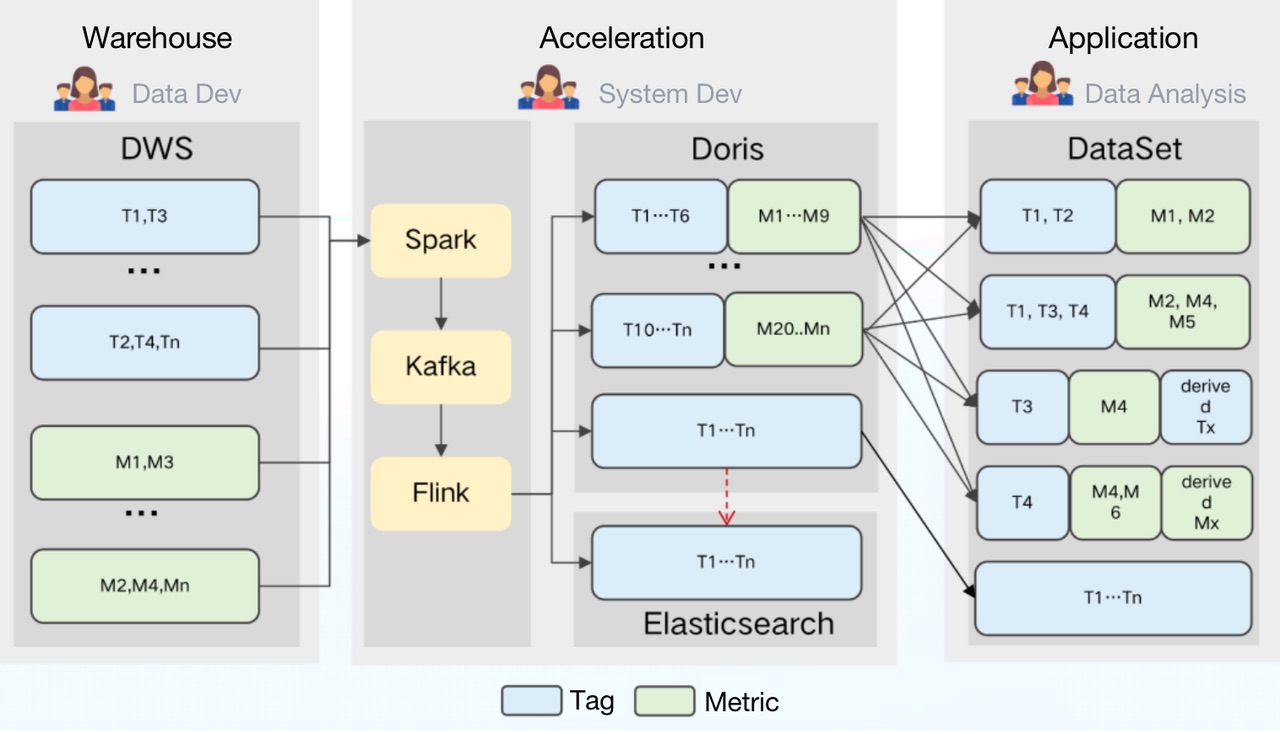
- Частичное обновление: Doris поддерживает широкий спектр моделей данных, среди которых агрегированная модель поддерживает частичное обновление столбцов в реальном времени. Опираясь на это, мы можем напрямую загружать необработанные данные в Doris и создавать там плоские таблицы. Загрузка происходит следующим образом: во-первых, мы используем Spark для загрузки данных в Kafka; затем любые добавочные данные будут обновляться в Doris и Elasticsearch через Flink. Тем временем Flink будет предварительно агрегировать данные, чтобы снять нагрузку с Дорис и Elasticsearch.
2. Стоимость хранения: Doris поддерживает запросы на объединение нескольких таблиц и федеративные запросы в Hive, Iceberg, Hudi, MySQL и Elasticsearch. Это позволяет нам разбивать большие плоские таблицы на более мелкие и разбивать их по частоте обновления. К преимуществам этого относятся снижение нагрузки на хранилище и увеличение пропускной способности запросов.
3. Стоимость обслуживания: Doris имеет простую архитектуру и совместима с протоколом MySQL. Развертывание Doris включает только два процесса (FE и BE) без зависимости от других систем, что упрощает эксплуатацию и обслуживание. Кроме того, Doris поддерживает запросы к внешним таблицам данных ES. Он может легко взаимодействовать с метаданными в ES и автоматически сопоставлять схему таблицы из ES, чтобы мы могли выполнять запросы к данным Elasticsearch через Doris, не заморачиваясь со сложными соединениями.
