

Обучение вашего ИИ читать: Руководство по скребке, тряпке и интеллектуальным данным
17 июля 2025 г.Если вы работаете в компании, которая использует веб -данные, вы наверняка знаете, что это лишь первый уровень более сложного продукта. Фактически, данные, скрещенные в Интернете, традиционно хранились в файлах или базах данных (ведра облачного хранилища, озера данных или хранилища данных), а затем анализированы с использованием инструментов бизнес-аналитики (BI), как коммерческих, так и запатентованных. Например, команда может соскрести цены на продукты или отзывы клиентов из Интернета, сохранить необработанные данные в качестве файлов CSV/JSON, загрузить их в хранилище данных SQL, а затем использовать BI -платформы, такие как Tableau или Power BI, для создания информационных панелей и отчетов. Современные решения в области сетевого скребки даже выводят данные в структурированных форматах (CSV, JSON, Excel и т. Д.), Специально для облегчения этого трубопровода, что позволяет проще подавать результаты в существующие аналитические системы. Этот процесс позволяет аналитикам нарезать и нарезать данные для понимания, но он требует ручных усилий для сформулирования запросов или создания визуализаций.
Сегодня крупные языковые модели (LLMS) меняют эту парадигму. Вместо того, чтобы полагаться исключительно на статические панели мониторинга или запросы SQL, организации могут использовать помощников искусственного интеллекта для получения понимания из сокрасных данных с помощью подсказок естественного языка. Другими словами, а не человеческое написание запроса или интерпретации диаграммы, помощник искусственного интеллекта может напрямую ответить на вопросы о данных. Подумайте о том, чтобы иметь свой интерфейс, похожий на CATGPT, и напишите некоторые подсказки, чтобы получить информацию, обходя создание панели инструментов. Я видел такой подход в нескольких продуктах до выхода LLMS, но без большого успеха. Развивающийся ландшафт ИИ и еженедельные улучшения, которые мы видим в LLMS, могут изменить ландшафт, смещая разведку данных с биосцентрического подхода к AI-ориентированному.
Представьте себе, что спрашивает,«У какого конкурента была самая высокая цена в прошлом квартале?»Вместо того, чтобы найти правильную приборную панель или отчет Excel самостоятельно, чтобы получить ответ. Этот подход обещает более быстрый, более интуитивно понятный доступ к информации для нетехнических пользователей без накладных расходов на строительные диаграммы или написание кода. В прошлых компаниях, где я работал, я слишком много раз видел пролиферацию различных панелей мониторинга на группу пользователей (если не на пользователя), иногда извлекая разные цифры друг с другом.
Конечно, возникает новый набор проблем: как насчет галлюцинаций? Если мы не видим основное количество ответа, можем ли мы быть на 100% уверены, что ответ правильный?
В этом посте (и следующий в серии лаборатории) мы создадим сквозной проект, где мы начнем с соскоба, разбирая статьи в этой новостной рассылке, поместив их в базу данных, подходящую для использования ИИ, получая эти знания, а затем опубликовать веб-приложение, которое может использовать обогащенную версию модели GPT.
Улучшение знаний LLM
Интеграция пользовательских данных (например, ваш сокрасный набор данных) в LLM может быть сделана в первую очередь двумя способами:тонкая настройкамодель или с помощьюПоколение поиска (RAG) (RAG)и у каждого из этих методов есть плюсы и минусы. Давайте посмотрим, как они отличаются и какой подход может быть лучшим для нашего варианта использования.
Тонкая настраиваемая против поколения, полученное в поисках
Тонкая настройкаозначает обучение базового LLM на дополнительные данные, чтобы поглощать новые знания. По сути, вы принимаете предварительно обученную модель и продолжаете обучать ее в своем наборе данных, специфичной для домена, настраивая его веса для внедрения этих знаний. Например, если вы соскребили коллекцию технических статей, вы можете точно настроить LLM на этих статьях. После тонкой настройки модельпо сути знаетИнформация (в той мере, в которой она была представлена в данных обучения). Точная настройка часто выполняется путем предоставления модели большим набором пар вопросов-ответов или текстовыми отрывками из ваших данных, поэтому она учится отвечать этой информацией, когда это уместно. Фактически модельдополнен изнутри- Знание становится частью его параметров. В следующий раз, когда вы запросите модель, она может опираться на эту запеченную информацию без необходимости внешней помощи.
