

Прекратить подсказка, начало инженерии: 15 принципов для доставки вашего агента искусственного интеллекта в производство
20 июня 2025 г.Введение
Сначала вы просто пытаетесь общаться с CHATGPT через API, добавить пару строк контекста и чувствовать себя пораженным, что он вообще реагирует. Тогда вы хотите, чтобы это сделало что -то полезное. Тогда - сделать это надежно. В конце концов - сделать это без тебя.
Вот как родился агент.
Если вы также провели прошлый год, поднимая агентов из сценариев и оберток, экспериментируя и разжигая, и вы все еще ищете более чистый, более устойчивый способ их построения - эта статья для вас. Я бродил по репо и форумам, неоднократно спрашивая себя: «Как это делают другие?» > Я сохранил то, что застряло-что на самом деле чувствовалось сразу после некоторого реального использования, и постепенно переоборудовал набор основных принципов для превращения классной идеи в готовое решение.
Это не манифест. Думайте об этом как о практической шпаргальнике - коллекции инженерных принципов, которые помогают направлять агента от песочницы к производству: от простой обертки API до стабильной, контролируемой и масштабируемой системы.
Отказ от ответственности
ВЭта статья(Создание эффективных агентов), Антропик определяет агента как систему, в которой LLMS динамически направляет свои собственные процессы и использование инструментов, поддерживая контроль над тем, как они выполняют задачи. Системы, в которых LLM и инструменты организованы с помощью предопределенных путей кода, которые они называют рабочими процессами. Оба являются частью более широкой концепции - агентских систем.
В этом тексте, Agent = Agent System, где ради стабильности и управления я чаще склоняюсь к рабочим процессам. Я надеюсь, что в ближайшем будущем будет больше 1-2 поворотов эволюции, и настоящие агенты будут повсеместными, но сейчас это не так.
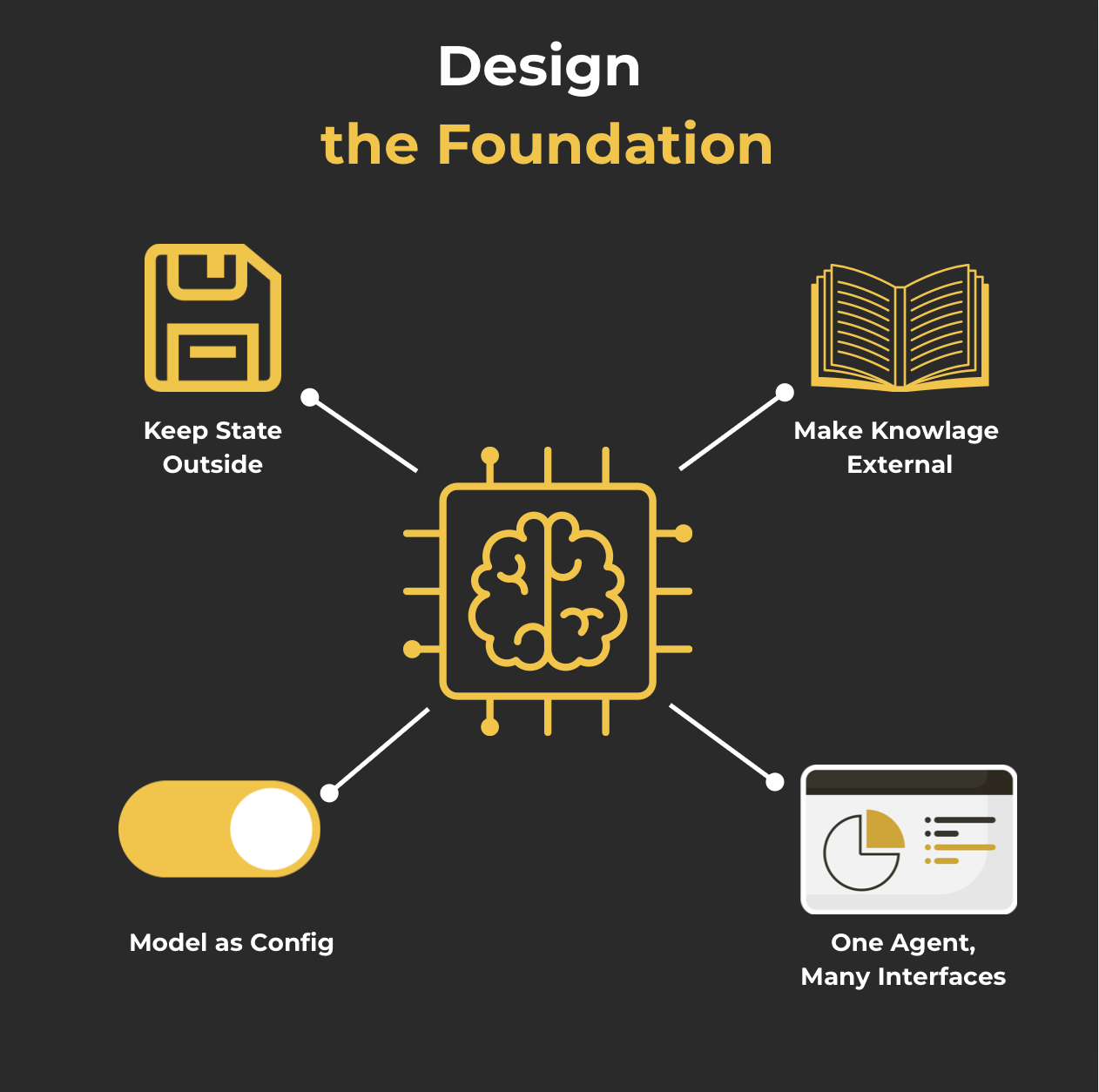
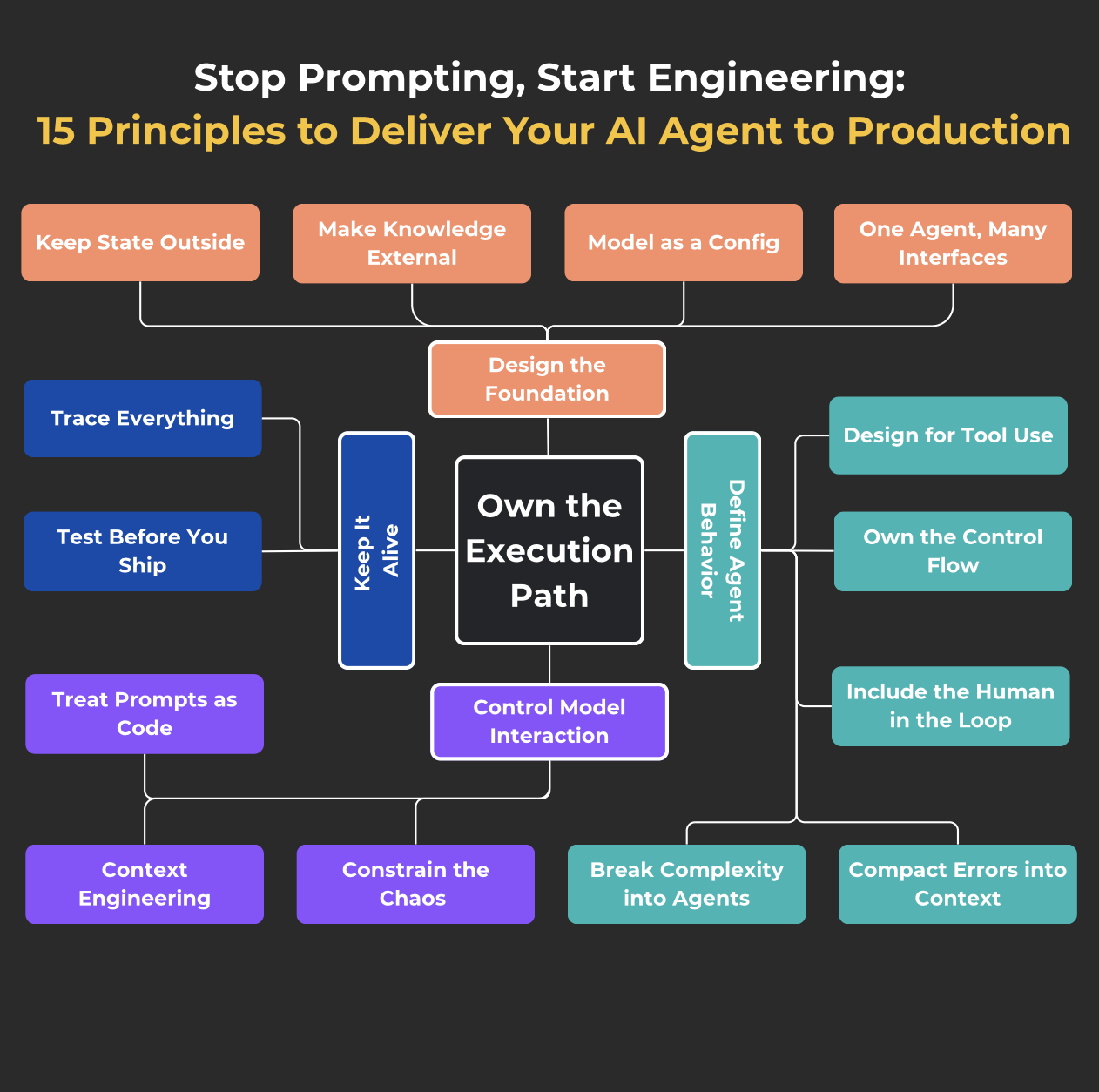
1. Разработка фундамента
Ранние версии агентов обычно собираются быстро: несколько функций, пара подсказок - и, эй, это работает.