Более того, Doris поддерживает несколько методов приема данных, включая пакетный импорт из удаленного хранилища, такого как HDFS и S3, чтение данных из MySQL binlog и Kafka, а также синхронизацию данных в реальном времени или пакетный импорт из MySQL, Oracle и PostgreSQL. Он обеспечивает доступность службы и надежность данных с помощью протокола согласованности и поддерживает автоматическую отладку. Это отличные новости для наших операторов и специалистов по обслуживанию.
По статистике, эти функции позволили сократить расходы на хранение на 42 % и на разработку на 40 %.
Во время использования Doris мы получили большую поддержку от сообщества Apache Doris с открытым исходным кодом и своевременную помощь от команды SelectDB, которая сейчас использует коммерческую версию Apache Doris.
Дальнейшие улучшения для удовлетворения наших потребностей
Введение семантического слоя
Кроме того, наши аналитики данных могут переопределять и комбинировать теги и показатели по своему усмотрению. Но с другой стороны, высокая неоднородность систем тегов и показателей приводит к большим трудностям в их использовании и управлении.
Наше решение состоит в том, чтобы ввести семантический слой в конвейер обработки данных. На семантическом уровне все технические термины переводятся в более понятные концепции для наших внутренних пользователей данных. Другими словами, мы превращаем теги и показатели в первоклассные граждане для определения данных и управления ими.
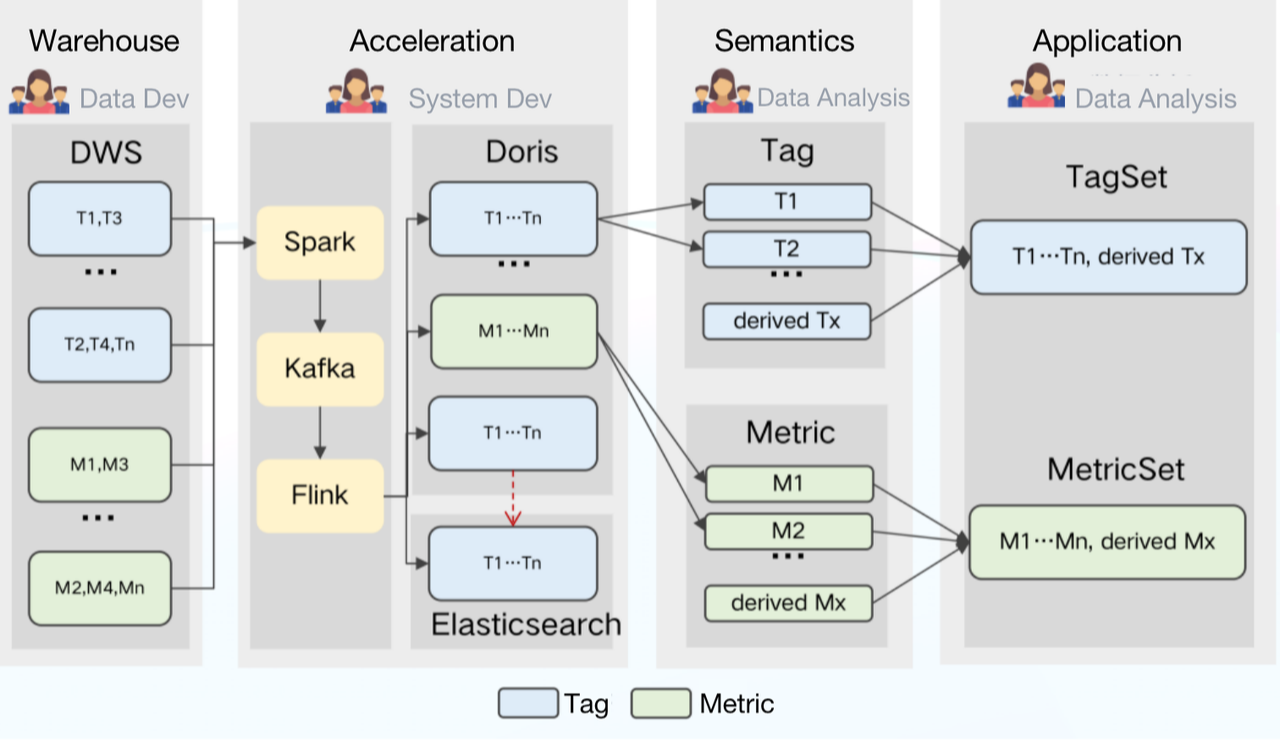
Почему это может помочь?
