
Проектирование системы: итеративный и поэтапный подход
3 февраля 2024 г.Инженеры, работающие с данными, программным обеспечением или DevOps, часто стремятся создать или спроектировать идеальное решение. Они, как правило, сосредотачиваются преимущественно на технических аспектах, иногда упуская из виду результаты бизнеса. Это распространенное упущение.
Однако наша главная цель — разработать продукт, решающий бизнес-задачу, а не обязательно создать безупречное решение. Поэтому нам необходимо постоянно пересматривать наш дизайн, чтобы быть уверенными, что мы на правильном пути.
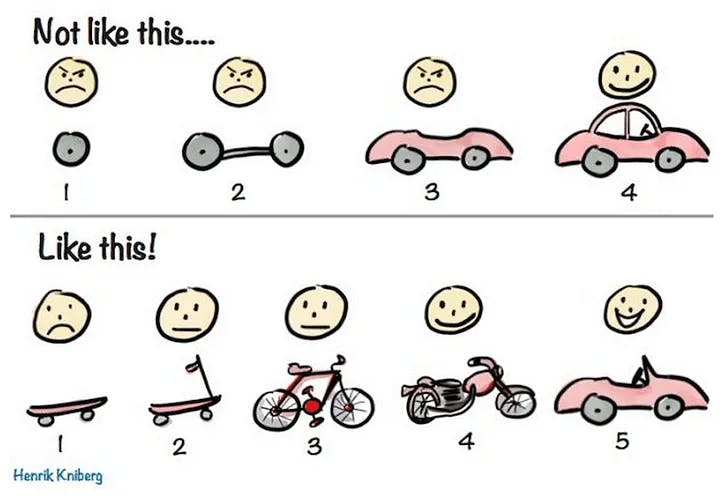
Поэтапное проектирование приводит к созданию работающей системы в конце внедрения. С другой стороны, итеративный дизайн создает функционирующую систему в конце каждой итерации.
Яркие примеры итеративного дизайна представлены на картине, созданной Хенриком Книбергом. Звучит хорошо?
В области обработки данных рассмотрим задачу построения конвейера данных. Этот конвейер должен принимать данные из источника, преобразовывать их, загружать в пункт назначения и обеспечивать доступ к данным. Чтобы найти правильное решение, нам необходимо ответить на несколько вопросов:
- Каков источник (технология, формат и т. д.)?
- Включение CDC в исходной базе данных, для чего может потребоваться:
- Изменения в исходной базе данных с участием администраторов баз данных <ли>
- Реализовать пакетный конвейер, который принимает данные из исходной базы данных и загружает их на нашу платформу данных (на необработанный уровень). В зависимости от объема данных это может быть полная загрузка или частичная загрузка в зависимости от определенных критериев.
- Реализовать поэтапную обработку данных от необработанного слоя к последующим уровням, что может сократить время обработки и затраты на инфраструктуру.
- Включите CDC в исходной базе данных.
2. Какой объем данных нам нужно принимать (в целом, регулярно)?
3. Каково предназначение (технология, формат и т.д.)?
4. Каковы бизнес-ожидания от конвейера (SLA, доступность, задержка и т. д.)?
Первые три вопроса носят технический характер, а четвертый – бизнес-ориентированный. Ответы на эти вопросы будут определять наши технические решения. В зависимости от бизнес-приоритетов и уровня знаний мы можем услышать такие ответы:
* Нам нужны свежие данные ежедневно.
* Свежие данные должны быть доступны в рабочее время.
Предполагая, что у нас есть реляционная база данных в качестве исходной системы и платформа данных (хранилище данных, озеро данных, озеро и т. д.) в качестве цели, мы можем приступить к проектированию нашего конвейера. Нашим первоначальным решением может быть пакетный конвейер, который запускается ежедневно и загружает данные в нашу платформу данных.
Но, имея прошлый опыт приема данных с меньшей задержкой или если мы использовали систему отслеживания измененных данных (CDC), мы могли бы предложить конвейер, который принимает данные с меньшей задержкой (ежечасно или почти в реальном времени).
Однако реализация потокового конвейера требует выполнения нескольких задач:
Выбор, настройка и установка программного обеспечения CDC с участием DevOp
2. Определение целевой системы для данных CDC (файловая система, хранилище объектов, брокер сообщений).
3. Написание потокового конвейера, который принимает данные CDC на нашу платформу данных (на необработанный уровень).
4. Написание потокового конвейера, который преобразует данные и постепенно загружает их на следующие уровни.
5. Обеспечение всех компонентов мониторингом, оповещением, журналированием и т. д.
В зависимости от размера компании и существующих технологий внедрение такого решения может занять от нескольких недель до месяцев.
Чтобы избежать создания решения, которое может оказаться ненужным, мы должны строить нашу систему постепенно и итеративно. Вот возможный подход:
Этап 1:
2. Реализуйте пакетный конвейер, который считывает только фактические данные из необработанного слоя и усекает вставки в последующие слои. Такой подход избавляет нас от необходимости выполнять операции обновления, удаления и слияния, что позволяет ускорить реализацию.
3. Обеспечьте все компоненты мониторингом, оповещением, журналированием и т. д.
Этап 2:
Этап 3:
2. Определите целевую систему для данных CDC (файловая система, объектное хранилище, брокер сообщений).
3. Внедрить потоковый конвейер, который принимает данные CDC в нашу платформу данных и постепенно обрабатывает их на следующих уровнях.
4. Обеспечьте все компоненты мониторингом, оповещением, журналированием и т. д.
На каждом этапе у нас есть работающая система, которая решает бизнес-задачу, позволяя бизнесу получить выгоду от нашего внедрения. Мы можем остановиться на любом этапе или продолжить внедрение дополнительных функций в соответствии с потребностями бизнеса.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27720)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)