«Если это работает, зачем это усложнять?»
Вначале всекажетсястабильный. Агент отвечает, выполняет код, ведет себя разумно. Но как только вы переключите модель, перезапустите систему или подключите новый интерфейс - внезапно она станет нестабильной, непредсказуемой, трудно отлаживать.
И часто основная причина не в логике или подсказках, а гораздо раньше: разбитое управление памятью, жесткий персонал, без способа возобновить сеансы или единую жесткую точку входа.
В этом разделе проходит четыре ключевых принципа, которые помогут вам построить прочную основу - тот, который все остальное может безопасно вырасти на вершине.
1. Держите государство снаружи
Проблема:
- Вы не можете возобновить процесс.Если агент прерывается (аварий, тайм -аут, что угодно), он должен быть в состоянии точно поднять, где он остановился.
- Воспроизводимость ограничена.Вам нужен способ точно воспроизвести то, что произошло - для тестирования, отладки и других таких удовольствий.
Это не проблема, но все же:
- Параллелизация.Рано или поздно вы захотите параллелизировать логику агента. Может быть, ему нужно сравнить несколько вариантов в середине диалога («Что из них лучше?»). Может быть, вы хотите, чтобы это разветвлялось. Кто знает - ты будешь.
(Память - это целая отдельная проблема - мы скоро доберемся до этого)
Решение:Переместить состояниеснаружиАгент - в базу данных, кэш, слой хранения - даже файл JSON подойдет.
Контрольный список:
- Агент может быть запущен с любого шага, имея только Session_id - идентификатор сеанса - и внешнее состояние (например, сохраненные шаги в базе данных или файле JSON).На любом этапе вы можете прервать работу агента, перезапустить его (даже после того, как что -то изменило под капотом), и это будет работать так, как будто ничего не произошло
- Тестовый случай: прерванный агент не теряет контекст, после перезапуска результат тот же самый
- Состояние является сериализуем в любой момент без потери функциональности
- Вы можете подавать состояние нескольким случаям параллельно в середине диалога
2Сделайте знания внешними
Проблема: LLM не помнят. Даже в течение одного сеанса модель может забыть то, что вы уже объяснили, смешали этапы, потеряли поток разговора или запустить «заполнение» деталей, которых там не было. И кажется, что время продолжается, контекстное окно становится все больше и больше, восхищает нас новыми возможностями. LinkedIn полон постов, где люди сравнивают какую книгу или сколько часов видео YouTube теперь вписываются в новую модельную версию. Но все же, LLM не помнят, и вы должны быть готовы.
Особенно если:
- Диалог длинный
- Документы большие
- Инструкции сложны
- и жетоны все еще не бесконечны
Даже с увеличением контекста Windows (8K, 16K, 128K…), остаются проблемы:
- "Потерян в середине"- Модель уделяет больше внимания началу и конец (и может потерять детали с середины)
- Расходы- больше токенов = больше денег;
- И это все еще не подходит.Что означает, что будут потери, искажения или галлюцинации. До тех пор, пока трансформаторы работают над самопринятым с квадратичной сложностью (
O(n²)), это ограничение будет с нами.
Решение:Отдельная «рабочая память» от «хранения» - как в классических вычислительных системах. Агент должен иметь возможность работать с внешней памятью: хранить, извлекать, суммировать и обновить знания вне модели. Есть несколько архитектурных стратегий, и у каждого есть свои границы.
Подходы
Буфер памяти
Хранит последнийkСообщения Возьмите для быстрого прототипирования.
+Простых, быстрых, достаточно для коротких задач
-теряет важную информацию, не масштабируется, не помнит "вчера"
Суммизация памяти
Сжимает историю, чтобы больше соответствовать.
+экономия токенов, расширение памяти
-искажения, потеря нюансов, ошибки в многоэтапном сжатии
Тряпка (поколение поиска-аугментирования)
Получает знания из внешних баз данных. Большую часть времени вы будете здесь.
+масштабируемый, свежий, проверяемый
-сложная установка, чувствительная к качеству поиска, задержка
Графики знаний
Структурированные связи между сущностями и фактами. Всегда элегантный, сексуальный и тяжелый, вы все равно будете делать тряпку.
+Логика, объяснение, стабильность
-Высокий барьер для входа, сложность интеграции LLM
Контрольный список:
- Вся история разговоров доступна в одном месте (вне подсказки)
- Источники знаний регистрируются и могут быть использованы повторно
- История масштабируется без риска превышения окна контекста
3Модель как конфигурация
Проблема:LLM быстро развиваются; Google, Anpropic, Openai и т. Д. Постоянно выпускают обновления, гоняя друг против друга по разным тестам. Это праздник для нас, как инженеры, и мы хотим максимально использовать его. Наш агент должен быть в состоянии легко переключиться на лучшую (или, наоборот, более дешевую) модель беспрепятственно.
Решение:
- Реализовать конфигурацию модели_ид: Используйте параметр model_id в файлах конфигурации или переменных среды, чтобы указать используемой модели.
- Используйте абстрактные интерфейсы: Создайте интерфейсы или классы обертки, которые взаимодействуют с моделями через унифицированный API.