Для аналитиков данных все теги и показатели будут создаваться и публиковаться на семантическом уровне, чтобы избежать путаницы и повысить эффективность.
Пользователям данных больше не нужно создавать свои собственные наборы данных или выяснять, какой из них применим для каждого сценария, — они могут просто выполнять запросы к указанному набору тегов и набору показателей.
Обновите семантический уровень
Явного определения тегов и показателей на семантическом уровне было недостаточно. Чтобы создать стандартизированную систему обработки данных, нашей следующей целью было обеспечить согласованное определение тегов и показателей во всем конвейере обработки данных.
Ради этого мы сделали семантический слой сердцем нашей системы управления данными:
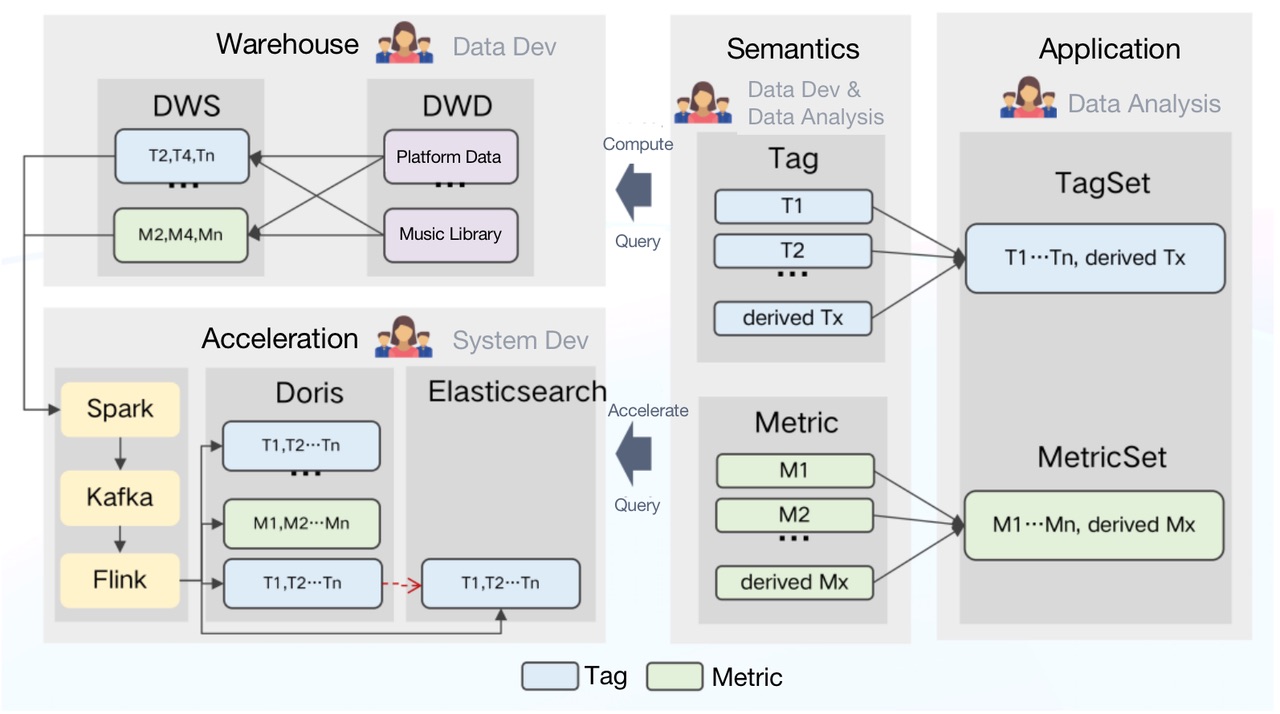
Как это работает?
Вся вычислительная логика в TDW будет определена на семантическом уровне в виде одного тега или метрики.
Семантический уровень получает логические запросы со стороны приложения, соответственно выбирает механизм и генерирует SQL. Затем он отправляет команду SQL в TDW для выполнения. Между тем, он также может отправлять задачи конфигурации и загрузки данных в Doris и решать, какие показатели и теги следует ускорить.
Таким образом, мы сделали теги и показатели более управляемыми. Ложкой дегтя является то, что, поскольку каждый тег и метрика определяются индивидуально, мы боремся с автоматизацией генерации действительного оператора SQL для запросов. Если у вас есть какие-либо идеи по этому поводу, вы можете поговорить с нами.
Полный доступ к Apache Doris
Как видите, Apache Doris сыграл ключевую роль в нашем решении. Оптимизация использования Doris может значительно повысить общую эффективность обработки данных. Итак, в этой части мы собираемся поделиться с вами тем, что мы делаем с Дорис, чтобы ускорить прием данных и запросы и сократить расходы.