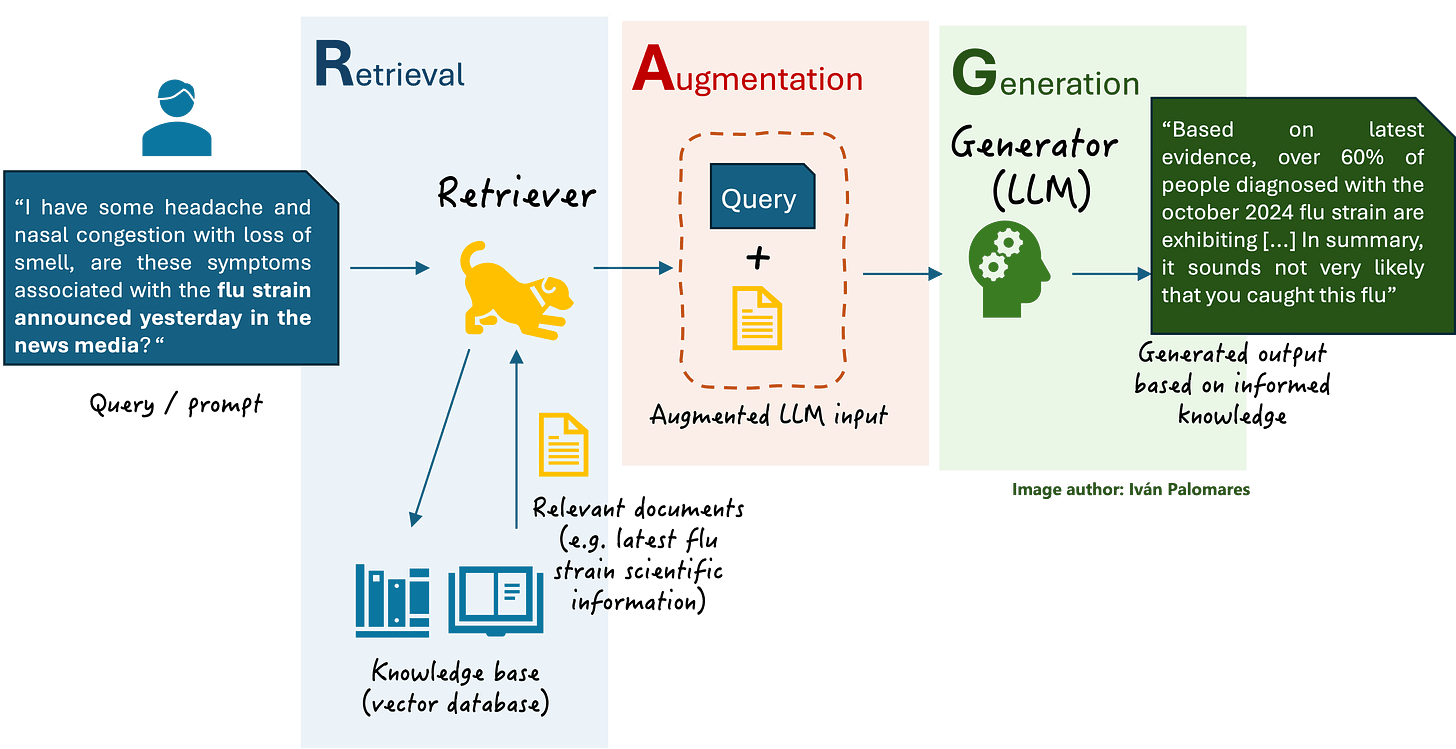
Поколение поиска (RAG) (RAG)использует другой подход: модель остается неизменной, но мы даем ей доступ к внешней базе знаний (обычно с помощью векторного поиска). Когда входит запрос, система будетполучить соответствующие документыиз ваших данных и подайте их в модель вместе с вопросом. Затем LLM генерирует свой ответ с помощью этого дополнительного контекста. Для таких бумеров, как я, рассмотрите его как вставка компакт -диска в голову Neo в Матрице, чтобы выучить новые навыки и движения. В нашем случае базой знаний может быть набором сокраренных веб -статей, хранящихся в специализированной базе данных. Rag похожа на экзамен с открытой книгой для LLM-во время запроса он исследует соответствующую «страницу» данных и использует его для сформулирования ответа, а не полагаться исключительно на свою внутреннюю память.