- Применить решения для промежуточного программного обеспечения(Тщательно - мы поговорим о фреймворках чуть позже)
Контрольный список:
- Замена модели не влияет на остальную часть кода и не влияет на функциональность агента, оркестровку, память или инструменты
- Добавление новой модели требует только конфигурации и, необязательно, адаптер (простой слой, который привносит новую модель в требуемый интерфейс)
- Вы можете легко и быстро переключить модели. В идеале - любые модели, как минимум - переключение в модельном семье
4Один агент, много интерфейсов: быть там, где пользователи
Проблема:Даже если изначально агент должен иметь только один интерфейс связи (например, пользовательский интерфейс), вы в конечном итоге захотите дать пользователям больше гибкости и удобства, добавив взаимодействие через Slack, WhatsApp или, осмелюсь сказать, SMS - что угодно. API может превратиться в CLI (или вам понадобится его для отладки). Встройте это в свой дизайн с самого начала; Сделайте возможным использовать ваш агент, где бы это ни было удобно.
Решение:Создание единого входного контракта: Разработать API или другой механизм, который будет служить универсальным интерфейсом для всех каналов. Хранить логику взаимодействия канала отдельно.
Контрольный список:
Агент вызывает из CLI, API, UI
Весь вход проходит через одну конечную точку/анализатор/схема
Все интерфейсы используют один и тот же входной формат
Ни один канал не содержит бизнес -логики
Добавление нового канала = только адаптер, без изменений в ядре
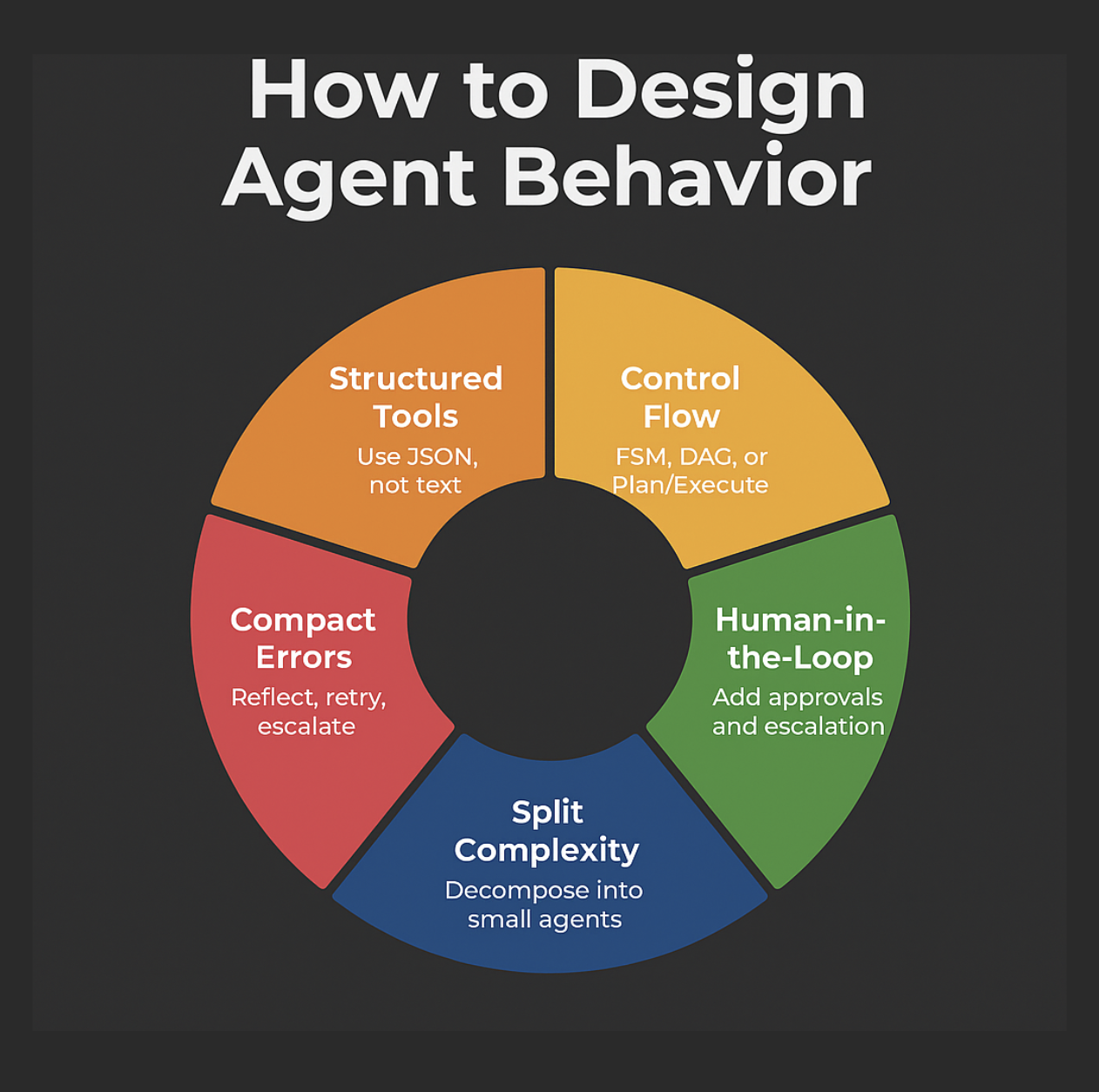
II Определить поведение агента
Хотя есть только одна задача, все просто, как в посты евангелистов ИИ. Но как только вы добавите инструменты, логику принятия решений и несколько этапов, агент превращается в беспорядок.
Он теряет отслеживание, не знает, что делать с ошибками, забывает назвать правильный инструмент - и вы снова остались одни с журналами, где «ну, все, кажется, там написано».
Чтобы избежать этого, агенту нужно четкоеповеденческая модель: Что он делает, какие инструменты у него есть, кто принимает решения, как люди вмешиваются и что делать, когда что -то пойдет не так.
Этот раздел охватывает принципы, которые помогут вам дать вашему агенту стратегию последовательного действия, вместо того, чтобы надеяться, что «модель как -то выяснит».
5Дизайн для использования инструмента
Проблема:Этот момент может показаться очевидным, но вы все еще сталкиваетесь с агентами, построенными на «простой подсказке + необработанного анализа выхода LLM». Это все равно, что пытаться контролировать сложный механизм, вытаскивая случайные строки и надеясь на лучшее. Когда LLM возвращают простой текст, который затем пытаемся проанализировать с помощью режима или струнных методов, мы сталкиваемся:
- Бриттли:Малейшее изменение в формулировке ответа LLM (добавлено слово, измененный порядок фразы) может сломать весь анализ. Это приводит к постоянной «гонке вооружений» между вашим кодом анализа и непредсказуемостью модели.
- Двусмысленность:Естественный язык по своей природе неоднозначен. То, что кажется очевидным для человека, может быть загадкой для анализатора. «Позвоните Джону Смиту» - который из трех Джона Смита в вашей базе данных? Какой у него номер?
- Сложность обслуживания:Код диапазона растет, становится запутанным и трудно отлаживать. Каждый новый агент «навык» требует написания новых правил анализа.
- Ограниченные возможности:Трудно сделать модель надежно вызовать несколько инструментов или пройти сложные структуры данных с помощью простого текстового вывода.
Решение:Модель возвращает JSON (или другой структурированный формат) - система выполняется.
Ключевая идея здесь - оставить ответственность заинтерпретациянамерение пользователя иВыборИнструменты для LLM, при этом все еще назначаяисполнениеэтого намерениясистемачерез четко определенный интерфейс.
К счастью, практически все поставщики (Openai, Google, Anpropic или кто бы ни вы предпочитаете) поддерживают так называемые"Функция вызова"или возможность генерировать выход в строго определенном формате JSON.