Чего мы хотим?

В настоящее время у нас есть более 800 тегов и более 1300 метрик, полученных из более чем 80 исходных таблиц в TDW. При импорте данных из TDW в Doris мы надеемся достичь:
* Доступность в режиме реального времени: в дополнение к традиционному автономному приему данных T+1 нам требуется пометка в реальном времени.
* Частичное обновление: каждая исходная таблица генерирует данные с помощью своей собственной задачи ETL с разной скоростью и включает только часть тегов и метрик, поэтому нам требуется поддержка частичного обновления столбцов.
* Высокая производительность: нам нужно время отклика всего несколько секунд в сценариях группового таргетинга, анализа и отчетности.
* Низкие расходы: мы надеемся максимально сократить расходы.
Что мы делаем?
- Создавайте плоские таблицы во Flink вместо TDW
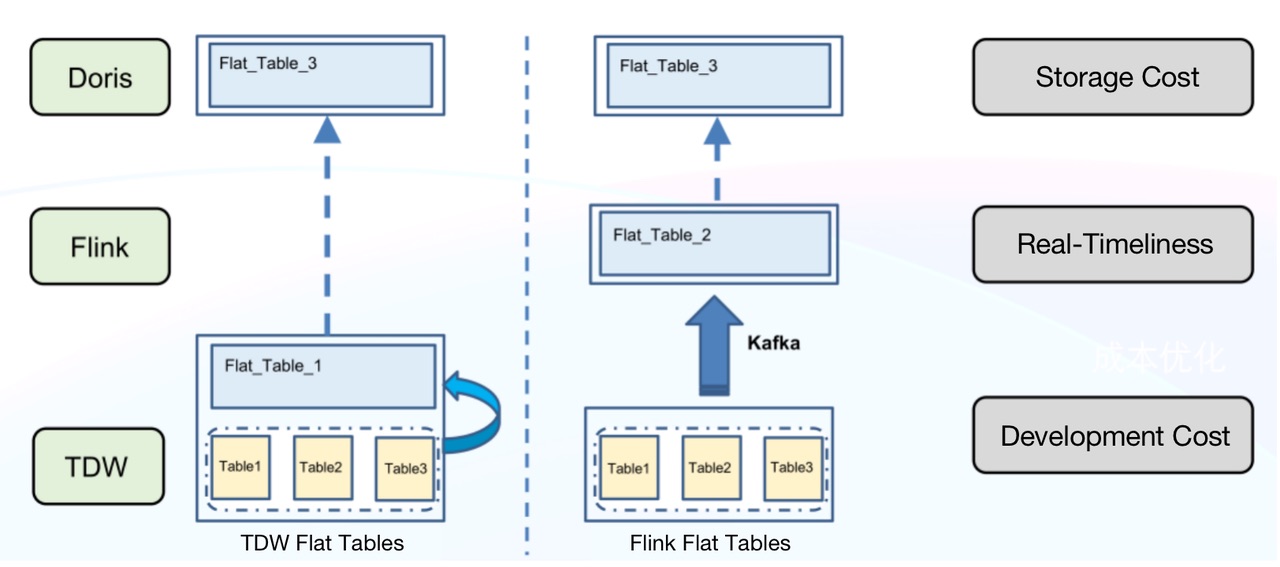
Создание плоских таблиц в TDW имеет несколько недостатков:
* Высокие затраты на хранение: TDW должна поддерживать дополнительную плоскую таблицу помимо отдельных 80+ исходных таблиц. Это огромная избыточность.
* Низкая оперативность: любая задержка в исходных таблицах будет увеличена и затормозит весь канал данных.
* Высокие затраты на разработку: для достижения оперативности требуются дополнительные усилия и ресурсы для разработки.
Наоборот, создание плоских таблиц в Doris намного проще и дешевле. Процесс выглядит следующим образом:
* Используйте Spark для импорта новых данных в Kafka в автономном режиме. * Используйте Flink для использования данных Kafka. * Создайте плоскую таблицу с помощью идентификатора первичного ключа. * Импорт плоского стола в Doris. Как показано ниже, Flink объединил пять строк данных, из которых «ID» = 1, в одну строку в Doris, уменьшив нагрузку на запись данных в Doris.

Это может значительно снизить затраты на хранение, поскольку TDW больше не нужно поддерживать две копии данных, а KafKa нужно хранить только новые данные, ожидающие приема. Более того, мы можем добавить во Flink любую логику ETL, которую захотим, и повторно использовать большое количество логики разработки для приема данных в автономном режиме и в режиме реального времени.