Как вы можете себе представить, одно ключевое отличие-то, где остаются дополнительные знания: с точной настройкой знания встроеныв самой модели(Вес модели обновляются). С тряпкой знания остаютсявнешний, в базе данных или индексе, и извлекается по мере необходимости. Точная настройка сродни навсегда обучению модели новым фактам, тогда как тряпка похоже на оснащение модели динамической библиотекой, которую она может ссылаться на лету.
Два подхода имеют разные плюсы и минусы:
Тонкая настройка:
- Плюсы:После того, как модель может реагировать быстрее и интегрированно реагировать на новые знания. Ему не нужны длинные подсказки с документами каждый раз. Хорошо настроенная модель, как правило, превосходит базовую модель по вопросам, специфичным для домена, потому что она имеет более глубокое понимание этой нишевой терминологии и содержания.
- Минусы:Точная настройка может быть ресурсной и трудоемкой и трудоемкой-вам нужны достаточные данные обучения и вычислительную мощность (или бюджет при использовании услуги). Это также делает модель статичной в отношении этого учебного снимка. Если ваши скрасные изменения данных или новая информация приходится, вам придется снова настраиваться, чтобы обновить модель. Есть также риск моделизабывили переопределить некоторые из его первоначальных знаний, если не тщательно управляется. Важно отметить, что тонкая настройка означает, что ваши данные становятся частью параметров модели, что может быть проблемой конфиденциальности, если веса модели подвергаются воздействию или при использовании сторонней службы для тонкой настройки (ваши данные загружаются для обучения). И последнее, но не менее важное: после того, как знания встроены в модель, вы не можете привести какую -либо статью, используемую для ее улучшения.
Полученное поколение (RAG):
- Плюсы:Нет необходимости изменять саму LLM-вы оставляете базовую модель как есть и просто предоставляете соответствующий контекст во время запроса. Это облегчает обновление или расширение базы знаний: добавить или удалить документы во внешнем индексе, и модель будет использовать последние данные. Это очень гибко исохраняет ваши запатентованные данные внешними(что может быть более безопасным). Rag может уменьшить галлюцинации, заземляя ответы в реальных источниках - по сути, модель имеет «квитанции», чтобы подтвердить свой ответ. Это также обычно требует менее авансовой работы, чем полная точная настройка; Большая часть усилий идет по настройке системы поиска.
- Минусы:Rag представляет больше движущихся частей - вам нужна система для встраивания и индексации документов и получения их во время выполнения. В запросе выплачиваете стоимость задержки и длины токена за подачу документов в подсказку модели. Если извлеченные документы не имеют отношения (из -за плохого запроса или несоответствия вектора), ответ пострадает. LLM также ограничен своим входным размером; Если документы плюс вопрос превышает окно контекста модели, вам, возможно, придется усечь или выбрать меньше документов. Кроме того, необработанный текст документов может повлиять на стиль модели, что может привести к менее согласованным или разговорным ответам, если вы не предпринимаете ее уточнить формулировку.
Короче говоря, тонкая настройка выпекается в целенаправленном понимании, тогда как RAG позволяет в реальном времени доступ к знаниям. Для нашего использования в случае интеграции постоянно обновленных скрасных данных RAG кажется лучшим подходом: вы можете постоянно получать новые веб -данные и попросить своего помощника использовать их немедленно, а не периодически переподтировать всю модель.
Прежде чем двигаться дальше, стоит отметить, что точная настройка и тряпка не являются взаимоисключающими; Они могут дополнить друг друга. Например, вы можете точно настроить модель, чтобы настроить его тон или способность следовать инструкциям (или добавлять знания, которые являются небольшими и статичными), и по-прежнему использовать тряпку, чтобы дать ему доступ к более крупной базе знаний, которая часто обновляется. На практике, однако, только Rag часто обеспечивает более простой и более масштабируемый путь для того, чтобы позволить помощнику искусственного интеллекта справляться с пользовательскими знаниями, на котором мы сосредоточимся на нашей реализации.