Просто чтобы обновить, как это работает:
- Описание инструмента:Вы определяете функции (инструменты) как схема JSON с именем, описание, параметры. Описание важно - модель полагается на нее.
- Переходя в LLM:При каждом вызове модель получает схемы инструментов вместе с подсказкой.
- Вывод модели:Вместо текста модель возвращает JSON с:
- Имя функции для вызова
- Аргументы - параметры в соответствии со схемой
- Исполнение:Код проверяет JSON и вызывает соответствующую функцию с параметрами.
- Ответ модели (необязательно):Результат выполнения возвращается в LLM для окончательного генерации ответов.
Важный:Описания инструментов также являются подсказками. Неясно описание = неверный выбор функции.
Что делать без вызова функций?
Если модель не поддерживает звонки инструментов или вы хотите избежать их по какой -то причине:
- Попросите модель вернуть JSON в подсказке. Обязательно укажите формат; Вы можете добавить примеры.
- Проанализируйте ответ и проверяйте его чем -то вроде Pydantic. Есть настоящие поклонники этого подхода.
Контрольный список:
- Ответ строго формализован (например, JSON)
- Используются схемы (схема json или пидбантику)
- Проверка применяется перед вызовами функций
- Ошибки генерации не вызывают поломки (существует обработка ошибок в формате)
- Llm = выбор функции, выполнение = код
6. Соблюдение потока управления
Проблема:Обычно агенты работают как «диалоги» - сначала говорит пользователь, тогда агент отвечает. Это как играть в Ping-Pong: хит-ответ. Удобно, но ограничивает.
Такой агент не может:
- Делать что -то самостоятельно без запроса
- Выполнять действия параллельно
- Планировать шаги заранее
- Сделайте несколько шагов в последовательности
- Проверьте прогресс и вернитесь к неудачным шагам
Вместо этого агент должен управлять своим собственным «поток выполнения» - зарегистрировать, что делать дальше и как это сделать. Это похоже на планировщик задач: агент смотрит на то, что нужно сделать, и выполняет шаги по порядку.
Это означает агент:
- решает, когда делать что -то самостоятельно
- может предпринять шаги один за другим
- может повторить неудачные шаги
- может переключаться между задачами
- может работать даже без прямых запросов
Решение:Вместо того, чтобы позволить LLM управлять всей логикой, мы извлекаемуправление потокомв код. Модель помогает только в пределах шагов или предлагает следующий. Это переход от «письменных подсказков» кИнженерная системас контролируемым поведением.
Давайте посмотрим на три популярных подхода:
1. FSM (конечные государственные машины)
- Что это такое:Задача разбита на состояния и четкие переходы.
- LLM:Определяет следующий шаг или действия в состоянии.
- Плюсы:Простота, предсказуемость, хорошо для линейных сценариев.
- Инструменты:Stateflow, конфигурации YAML, шаблон состояния.
2. DAG (направленные графики)
- Что это такое:Нелинейные или параллельные задачи как график: узлы-это действия, края являются зависимостями.
- LLM:Может быть узел или помощь в строительстве плана.
- Плюсы:Гибкость, параллелизм, визуализируемый.
- Инструменты:Langgraph, Trellis, Llmcompiler, Custom DAG -диаграммы.
3. Планировщик + исполнитель
- Что это такое:LLM создает план, код или другие агенты выполняют его.
- LLM:«Большие» планы, которые можно исполнить маленькие ».
- Плюсы:Разделение проблем, контроль затрат, масштабируемость.
- Инструменты:Langchain Plan и Execute.
Почему это важно:
- УвеличиваетсяуправляемостьВнадежностьВмасштабируемостьПолем
- Позволяет объединить различные модели и ускорить выполнение.
- Поток задач становится визуализируемым и тестируемым.
Контрольный список:
- Использует FSM, DAG или сценарий с явными переходами
- Модель решает, что делать, но не контролирует поток
- Поведение может быть визуализировано и протестировано
- Обработка ошибок встроена в поток
7Включите человека в петлю
Проблема:Даже если агент использует структурированные инструменты и имеет четкий поток управления, полная автономия агентов LLM в реальном мире все еще является скорее мечтой (или кошмаром, в зависимости от контекста). LLMS не обладает истинным пониманием и ни за что не ответственны. Они могут и будут принимать неоптимальные решения. Особенно в сложных или неоднозначных ситуациях.
Основные риски полной автономии:
- Постоянные ошибки:Агент может выполнять действия с серьезными последствиями (удалить данные, отправить неверное сообщение важному клиенту, начать восстание робота).
- Нарушения соответствия:Агент может случайно нарушить внутренние правила, юридические требования или повредить пользовательским чувствам (если это был не план, игнорировать этот момент).
- Отсутствие здравого смысла и этики:LLMS может пропустить социальные нюансы или действовать против «здравого смысла».
- Потеря доверия пользователя:Если агент совершает частые ошибки, пользователи перестанут доверять ему.
- Аудит и сложность ответственности:Кто виноват, когда автономный агент "облажается"?
Решение:Стратегическое вызов форм жизни на основе углеродаИнтегрировать людей в процесс принятия решений на ключевых этапах.
Параметры реализации HITL
1. Поток утверждения
- Когда:действие является критическим, дорогим, необратимым
- Как:Агент формулирует предложение и ожидает подтверждения
2. Удостоит маршрутизация
- Когда:модель неопределенна
- Как:
- Самооценка (logits, llm-as-a-judge, p (ik))
- эскалация, когда уверенность падает ниже порога
3. Человек-как-репутация
- Когда:Недостаточные данные или неясная формулировка запроса
- Как:Агент просит разъяснения (например, Humantool в Crewai)
4. Отсутствие эскалации
- Когда:Повторная ошибка или неразрешимая ситуация
- Как:Задача передается оператору с контекстом
5. RLHF (человеческая обратная связь)
- Когда:для улучшения модели
- Как:Человек оценивает ответы, они идут на тренировку
Контрольный список:
- Действия, требующие утверждения, определены
- Есть механизм оценки доверия
- Агент может задавать вопросы людям
- Критические действия требуют подтверждения
- Есть интерфейс для ввода ответов
8Компактные ошибки в контексте
Проблема:Стандартное поведение многих систем, когда возникает ошибка, заключается в том, чтобы «сбой», либо просто сообщать об ошибке и остановки. Для агента, который должен автономно решать задачи, это не лучшая поведенческая модель. Но мы также не хотим, чтобы это галлюцинировало вокруг проблемы.
Чем мы столкнемся:
- Бриттли:Любая сбой во внешнем инструменте или неожиданный ответ LLM может остановить весь процесс или сбиться с ним.
- Неэффективность:Постоянные перезагрузки и ручное вмешательство съедают время и ресурсы.
- Неспособность учиться (в широком смысле):Если агент не «видит» свои ошибки в контексте, он не может попытаться исправить их или адаптировать свое поведение.
- Галлюцинации. Снова.
Решение:Ошибки включены в приглашение или память. Идея состоит в том, чтобы попробовать внедрить какой-то «самовосстановление». Агент должен хотя бы попытаться исправить свое поведение и адаптироваться.
Грубый поток:
- Понимание ошибки
- Самокоррекция:
- Механизмы самокоррекции:Обнаружение ошибок, отражение, логика повторения, повторение изменений (агент может изменить параметры запроса, перефразировать задачу или попробовать другой инструмент)
- Влияние типа отражения:Более подробная информация об ошибках (инструкции, объяснения) обычно приводит к лучшим результатам самокоррекции. Даже простое знание предыдущих ошибок повышает производительность.