- Умное название столбцов
Как мы уже упоминали, агрегированная модель Дорис допускает частичное обновление столбцов. Здесь мы предлагаем простое введение в другие модели данных в Doris для справки:
Уникальная модель: подходит для сценариев, требующих уникальности первичного ключа. Он хранит только последние данные того же идентификатора первичного ключа. (Насколько нам известно, сообщество Apache Doris также планирует включить частичное обновление столбцов в Уникальную модель.)
Дублирующая модель. В этой модели все исходные данные хранятся точно так, как они есть, без предварительной агрегации или дедупликации.
После определения модели данных нам нужно было подумать, как назвать столбцы. Использование тегов или метрик в качестве имен столбцов не было выбрано, потому что:
Ⅰ. Нашим внутренним пользователям данных может потребоваться переименовать показатели или теги, но Doris 1.1.3 не поддерживает изменение имен столбцов.
Ⅱ. Теги могут быть взяты онлайн и оффлайн часто. Если это связано с добавлением и удалением столбцов, это не только отнимет много времени, но и отрицательно скажется на производительности запросов. Вместо этого мы делаем следующее:
* Для гибкого переименования тегов и метрик мы используем таблицы MySQL для хранения метаданных (имя, глобально уникальный идентификатор, статус и т. д.). Любое изменение имен произойдет только в метаданных, но не повлияет на схему таблицы в Doris. Например, если идентификатор song_name имеет идентификатор 4, он будет сохранен с именем столбца a4 в Doris. Затем, если song_name участвует в запросе, он будет преобразован в a4 в SQL.
* Для онлайн- и офлайн-тегов мы сортируем теги в зависимости от того, как часто они используются. Наименее используемые будут отмечены офлайн-меткой в своих метаданных. Под офлайн-тегами не будут добавляться новые данные, но существующие данные под этими тегами останутся доступными.
* Для доступности новых добавленных тегов и показателей в режиме реального времени мы предварительно создаем несколько столбцов идентификаторов в таблицах Doris на основе сопоставления идентификаторов имен. Эти зарезервированные столбцы идентификаторов будут выделены для вновь добавленных тегов и показателей. Таким образом, мы можем избежать изменения схемы таблицы и последующих накладных расходов. Наш опыт показывает, что уже через 10 минут после добавления тегов и метрик данные по ним могут быть доступны.
Примечательно, что недавно выпущенная версия Doris 1.2.0 поддерживает легкое изменение схемы, а это означает, что для добавления или удаления столбцов достаточно изменить метаданные в FE. Кроме того, вы можете переименовывать столбцы в таблицах данных, если вы включили легкое изменение схемы для таблиц. Это избавит нас от многих проблем.
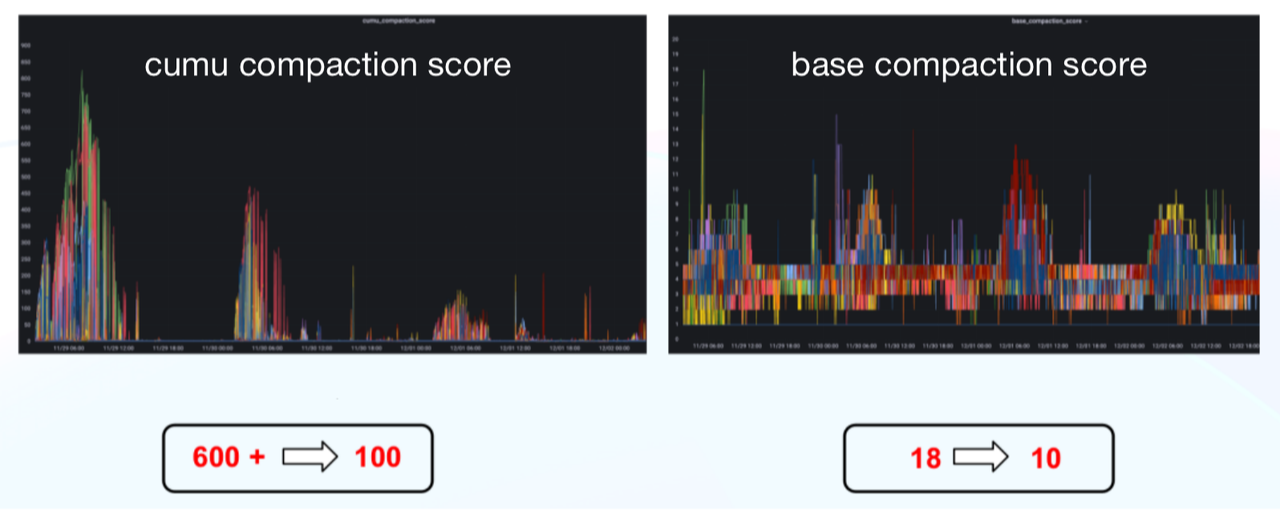
- Оптимизация написания дат
Вот несколько приемов, которые позволили сократить ежедневное время приема данных в автономном режиме на 75 %, а показатель сжатия CUMU — с 600+ до 100.
