

Потоковая передача данных из REST API с использованием Spring Webflux
26 апреля 2023 г.В современном быстро меняющемся и управляемом данными мире эффективная обработка больших объемов данных может иметь решающее значение. Spring Webflux, часть среды Spring, обеспечивает неблокирующий реактивный подход к обработке потоков данных, обеспечивая низкое потребление ресурсов и высокую пропускную способность. В этой статье рассматриваются возможности Spring Webflux и его практическое применение.
В этом руководстве мы будем использовать общедоступный API 4chan в качестве источника данных. Выбор 4chan API — это не одобрение платформы, а практическое решение, основанное на ее общедоступности, отсутствии требований аутентификации и характере ее данных, который подходит для демонстрации возможностей Spring Webflux.
В этой статье вы узнаете, как получать данные из API 4chan, непрерывно транслировать их с помощью Spring Webflux и обрабатывать данные, чтобы получить представление о показателях платформы.
:::подсказка Репозиторий git для этого руководства можно найти здесь.
:::
Зависимости и структура проекта
Проект 4chan Metrics Collector состоит из двух подмодулей Gradle: app и api-client. Файл settings.gradle.kts отвечает за включение этих подмодулей в проект.
Файл build.gradle.kts служит основной конфигурацией сборки проекта. Он определяет плагины, совместимость с Java, конфигурации, репозитории и общие зависимости для всех подмодулей.
Примечательные зависимости для этого проекта включают:
- Активатор Spring Boot
- Весенняя загрузка WebFlux
- АОП Spring Boot
- Ломбок
- Реестр Micrometer Prometheus
Подмодуль app, настроенный в app/build.gradle.kts, зависит от подмодуля api-client. Подмодуль app — это приложение Spring Boot, отвечающее за запуск сборщика метрик. Подмодуль api-client, настроенный в api-client/build.gradle.kts, представляет собой библиотеку, содержащую реализацию клиента API, используемого приложением<. /code> для доступа к общедоступному API 4chan.
Хотя основное внимание в этой статье уделяется использованию Spring Webflux для потоковой передачи данных из API 4chan, проект также демонстрирует несколько других ценных функций, таких как:
* Проект Gradle с конфигурацией на основе Kotlin * Запуск и остановка потоков при запуске и завершении работы приложения * Пользовательская конфигурация Spring * Использование Docker Compose для одновременного запуска приложения, Prometheus и Grafana. * Публикация метрик в Prometheus * Использование Grafana для построения графиков опубликованных показателей
Извлечение, потоковая передача и обработка данных с помощью Spring Webflux
В этом разделе мы рассмотрим, как приложение извлекает данные из API 4chan, выполняет потоковую передачу данных с помощью Spring Webflux и обрабатывает их для сбора и публикации показателей.
Обзор
Процесс начинается с класса MetricsCollector, который планирует периодические запросы к API 4chan на основе настроенных досок в файле application.yml. Для каждой платы создается Flux для передачи данных, и эти экземпляры Flux объединяются в один Flux, на который подписывается приложение. По мере прохождения данных по подписке приложение публикует метрики в Prometheus.
На приведенной ниже диаграмме показан поток приложения. Каждая настроенная доска постоянно отправляет сообщения, содержащие метаданные об их активных потоках, полученные из общедоступного API 4chan. Эти потоки объединяются в один непрерывный поток для всех активных потоков на настроенных досках, и каждый сообщение обрабатывается в подписке, метрики публикуются в Prometheus.