- Внутренняя самокоррекция:Обучение LLMS для самокоррекции путем введения ошибок и их исправлений в учебные данные.
- Запросить помощь человеческим:Если самокоррекция не удается, агент обостряет проблему человеку (см. Принцип 7).
Контрольный список:
- Ошибка предыдущего шага сохраняется в контексте
- Испытайте логику
- Запасная/человеческая эскалация используется для повторных сбоев
9Разорвать сложность на агентов
Проблема:Давайте вернемся к ограничению ключа LLM (это контекстное окно), но посмотрим на эту проблему под другим углом. Чем больше и сложнее задача, тем больше шагов будет предпринять, что означает более длительное контекстное окно. По мере роста контекста LLM с большей вероятностью потеряются или потеряют фокус. Сфокусируя агенты на конкретных доменах с 3-10, возможно, максимум 20 шагов, мы поддерживаем управляемые контекст Windows и высокую производительность LLM.
Решение:Используйте меньшие агенты, нацеленные на определенные задачи. Один агент = одна задача; оркестровка сверху.
Преимущества мелких, целенаправленных агентов:
- Управляемый контекст:Меньшие контекстные окна означают лучшую производительность LLM
- Явные обязанности:У каждого агента есть четко определенная область и цель
- Лучшая надежность:Меньше шансов заблудиться в сложных рабочих процессах
- Более простое тестирование:Легче тестировать и проверять конкретную функциональность
- Улучшенная отладка:Легче идентифицировать и исправлять проблемы, когда они возникают
К сожалению, нет четкой эвристики для понимания, когда кусок логики уже достаточно большой, чтобы разделить на несколько агентов. Я уверен, что, пока вы читаете этот текст, LLMS стала умнее где -то в лабораториях. И они продолжают становиться все лучше и лучше, поэтому любая попытка формализовать эту границу обречена с самого начала. Да, чем меньше задача, тем проще она, но чем больше она становится, тем лучше реализуется потенциал. Правильная интуиция будет только с опытом. Но это не уверено.
Контрольный список:
Сценарий построен из вызовов микросервиса
Агенты могут быть перезапущены и протестированы отдельно
Агент = минимальная автономная логика. Вы можете объяснить, что он делает в 1-2 предложениях.
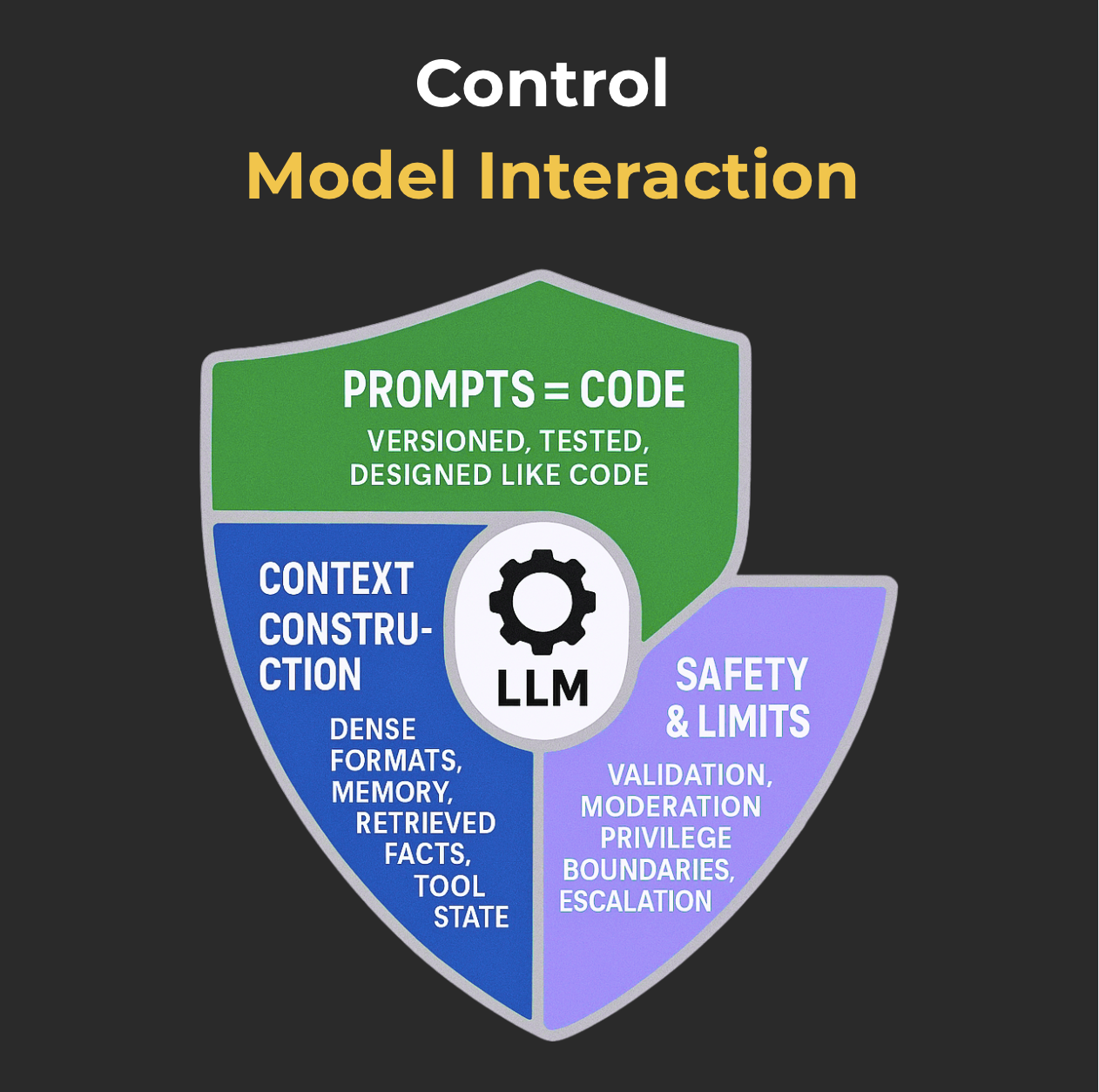
Iii. Взаимодействие модели управления
Модель обрабатывает генерацию. Все остальное на вас.
Как вы сформулировали запрос, то, что вы передали в контексте, какие инструкции вы дали, - все это определяет, будет ли результат согласованным или «творческим».
LLM не читают умы. Они читают токены.
Это означает, что любая ошибка ввода превращается в выходную ошибку - просто не сразу заметно.
Этот раздел о том, чтобы не позволить всему дрейфу: refts = код, явное управление контекстом, ограничение модели в пределах границ. Мы не надеемся, что LLM "выяснит это самостоятельно".
10. рассматривать подсказки как код
Проблема:Очень распространенный паттерн, особенно среди людей без ML или SE фона, хранит подсказки непосредственно в коде. Или в лучшем случае, несистематическое хранилище во внешних файлах.
Этот подход приводит к нескольким трудностям в обслуживании и масштабировании:
- Навигация, понимание и модификация усложняются по мере роста сложности проекта и количества подсказок.
- Без явного управления версиями очень трудно отслеживать Evolution, причины изменений и возвращаться к предыдущим стабильным версиям в случае снижения производительности.
- Неэффективное улучшение и процесс отладки:Обратная оптимизация без объективных показателей и тестирования становится субъективным и трудоемким процессом с нестабильными результатами.