* Предварительное агрегирование Flink: как указано выше.
* Автоматическое изменение размера пакета записи: чтобы уменьшить использование ресурсов Flink, мы позволяем записывать данные в одной теме Kafka в различные таблицы Doris и реализуем автоматическое изменение размера пакета в зависимости от объема данных.
* Оптимизация записи данных Doris: точная настройка размеров таблеток и ведер, а также параметров уплотнения для каждого сценария:
<код>javascript max_XXXX_compaction_thread max_cumulative_compaction_num_singleton_deltas
* Оптимизация логики фиксации BE: регулярное кэширование списков BE, их фиксация в узлах BE пакет за пакетом и использование более тонкой детализации балансировки нагрузки.
- Используйте Dori-on-ES в запросах
Около 60 % наших запросов данных связаны с групповым таргетингом. Групповой таргетинг заключается в поиске наших целевых данных с использованием набора тегов в качестве фильтров. Это предъявляет несколько требований к нашей архитектуре обработки данных:
- Групповой таргетинг, связанный с пользователями APP, может включать очень сложную логику. Это означает, что система должна одновременно поддерживать сотни тегов в качестве фильтров.
* Для большинства сценариев группового таргетинга требуются только последние данные тегов. Однако запросы метрик должны поддерживать исторические данные.
* Пользователям данных может потребоваться дальнейший агрегированный анализ данных показателей после группового таргетинга.
* Пользователям данных также может потребоваться выполнить подробные запросы по тегам и показателям после группового таргетинга.
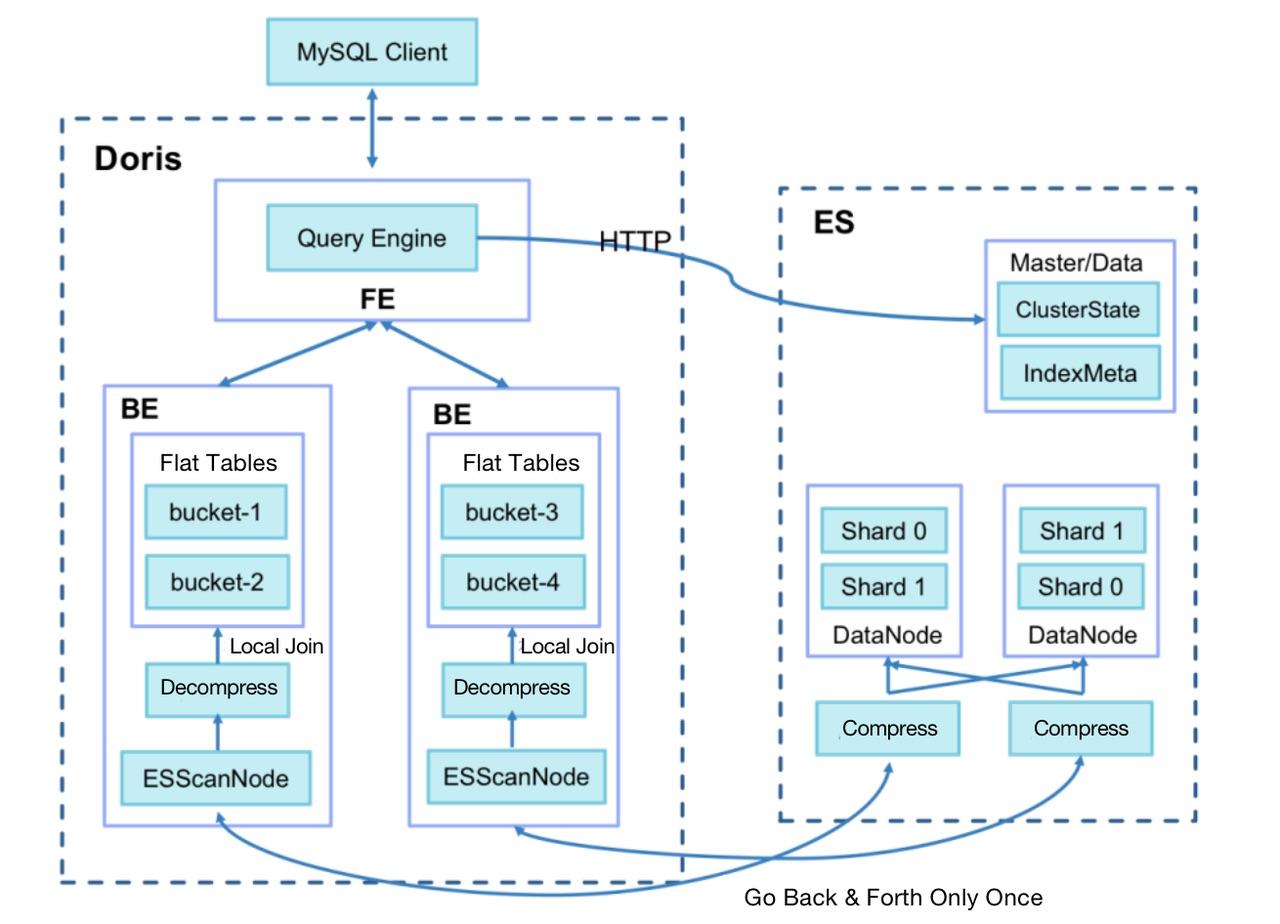
Подумав, мы решили использовать Doris-on-ES. В Doris мы храним данные метрик для каждого сценария в виде таблицы разделов, а Elasticsearch хранит все данные тегов. Решение Doris-on-ES сочетает в себе возможности планирования распределенных запросов Doris и возможности полнотекстового поиска Elasticsearch. Шаблон запроса выглядит следующим образом:
SELECT tag, agg(metric)
FROM Doris
WHERE id in (select id from Es where tagFilter)
GROUP BY tag
Как показано, данные идентификатора, расположенные в Elasticsearch, будут использоваться в подзапросе в Doris для анализа метрик. На практике мы обнаруживаем, что время ответа на запрос связано с размером целевой группы. Если целевая группа содержит более миллиона объектов, запрос займет до 60 секунд. Если он еще больше, может возникнуть ошибка тайм-аута. После расследования мы выявили двух самых больших пожирателей времени:
I. Когда Doris BE извлекает данные из Elasticsearch (по умолчанию 1024 строки за раз), для целевой группы из более чем миллиона объектов накладные расходы сетевого ввода-вывода могут быть огромными.
II. После извлечения данных Doris BE необходимо выполнить операции соединения с локальными таблицами метрик через SHUFFLE/BROADCAST, что может стоить дорого.
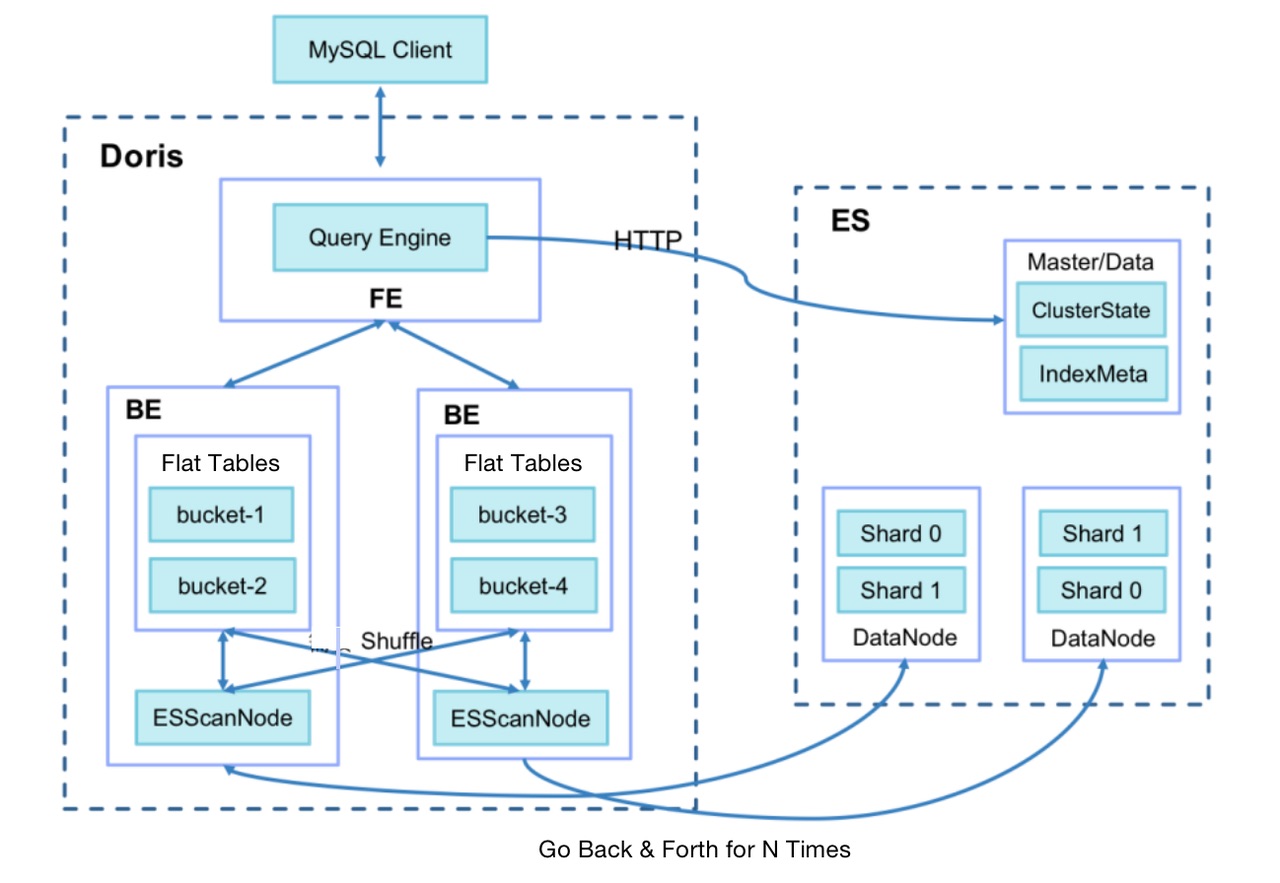
Таким образом, мы делаем следующие оптимизации:
* Добавьте переменную сеанса запроса es_optimize, которая указывает, следует ли включать оптимизацию.
* При записи данных в ES добавьте столбец BK для хранения номера корзины после хеширования идентификатора первичного ключа. Алгоритм аналогичен алгоритму группирования в Doris (CRC32).
* Используйте Doris BE для создания плана выполнения Bucket Join, отправьте номер сегмента в BE ScanNode и передайте его в ES.
* Используйте ES для сжатия запрашиваемых данных; Превратите несколько выборок данных в одну и уменьшите нагрузку на сетевой ввод-вывод.
* Убедитесь, что Doris BE извлекает только данные корзин, связанных с локальными таблицами метрик, и выполняет локальные операции соединения напрямую, чтобы избежать перетасовки данных между Doris BE.