Использование локальной модели против внешнего API
Еще одно соображениеКакой LLM использоватьДля вашего помощника ИИ: местной (с открытым исходным кодом) модель, которую вы запускаете самостоятельно, или по размещему модели через API (например, GPT-3.5/GPT-4 или другие). И тонкая настройка, и тряпка могут быть сделаны с помощью или есть компромиссы:
Местные LLMS с открытым исходным кодом- Такие модели, как Llama 2, Mistral или Falcon, могут работать на ваших собственных серверах. Большое преимущество здеськонтроль и конфиденциальностьПолем Ваши скрещенные данные никогда не покидают вашу среду, что важно, если они содержит конфиденциальную информацию. Вы можете свободно настроить их на свои данные или изменить то, как они работают. С точки зрения затрат, запуск локальной модели может быть дешевле для больших объемов запросов (без сборов API), но вы должны инвестировать в аппаратную или облачную инфраструктуру для ее размещения. Недостатком является то, что многие открытые модели не могли соответствовать выступлениям новейших GPT. Возможно, вам придется использовать более крупные или более специализированные модели, чтобы получить сопоставимую производительность, которая может быть сложной для управления. Кроме того, поддержание и обновление модели (и, возможно, векторная база данных, если она находится в PREM), находится на вас. В случае, если выделатьИметь высокоспецифичный набор данных и опыт, локальная модель может быть точно настроена, чтобы преуспеть в этом домене, что делает его прочным решением для «частного GPT».
Внешние API LLMS (например, OpenAI)-Использование API, такого как GPT-4 Openai, означает, что вам не нужно беспокоиться о запуске модели; Вы просто отправляете свои подсказки на их сервис и получаете завершение. Это очень удобно и, как правило, дает вам доступ к передовому качеству модели без проблем инфраструктуры. Для нашего сценария вы можете использовать тряпку, просто подготовив полученные документы к своему подсказке и попросив API ответить. Недостатки здесь связаны с настройкой и конфиденциальностью. Не каждая модель доступна для точной настройки (
В общем, если ваш вариант использования включает в себя высокочувствительные данные или требует полного контроля, рекомендуется локальный LLM, несмотря на дополнительные усилия. Если ваш приоритет является наилучшей возможной языковой способностью и быстрой настройкой, такая модель, как Openai, может быть лучшим выбором. В реализации этого поста мы проиллюстрируем использование API GPT OpenAI для простоты и качества, но система поиска, которую мы создаем, могла бы так же легко войти в модель с открытым исходным кодом, такую как Llama2, через библиотеки Huggingface или Langchain. Механизм поиска (векторная база данных + поиск сходства) остается прежним; Только окончательная модель, генерирующая ответ, будет отличаться.
Учитывая эти решения, давайте интегрируем мои сокраженные статьи в помощника искусственного интеллекта. Мы будем использовать подход RAG с моделью OpenAI, которая хорошо соответствует постоянно обновляемым веб-данным и избегает необходимости дорогостоящих заданий.
Соскабливание TWSC с помощью FireCRAWL
Для блога Web Scraping Club мы будем использовать его карту сайта, чтобы открыть для себя все URL -адреса статьи. (Блог размещен на Supack, который предоставляет XML SiteMap, в котором перечислены все сообщения.) FireCRAWL может ползти на сайте без карты сайта, но использование его в качестве отправной точки может быть более эффективным и убедиться, что мы не пропускаем какие -либо страницы.
Во -первых, мы настроили FireCRAWL, установив его Python SDK и аутентификацию с помощью клавиши API (при условии, что вы подписались и получили ключ):
from firecrawl import FirecrawlApp
import os
os.environ["FIRECRAWL_API_KEY"] = "YOURKEY" # or load from .env
app = FirecrawlApp()
# Define the sitemap URL (we can loop this for multiple years if needed)
map_result = app.map_url('https://substack.thewebscraping.club/sitemap.xml', params={
'includeSubdomains': True
})
print(map_result)
for article in map_result['links']:
if '/p/' in article:
print(article)
response = app.scrape_url(url=article, params={'formats': [ 'markdown' ]})
Всего лишь несколько строк кода наши статьи уже находятся в формате Markdown.
Выбор векторной базы данных для тряпки
Авекторная база данныхявляется ключевым компонентом реализации RAG. В нем хранится ваши документы «вставки (векторные представления) и позволяет быстрому поиску сходства приносить соответствующие документы для данного встраивания запроса. Доступно много вариантов, включая библиотеки с открытым исходным кодом и управляемые облачные сервисы, но для нашей реализации мы будем использоватьPineconeПолем
Настройка PineCone
Первые шаги, конечно, подписываются в Pinecone и получение API_KEY и среды от приборной панели. Затем мы можем установить Python SDK, как обычно
pip install pinecone
Наконец, мы можем подключиться к Pinecone в нашем сценарии
from pinecone import Pinecone, ServerlessSpec
pc = pinecone.Pinecone(
api_key="YOUR API KEY"
)
Значение среды поступает из веб -консоли Pinecone при создании ключа API.