- Восприятие другими членами команды становится сложным, включая (и особенно) будущее вас.
Решение:Подсказки в этом контексте не сильно отличаются от кода, и к ним следует применять одну и ту же базовую инженерную практику
Это подразумевает:
- Хранить отдельно и систематически, используя специализированные файлы (например,
.txtВ.mdВ.yamlВ.json) или даже системы управления шаблонами (например, Jinja2, руль или специализированные инструменты, такие как BAML). - Явное приглашение версий. После этого вы даже можете сделать A/B -тесты с разными версиями.
- Тестирование. Вы слышали это правильно.
- Это может быть что -то вроде модульных тестов, где вы сравниваете ответы LLM с конкретными входными данными с эталонными ответами или ожидаемыми характеристиками в зависимости от приглашения
- Наборы данных оценки
- Проверки соответствия формату и наличие/отсутствие ключевых элементов - например, если подсказка должна вернуть JSON, тест может подтвердить его структуру
- Даже LLM-как сужу, если ваш проект и дизайн оправдывают его.
Мы поговорим о тестировании более подробно в Принсипи 14.
Контрольный список:
- Подсказки хранятся в отдельных файлах, отдельно от бизнес -логики
- Есть Diff и история изменений
- Используются тесты (по мере необходимости)
- (Необязательно) Как насчет быстрого обзора в рамках проверки кода?
11Контекст инженерия
Проблема:Мы уже обсуждали «забывчивость» LLM, частично решав это, разгружая историю на внешнюю память и используя разные агенты для разных задач. Но это еще не все. Я предлагаю, чтобы мы также рассмотрели явное управление окнами контекста (и здесь я не просто говорю о сжатии истории, чтобы соответствовать оптимальному размеру или включая ошибки из предыдущих шагов в контексте).
Стандартные форматы не всегда оптимальные:Простой список сообщений в «ролевом контенте» (system/user/assistant) Формат является базовым, но он может быть тяжелым, недостаточно информативным или плохим в передаче сложного состояния вашего агента.
Большинство клиентов LLM используют стандартный формат сообщения (список объектов сrole: «Система», «Пользователь», «Помощник»,content, а иногдаtool_callsполя).
Хотя это «отлично работает для большинства случаев», чтобы достичьмаксимальная эффективность(С точки зрения как токенов, так и внимания модели) мы можем подходить к формированию контекста более творчески.
Решение:Чтобы разработать это. Чтобы обратиться к созданию всего информационного пакета, переданного в LLM как«Контекстная инженерия».Это означает:
- Полный контроль:Принимая полное право собственности на то, какую информацию входит в окно контекста LLM, в какой форме, томе и последовательности.
- Создание пользовательских форматов:Не ограничивая себя стандартными списками сообщений. Разработка наших собственных, оптимизированных задач способов представления контекста. Например, вы можете рассмотреть вопрос о использовании XML-подобной структуры для плотного упаковки различных типов информации (сообщений, инструментов, их результатов, ошибок и т. Д.) В одно или несколько сообщений.
- Целостный подход:Просмотр контекста не только как история диалога, но и как сумма всего всего, что может потребоваться модели: непосредственная подсказка, инструкции, данные из RAG Systems, история вызовов инструментов, состояние агента, память от других взаимодействий и даже инструкции по желаемому формату вывода.
(Вместо контрольного списка)Как узнать, когда это имеет смысл?
Если вы заинтересованы в любом из следующих действий:
- Информационная плотность.Максимальное значение с минимальным шумом.
- Экономическая эффективность.Сокращение количества токенов, где мы можем получить сопоставимое качество по более низкой цене.
- Улучшенная обработка ошибок.
- Безопасность.Обработка включения конфиденциальной информации, ее управление, фильтрация ее, и заканчивая все это путем вывода классического ответа «Извините, я просто мягкая модель с большой большой языком».
12. Ограничьте хаос: безопасные входы, охраняемые действия и заземленные выходы
Проблема:Мы уже многое сделали во имя стабильности, но ничто не является серебряной пулей. Это означает, что стоит взглянуть на самые важные потенциальные проблемы отдельно и явно взять некоторую «страховку».
В этом принципе мы думаем:
- Возможная оперативная инъекция.Если ваш агент будет напрямую общаться с пользователем, вы должны контролировать то, что кормит как вход. В зависимости от типа пользователя, вы можете получить того, кто хочет сломать ваш поток и заставить агента игнорировать его первоначальные цели, предоставить неправильную информацию, выполнять вредные действия или генерировать вредоносный контент.
- Конфиденциальная утечка данных.По причине выше, или возглавляемой «Голосами в его голове», агент может раскрыть важную информацию, такую как личные данные пользователей, корпоративные секреты и т. Д.
- Поколение токсичного или злонамеренного содержания.Если это по дизайну, не обращайте внимания на этот момент.
- Придумываясь, когда информация отсутствует.Вечная боль.
- Выходя за рамки разрешенных границ.Восстание машин, помните? А если серьезно, в процессе рассуждения агент может прийти к очень нетривиальным решениям, не все из которых будут находиться в рамках нормального поведения.
Безопасность и заземление агента LLM не единственная мера, а многослойная система защиты («защита»), которая охватывает весь жизненный цикл взаимодействия. Угрозы разнообразны, и ни один метод защиты не является панацеей. Эффективная защита требует комбинации методов.
Решение:Мы должны посвятить себя многослойной системе обороны, продумывать и явно обрабатывая все угловые дела и потенциальные сценарии, а также иметь четкий отклик, готовый к тому, что может произойти.
В базовой настройке вы должны рассмотреть:
Безопасные входы.
- Проверьте на известные фразы атаки-индикатора (например, «Игнорируйте все предыдущие инструкции»). Иногда имеет смысл бороться с потенциальным запутыванием.
- Попробуйте определить намерение пользователя отдельно. Вы можете использовать другой LLM для этого, чтобы проанализировать вход для текущего.
- Ввод управления из внешних источников, даже если они являются вашими собственными инструментами.
Охраняемые действия.Управляйте привилегиями как агента, так и его инструментов (предоставление минимально необходимого), четко определяйте и ограничивайте список доступных инструментов, проверяйте параметры на входе в инструменты и включите принцип № 7 (человек в цикле).
Выходная модерация.Разработайте систему проверки на то, что выходит модель, особенно если она идет непосредственно к пользователю. Это могут быть проверки для актуальности (гарантируя, что модель использует то, что находится в тряпке, и не просто делает вещи), а также проверки на общую уместность. Есть также готовые решения (например, API модерации OpenAI).
Окончательная система, однако, зависит от ваших задач и оценки риска. В контрольном списке мы постараемся набросить некоторые варианты.
Контрольный список:
Проверка ввода пользователя существует.
Для задач, требующих фактической информации, используются данные в тряпке.
Подсказка для LLM в тряпичной системе явно инструктирует модель основать свой ответ в извлеченном контексте.
Выходная фильтрация LLM реализуется для предотвращения утечки PII (лично идентифицируемой информации).
Ответ включает в себя ссылку или ссылку на источник.
Выходная модерация LLM для нежелательного контента реализована.
Агент и его инструменты работают в соответствии с принципом наименьшей привилегии.
Действия агента контролируются с HITL (человеком в петле) для критических операций.