В результате мы сократили время ответа на запрос для таргетинга на большую группу с 60 секунд до удивительных 3,7 секунд. Информация сообщества показывает, что Doris собирается поддерживать инвертированное индексирование, начиная с версии 2.0.0, которая скоро будет выпущена. В этой новой версии мы сможем выполнять полнотекстовый поиск по типам текста, фильтрацию эквивалентности или диапазона текстов, чисел и даты и времени, а также удобно комбинировать логику И, ИЛИ, НЕ в фильтрации, поскольку инвертированное индексирование поддерживает типы массивов. Ожидается, что эта новая функция Doris обеспечит в 3–5 раз более высокую производительность, чем Elasticsearch, при выполнении той же задачи.
- Улучшить управление данными
Способность Doris к разделению холодных и горячих данных лежит в основе наших стратегий сокращения затрат на обработку данных.
* На основе механизма TTL Doris мы храним данные только за текущий год в Doris и помещаем исторические данные до этого в TDW для снижения затрат на хранение.
* Мы различаем количество копий для разных разделов данных. Например, мы устанавливаем три копии для данных за последние три месяца, которые часто используются, одну копию для данных старше шести месяцев и две копии для данных между ними.
Doris поддерживает преобразование горячих данных в холодные, поэтому мы храним данные только за последние семь дней на SSD и переносим более старые данные на жесткий диск для более дешевого хранения.
Заключение
Спасибо, что пролистал весь этот путь и дочитал до конца это длинное чтение. Мы поделились нашими аплодисментами и слезами, извлеченными уроками и несколькими практиками, которые могут быть вам полезны во время нашего перехода от ClickHouse к Doris. Мы очень благодарны сообществу Apache Doris и команде SelectDB за помощь, но мы, возможно, еще какое-то время гоняемся за ними, поскольку пытаемся реализовать автоматическую идентификацию холодных и горячих данных, предварительное вычисление часто используемых тегов/метрик, упрощение логики кода с помощью материализованных представлений и т. д. и т. д.
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27103)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)