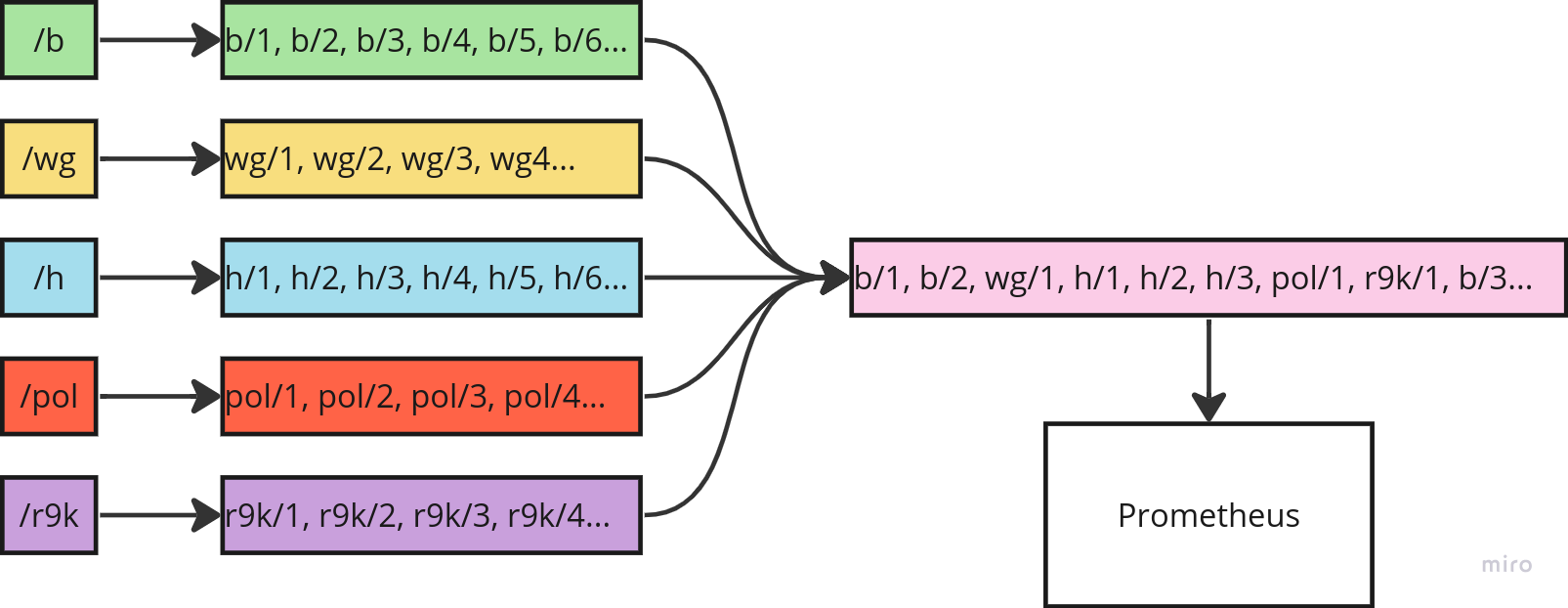
Создать Flux и подписаться на поток данных
@PostConstruct
public void produce() {
boards.stream()
.map(board -> Flux.create(emit(board)))
.reduce(Flux::merge)
.orElse(Flux.empty())
.flatMap(Function.identity())
.doOnNext(this::publishThreadMetrics)
.subscribe();
}
Точкой входа приложения является метод product в классе MetricsCollector. Благодаря аннотации @PostConstruct этот метод выполняется при запуске приложения. В этом методе все настроенные платы передаются в потоковом режиме, и каждая из них сопоставляется с Flux, отвечающим за отправку данных активных потоков для платы.
На данный момент у нас есть поток отдельных объектов Flux, который затем сводится к одному Flux, содержащему все активные потоки для всех настроенных плат. Наконец, он подписывается, чтобы начать процесс потребления данных, и по мере того, как каждый следующий элемент проходит через поток, соответственно публикуются метрики потока.
Излучающие элементы в поток
Метод emit в классе MetricsCollector настраивает планировщик для периодического выполнения запросов:
private Consumer<FluxSink<Flux<FourChanThread>>> emit(final String board) {
return emitter -> scheduler.scheduleAtFixedRate(
execute(emitter, board),
random.nextInt(REQUEST_DELAY_SECONDS),
REQUEST_INTERVAL_SECONDS,
TimeUnit.SECONDS);
}
Случайная задержка гарантирует, что не все потоки одновременно отправят запросы к API 4chan.
Метод execute вызывает метод getThreads класса ApiClient для получения данных из API 4chan:
private Runnable execute(final FluxSink<Flux<FourChanThread>> emitter, final String board) {
return () -> {
emitter.next(apiClient.getThreads(board));
};
}
Получение данных из общедоступного API
Класс ApiClient использует экземпляр WebClient для выполнения реактивных HTTP-запросов к общедоступному API 4chan. Метод getThreads возвращает Flux<FourChanThread>, представляющий поток данных активных потоков для конкретной платы.
Каждый вызов конечной точки потоков возвращает список страниц, и каждая страница содержит список потоков. Вызов bodyToMono анализирует ответ JSON< /a> в Publisher одного списка страниц. Последующие вызовы сопоставления используются для распаковки потоков из содержащих их списков, создавая Flux потоков. Последнее сопоставление используется для обогащения метаданных треда конкретной доской, к которой принадлежит тред.
public Flux<FourChanThread> getThreads(String board) {
log.debug("Issuing request to get threads for /{} board", board);
Endpoint endpoint = Endpoint.THREADS; // Endpoint is an enum that defines the API endpoints and is used to build the endpoint path
ParameterizedTypeReference<List<FourChanThreadList>> typeReference =
new ParameterizedTypeReference<>() {
};
return webClient.get()
.uri(endpoint.getEndpoint(board))
.retrieve()
.bodyToMono(typeReference)
.timeout(TIMEOUT)
.doOnError(throwable -> log.warn("Error when issuing request to get threads for /{} board", board, throwable))
.flatMapMany(Flux::fromIterable)
.flatMap(threadList -> Flux.fromIterable(threadList.getThreads()))
.flatMap(thread -> Mono.just(thread.withBoard(board)));
}
Тестирование приложений Webflux
Тестирование приложений Webflux может быть довольно сложным из-за асинхронного и неблокирующего характера реактивного программирования. Однако при правильном подходе и инструментах вы можете написать эффективные тесты, обеспечивающие надлежащую функциональность и производительность вашего приложения. В этом разделе мы обсудим проблемы тестирования приложений Webflux, используем модульные тесты нашего проекта в качестве примеров и дадим советы по написанию эффективных тестов.