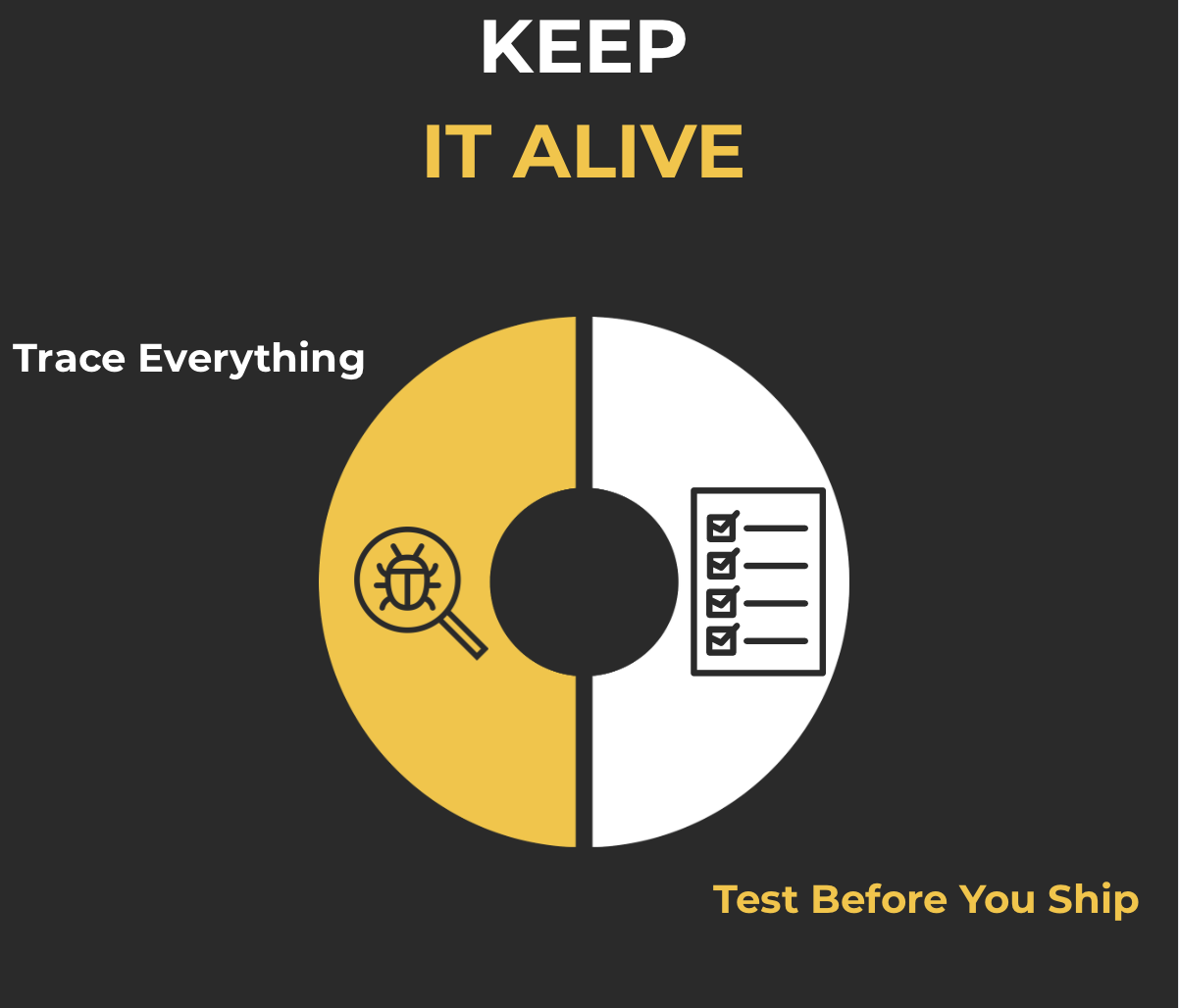
IV Сохранить это в живых
Агент, который «вроде работает», является ошибкой с отсроченным эффектом.
В Prod не все ломается одновременно. И вы не узнаете об этом мгновенно. Иногда вы вообще не узнаете.
Этот раздел посвящен инженерной привычкеВидя, что происходитиПроверка, что все еще работаетПолем Журналы, отслеживание, тесты - все, что делает поведение агента прозрачным и надежным, даже если вы спите или развиваете своего следующего агента.
13. проследить все
Проблема:Так или иначе, вы будете постоянно сталкиваться с ситуациями, когда агент не работает, как вы ожидали. Во время разработки, тестирование, внесение изменений или во время нормальной работы. Это неизбежно, и в настоящее время это нормально в некоторой степени. Это означает, что вы обречены проводить часы и дни, отладку, пытаясь понять, что не так, воспроизводит проблему и исправляя ее. Я хотел бы думать, что к этому моменту вы уже реализовали принцип № 1 (сохранить состояние снаружи) и № 8 (компактные ошибки в контексте). В большинстве случаев этого будет достаточно, чтобы сделать вашу жизнь намного проще. Некоторые другие принципы также будут косвенно помогать здесь.
Несмотря на это (и особенно если вы решили не беспокоиться о них сейчас), имеет смысл задумываться о отладке заранее и спасение времени и нервов в будущем, придерживаясь этого принципа.
Решение:Войдите по всему пути от запроса к действию. Даже если у вас уже есть журналы для отдельных компонентов, отслеживание всей цепи может быть хлопотом. Даже если вы большой поклонник головоломков или Lego, в какой -то момент это перестанет быть веселым. Следовательно, журналы должны существовать, они должны быть сквозными, и они должны покрывать все.
Зачем это нужно:
- Отладка- быстро найдите, где все пошло не так. Это причина, по которой этот принцип существует.
- Аналитика- Посмотрите, где находятся узкие места и как улучшить.
- Оценка качества- Посмотрите, как изменения влияют на поведение.
- Воспроизводимость- Вы можете точно восстановить шаги.
- Аудит- журнал всех агентских решений и действий.
Основной «набор джентльменов» выглядит так:
- Вход:Первоначальный запрос пользователя, параметры, полученные с предыдущего шага.
- Агентное состояние:Ключевые переменные состояния агента перед выполнением шага.
- Быстрый:Полный текст подсказки, отправленного в LLM, включая системные инструкции, историю диалога, извлеченный контекст Rag, описания инструментов и т. Д.
- Вывод LLM:Полный, сырой ответ от LLM, перед каким -либо анализом или обработкой.
- Инструментальный звонок:Если LLM решил вызвать инструмент - имя инструмента и точные параметры, с которыми он был вызван (в соответствии со структурированным выходом).
- Результат инструмента:Ответ, который вернул инструмент, включая успешные результаты и сообщения об ошибках.
- Решение агента:Какое решение приняло агент на основе ответа LLM или результата инструмента (например, какой следующий шаг для выполнения, какой ответ дать пользователю).
- Метаданные:Время выполнения шага, используемая модель LLM, стоимость вызова (если доступно), версия кода/приглашения.
Примечание:Посмотрите на существующие инструменты отслеживания; При определенных условиях они сделают вашу жизнь намного проще. Например, Langsmith предоставляет подробную визуализацию цепочек вызовов, подсказок, ответов и использования инструментов. Вы также можете адаптировать такие инструменты, как ариз, веса и смещения, Opentelemetry и т. Д. Для ваших потребностей. Но сначала см. Принцип № 15.
Контрольный список:
- Все шаги агента зарегистрированы (ваша версия «набора джентльменов»).
- Шаги связаны
session_idиstep_idПолем - Есть интерфейс для просмотра всей цепи.
- Подсказка, отправленная в LLM, может быть воспроизведена на любом этапе.
