

Архитектура сутры: расширенный контекст и смесь экспертов для многоязычных LLMS
26 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 Связанная работа
3 подход сутры
3.1 Что такое сутра?
3.2 Архитектура
3.3 Данные обучения
4 тренинги многоязычных токенизаторов
5 многоязычных MMLU
5.1 Массивное многозадачное понимание языка
5.2 Расширение MMLU на несколько языков и 5.3 последовательная производительность между языками
5.4 по сравнению с ведущими моделями для многоязычной производительности
6 Количественная оценка запросов в реальном времени
7 Обсуждение и заключение, а также ссылки
3.2 Архитектура
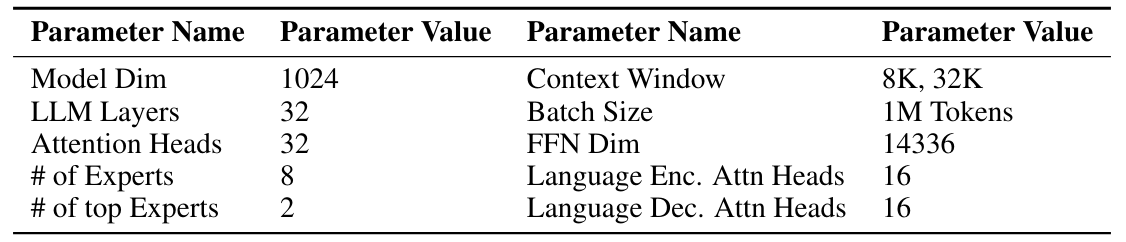
Архитектура нашей модели, называемая здесь как сутра, основана на основополагающих принципах архитектуры трансформатора, очерченных Vaswani et al. [2017]. Наша модель сохраняет усовершенствования, указанные Jiang et al. [2023], с критической адаптацией, которая облегчает расширенную длину плотного контекста до 32K токенов. Кроме того, мы использовали слои MOE, позволяя селективной активации экспертов и приводя к эффективности в вычислении и потреблении памяти, как показано на рисунке 2. Ключевые архитектурные параметры сутры инкапсулируются в таблице 2.
Учитывая вход x, выход, полученный экспертным модулем смеси, представляет собой сумму вклада каждой экспертной сети, модулируемой сетью стробирования. Формально, для n -экспертов {e0, e1, ..., en - 1} результирующий выход:

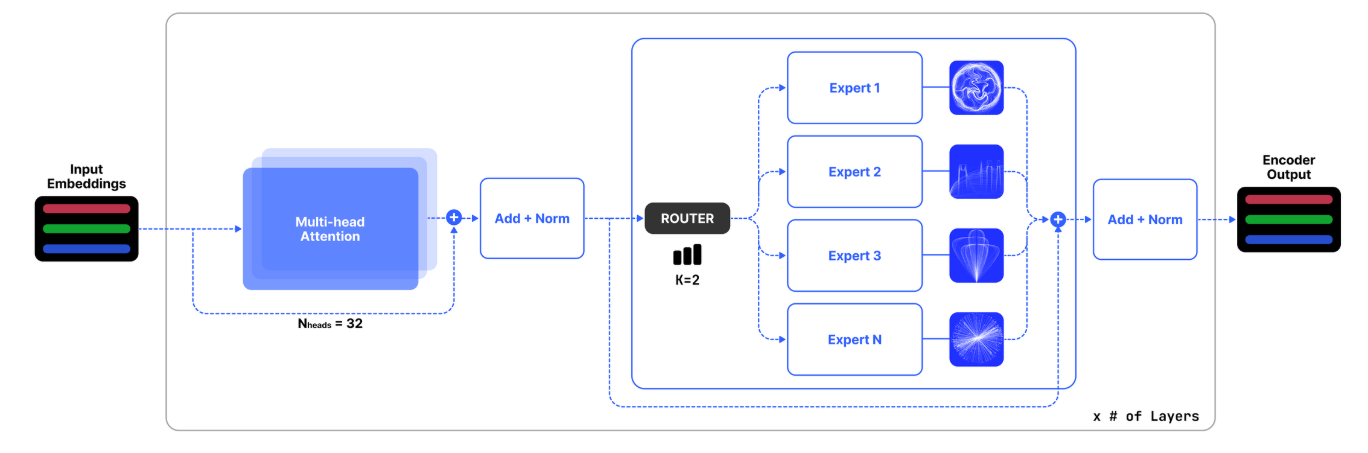
где g (x) I представляет вывод функции стробирования, создавая n-мерный вектор, соответствующий активации эксперта I-TH, в то время как EI (x) определяет результаты I-TH Expert Network. Модель извлекает выгоду из разреженности, игнорируя неактивных экспертов, тем самым сохраняя вычислительные ресурсы. Существуют несколько механизмов построения стробирующей функции g (x) [Clark et al., 2022, Hazimeh et al., 2021, Zhou et al., 2022]; Тем не менее, наша реализация выбирает эффективный подход к выбору значений Top-K из линейной проекции, за которой следует операция Softmax [Shazeer et al., 2017]:

Авторы:
(1) Абхиджит Бендейл, две платформы (abhijit@two.ai);
(2) Майкл Сапенза, две платформы (michael@two.ai);
(3) Стивен Рипплингер, две платформы (steven@two.ai);
(4) Саймон Гиббс, две платформы (simon@two.ai);
(5) Jaewon Lee, две платформы (jaewon@two.ai);
(6) Пранав Мистри, две платформы (pranav@two.ai).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)