Проблемы тестирования приложений Webflux
Некоторые проблемы при тестировании приложений Webflux включают:
- Асинхронное поведение. Поскольку приложения Webflux создаются с использованием реактивного программирования, обработка асинхронного поведения в тестах может быть сложной. Вам необходимо убедиться, что ваши тестовые примеры правильно учитывают асинхронный характер тестируемого кода.
- Обработка ошибок. Реактивные приложения могут иметь сложные сценарии обработки ошибок. Очень важно протестировать различные состояния ошибок, чтобы убедиться, что ваше приложение корректно обрабатывает сбои.
- Тайм-ауты. Тайм-ауты — это распространенная проблема в приложениях Webflux, и проверка того, как ваше приложение их обрабатывает, имеет решающее значение для обеспечения надежной работы.
- Веб-клиент: сложно имитировать реактивный
WebClient, используемый для создания HTTP вызовы. Без надлежащей осторожности легко запутаться в сложной структуре методов, которые нужно заглушить, и последующих объектов, которые нужно имитировать.
Модульное тестирование
В нашем проекте у нас есть два тестовых класса, MetricsCollectorTest и ApiClientTest, которые охватывают различные аспекты функциональности приложения. Эти тесты служат примерами того, как справляться с проблемами, упомянутыми выше:
Асинхронное поведение
Класс MetricsCollectorTest проверяет асинхронное поведение метода produce(), используя Thread.sleep() для ожидания ожидаемого времени выполнения. прежде чем делать утверждения.
metricsCollector.produce();
Thread.sleep(TimeUnit.SECONDS.toMillis(REQUEST_DELAY_SECONDS) + 1L);
Класс ApiClientTest использует StepVerifier из библиотеки reactor-test, чтобы гарантировать ожидаемое поведение getThreads(). метод.
Flux<FourChanThread> result = apiClient.getThreads(board);
StepVerifier.create(result)
.expectNext(...)
.verifyComplete();
Обработка ошибок
Класс ApiClientTest проверяет обработку ошибок методом getThreads(), имитируя отсутствующую доску и гарантируя, что выдается исключение WebClientResponseException.
Flux<FourChanThread> result = apiClient.getThreads(board);
StepVerifier.create(result)
.expectErrorMatches(throwable -> throwable instanceof WebClientResponseException)
.verify();
Время ожидания
Класс ApiClientTest проверяет обработку тайм-аута метода getThreads(), имитируя отложенный ответ, гарантируя создание TimeoutException.
Flux<FourChanThread> result = apiClient.getThreads(board);
StepVerifier.create(result)
.expectErrorMatches(throwable -> throwable instanceof TimeoutException)
.verify();
Веб-клиент
В классе ApiClientTest мы внедряем адаптированный WebClient в экземпляр ApiClient, который тестируется с помощью указанной функции обмена. Это позволяет нам контролировать поведение WebClient и создавать тестовые примеры, подходящие для различных сценариев.
private WebClient createWebClient(HttpStatus httpStatus, Duration delay, String body, String contentType) {
ClientResponse clientResponse = ClientResponse.create(httpStatus, ExchangeStrategies.withDefaults())
.header(HttpHeaders.CONTENT_TYPE, contentType)
.body(body)
.build();
ExchangeFunction exchangeFunction = request -> Mono
.just(clientResponse)
.delayElement(delay);
return WebClient.builder()
.exchangeFunction(exchangeFunction)
.build();
}
Заключение
В этой статье мы рассмотрели возможности Spring Webflux для обработки больших объемов данных из REST API, используя общедоступный API 4chan в качестве источника данных. Мы узнали, как получать, передавать и обрабатывать данные с помощью Spring Webflux, а также изучили структуру проекта, зависимости и различные функции, такие как конфигурация проекта Gradle, запуск и остановка потоков и пользовательская конфигурация Spring.
Мы также обсудили проблемы тестирования приложений Webflux и предоставили примеры из модульных тестов нашего проекта для преодоления этих проблем. Мы подчеркнули важность обработки асинхронного поведения, обработки ошибок и тайм-аутов при тестировании и дали советы по написанию эффективных тестов для приложений Webflux.
Поняв и применив концепции, представленные в этой статье, вы будете лучше подготовлены к использованию возможностей Spring Webflux в своих собственных приложениях. В результате вы можете создавать эффективные приложения, управляемые данными, которые эффективно обрабатывают и анализируют большие объемы данных из REST API.
:::информация Избранное изображение Белоснежка
:::
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27222)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)