14Проверьте перед отправкой
Проблема:К этому моменту, скорее всего, у вас есть какое -то практически готовое решение. Это работает, может быть, даже так, как вы хотели. Отправить его, чтобы продувать? Но как мы это гарантируемсохраняетработающий? Даже после следующего незначительного обновления? Да, я привожу нас к теме тестирования.
Очевидно, что обновления в системах LLM, как и в любом другом-изменяются ли они в код приложения, обновления наборов данных для точной настройки или тряпки, новой версии базового LLM или даже незначительных корректировок подсказки-часто приводят к непреднамеренным разрывам в существующей логике и неожиданном, иногда разрушающемся поведении агента. Традиционные подходы к тестированию программного обеспечения оказываются недостаточными для комплексного контроля качества систем LLM. Это связано с рядом рисков и характеристик, специфичных для крупных языковых моделей:
- Модель дрифта.Вы ничего не сделали, но производительность со временем упала. Возможно, поставщик обновил свою модель, возможно, характер входных данных изменился (дрейф данных) - что вчера сработало сегодня.
- Быстрое хрупкость.Даже небольшое изменение в подсказке может сломать установленную логику и исказить вывод.
- Недотерминизм LLMS:Как вы знаете, многие LLM являются нетерминированными (особенно с
temperature > 0), что означает, что они будут генерировать различные ответы на один и тот же ввод на каждом вызове. Это усложняет создание традиционных тестов, которые ожидают точного совпадения и затрудняют воспроизведение ошибок. - Сложность в воспроизведении и отладке ошибок.Вам будет легче, если вы реализовали первый принцип, но воспроизведение конкретной ошибки для отладки может быть затруднено даже при фиксированных данных и состояниях.
- «Эффект бабочки».В сложных системах обновление одного элемента (например, модель или подсказки) может касаться через цепочку API, баз данных, инструментов и т. Д., И привести к изменению поведения в других местах.
- Галлюцинации.
... и я полагаю, мы могли бы продолжать. Но мы уже понимаем, что традиционные тесты, сосредоточенные на проверке явной логики кода, не полностью способны охватить эти проблемы.
Решение:Нам придется разработать сложный, всеобъемлющий подход, который охватывает многие вещи, сочетающие классические и специфичные для области решений. Это решение должно учитывать следующие аспекты:
- Многоуровневое тестирование:Комбинация различных типов тестов, нацеленных на различные аспекты системы: от модульных тестов низкого уровня для отдельных функций и подсказков к сложным сценариям, которые проверяют сквозный рабочий процесс агента и взаимодействие с пользователем.
- Сосредоточьтесь на поведении и качеством LLM:Тестирование должно оценивать не только функциональную правильность, но и качественные характеристики ответов LLM, таких как актуальность, точность, когерентность, отсутствие вредного или предвзятого содержания, а также приверженность инструкциям и данному стилю.
- Испытания на регрессию и качествоЭто включает в себя «золотые наборы данных», содержащие различные примеры ввода и эталонные (или приемлемые диапазоны) выходов.
- Автоматизация и интеграция в CI/CD.
- Оценка человека в петле:Конкретные этапы LLM-Eval должны включать человека для калибровки метрик и рассмотрения сложных или критических случаев.
- Итеративный подход к быстрому развитию и тестированию:Обратная техника должна рассматриваться как итеративный процесс, когда каждая версия подсказки тщательно протестирована и оценивается перед реализацией.
- Тестирование на разных уровнях абстракции:
- Тестирование компонентов:Отдельные модули (анализаторы, валидаторы, вызовы API) и их интеграция.
- Быстрое тестирование:Изолированное тестирование подсказок на различных входах.
- Тестирование цепи/агента:Проверка логики и взаимодействия компонентов в агенте.
- Сквозное тестирование системы:Оценка выполнения полных пользовательских задач.
Контрольный список:
Логика разбивается на модули: функции, подсказки, API - все тестируются отдельно и в комбинации.
Качество ответа проверяется на сравнительных данных, оценка значения, стиля и правильности.
Сценарии охватывают типичные и краевые случаи: от обычных диалогов до сбоев и провокационных входов.
Агент не должен выйти из строя из -за шума, ошибочного ввода или быстрого инъекций - все это проверяется.
Любые обновления проводятся через CI и контролируются в Prod - поведение агента не должно меняться незамеченным.
Принцип 15: владеть пути исполнения
Это мета-принцип; Он проходит через все перечисленные выше.
К счастью, сегодня у нас есть десятки инструментов и структур для любой задачи. Это здорово, это удобно, и это ловушка.
Почти всегда выбор готового решения означаеткомпромисс: вы получаете скорость и легкое начало, но вы проигрываетегибкость, контроль и, возможно, безопасностьПолем
Это особенно важно в разработке агентов, где важно управлять:
- непредсказуемость LLM,
- сложная логика для переходов и самокоррекции,
- быть готовым к адаптации и эволюции системы, даже если ее основные задачи остаются неизменными.
Фреймворки приносятинверсия контроля: Они решают для вас, как должен работать агент. Это может упростить прототип, но усложнить его долгосрочное развитие.
Многие из принципов, описанных выше, могут быть реализованы с использованием готовых решений-и это часто оправдано. Но в некоторых случаяхЯвная реализация основной логики занимает сопоставимое количество времении обеспечивает несравненно большепрозрачность, управляемость и адаптивностьПолем
Противоположная крайность также существует - существует -чрезмерное инженерное образование, желание написать все с нуля. Это также ошибка.
Вот почему ключ - баланс.Инженер выбирает для себя: где разумно полагаться на структуру и где важно поддерживать контроль. И они принимают это решение сознательно, понимая стоимость и последствия.
Вы должны помнить: индустрия все еще обретает форму. Многие инструменты были созданы до появления текущих стандартов. Завтра они могут устареть, но ограничения, выпеченные в вашей архитектуре сегодня, останутся.
Заключение
Ладно, мы превзошли 15 принципов, которые показывают опыт, помогают превратить первоначальное волнение «Это жива!» В уверенность в том, что ваш агент LLM будет работать в стабильном, предсказуемом и полезном способе в реальных условиях.
Вы должны рассмотреть каждый из них, чтобы увидеть, имеет ли смысл применить его к вашему проекту. В конце концов, это ваш проект, ваша задача и ваше творение.
Ключевые выводы, чтобы носить с собой:
- Инженерный подход является ключевым:Не полагайтесь на «магию» LLMS. Структура, предсказуемость, управляемость и тестируемость - ваши лучшие друзья.
- LLM является мощным компонентом, но все же просто компонент:Обратитесь в LLM как к очень умному, но, тем не менее, единый компонент вашей системы. Контроль над общим процессом, данными и безопасностью должен оставаться с вами.
- Итерация и обратная связь - ключи к успеху:Редко создать идеальный агент с первой попытки. Будьте готовы к экспериментам, измерениям, анализу ошибок и постоянному улучшению - как самого агента, так и для ваших процессов разработки. Включение человека в цикл (Хитл) - это не только безопасность; Речь также о наличии бесценного источника обратной связи для обучения.
- Сообщество и открытость:Поле агентов LLM быстро развивается. Следите за новыми исследованиями, инструментами и лучшими практиками и поделитесь своим собственным опытом. Многие из проблем, с которыми вы столкнетесь, кто -то уже решил или решает прямо сейчас.
Я надеюсь, что вы нашли здесь что -то новое и полезное, и, возможно, вы даже захотите вернуться к этому, создавая вашего следующего агента.
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)