Создание индекса Pinecone
Индекс - это то, где ваши данные хранятся для более позднего повторного обращения из LLM. Вместо того, чтобы находиться в простом тексте, он находится в векторе -формате (в основном ряда числа), что позволяет LLM понять, какая запись в индексе, скорее всего, является хорошим ответом для запроса, который делает LLM.
Ввекторная база данныхнравитьсяPinecone,
ПокавекторыпредставлятьЧисленные вторженияиспользуется для поиска сходства,метаданныепредоставляет структурированную информацию о том, что представляет вектор. Это позволяетфильтрация, категоризация и интерпретацияПолем В то время как в векторных данных мы вставим отметку статей, в метаданных мы будем использовать некоторую информацию, которую мы хотим, чтобы LLM поделился с нами, как автор блога, используемый для ответа, заголовок и ссылку на пост.
index_name = "article-index"
if not pc.has_index(index_name):
index_model = pc.create_index_for_model(
name=index_name,
cloud="aws",
region="us-east-1",
embed={
"model":"llama-text-embed-v2",
"field_map":{"text": "chunk_text"}
}
)
#pc.describe_index(index_name) #to get the host
index=pc.Index(host='YOURINDEXENDPOINT')
.....
article_data = [
{"id": f"article-{i}", "text": page["markdown"], "url": page["metadata"]["url"], "title": page["metadata"]["title"], "author": page["metadata"]["author"][0]}
for i, page in enumerate(scrape_results['data'])
]
#print(article_data)
# Generate embeddings using LLaMA v2
for article in article_data:
# Estrai il testo dell'articolo
text = article["text"]
#print(text)
# Single article insert to avoid failures
embedding = pc.inference.embed(
model="llama-text-embed-v2",
inputs=[text],
parameters={"input_type": "passage"}
)
# Prepare data for Pinecone upsert
vector_data = {
"id": article["id"], # Unique article ID
"values": embedding[0]["values"], # Embedding vector
"metadata": {
"url": article["url"], # Store article URL
"content": text[:300], # Store first 500 chars as a preview/snippet
"title": article["title"][:100],
"author": article["author"][:50]
}
}
#print(vector_data)
# Upsert the single article into Pinecone
index.upsert(vectors=[vector_data], namespace="articles")
print(f"✅ Upserted: {article['id']} ({article['title']})")
# Optional: Add a short delay to prevent API rate limits (adjust as needed)
time.sleep(1)
Как вы можете видеть из кода, мы в основном повторяем каждую статью, скрещенную ранее, и добавляем ее в недавно созданный индекс под названиемСтатья-индексПолем
Если вы хотите больше играть с Pinecone, есть
Но теперь я вставил все статьи по индексу, можем ли мы извлечь необходимую информацию?
Я создал базовый сценарий под названием Query.py, чтобы проверить результаты поиска по индексу.
Когда его спросили: «Не могли бы вы перечислить несколько статей об обходе Касады?», Запрос возвращает следующие статьи:
{'matches': [{'id': 'article-0',
'metadata': {'author': 'Pierluigi Vinciguerra',
...,
'title': 'THE LAB #76: Bypassing Kasada With Open '
'Source Tools In 2025',
'url': 'https://substack.thewebscraping.club/p/bypassing-kasada-2025-open-source'},
'score': 0.419812053,
'values': []},
{'id': 'article-129',
'metadata': {'author': 'Pierluigi Vinciguerra',
...,
'title': 'How to by-pass Kasada bot mitigation?',
'url': 'https://substack.thewebscraping.club/p/how-to-by-pass-kasada-bot-mitigation'},
'score': 0.418432325,
'values': []},
{'id': 'article-227',
'metadata': {'author': 'Pierluigi Vinciguerra',
...,
'title': 'Scraping Kasada protected websites',
'url': 'https://substack.thewebscraping.club/p/scraping-kasada-protected-websites'},
'score': 0.378159761,
'values': []}],
'namespace': 'articles',
'usage': {'read_units': 6}}
Неплохо! Все три статьи были именно об этой теме!
На сегодняшний день достаточно, в следующем эпизоде мы увидим, как подключить этот DB к GPT4, а затем создать простой пользовательский интерфейс для записи подсказки и получить необходимые данные.
Статья является частью«Лаборатория»серияПьерлуиджи ВинсгуерраПолем Проверьте егоПодмазочныйСтраница для получения дополнительных знаний о скребке.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)