

Статический полнотекстовый поиск в Next.js с фильтрами WebAssembly, Rust и Xor
9 апреля 2022 г.TL;DR
- 🦀 Для разработки WebAssembly на Rust имеется богатый набор инструментов. Это весело!
- 🤝 WebAssembly и Next.js довольно хорошо работают вместе, но помните об известных проблемах.
- 🧑🔬 Фильтры Xor — это структуры данных, которые обеспечивают высокую эффективность использования памяти и быстрый поиск существования значения.
- 🧑🍳 Производительность WebAssembly и размер кода не гарантируются. Обязательно измеряйте и оценивайте.
Я всегда знал, что мне нужна функция полнотекстового поиска статей в моем портфолио, чтобы предоставить посетителям быстрый доступ к интересующему их контенту. После миграции на Contentlayer , это уже не кажется таким надуманным. Вот я и начал изучать🚀
Вдохновлен tinysearch: полнотекстовая поисковая система WebAssembly
После некоторых исследований я нашел поисковую систему под названием «tinysearch». Это статическая поисковая система, созданная с помощью [Rust] (https://www.rust-lang.org/) и [WebAssembly] (https://webassembly.org/) (Wasm). Автор Матиас Эндлер написал потрясающий пост в блоге о том, как появился tinysearch.
Мне понравилась идея создания минималистичной поисковой системы во время сборки и отправки ее в браузеры в оптимизированном низкоуровневом коде. Поэтому я решил использовать tinysearch в качестве схемы и написать свою собственную поисковую систему для интеграции с моим [статическим сайтом Next.js] (https://nextjs.org/).
Я настоятельно рекомендую прочитать кодовую базу tinysearch. Это очень хорошо написано. Реализация моей поисковой системы является ее упрощенной версией. Основная логика та же.
Как выглядит функция поиска?
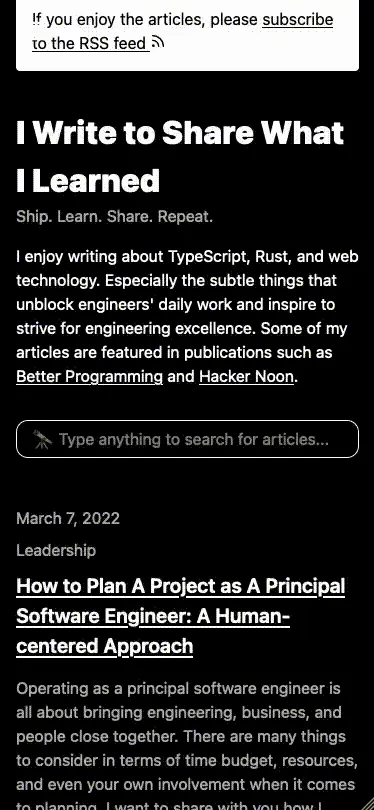
Очень просто:
- Пользователи вводят что-либо в поле поиска.
- Поисковая система ищет ключевые слова во всем содержании и находит наиболее релевантные статьи.
- Пользовательский интерфейс отображает ранжированный список результатов поиска.
Вы можете попробовать функцию поиска на странице статей!
Немного статистики
На момент написания этой статьи существуют:
- 7 статей (еще больше🚀)
- 13 925 слов
- 682 КБ файлов данных (генерируются Contentlayer)
Чтобы полнотекстовый поиск работал на статических сайтах, стремящихся к скорости, размер кода должен быть небольшим.
Как работает функция полнотекстового поиска WebAssembly?
Большинство современных браузеров теперь поддерживают WebAssembly. Они могут запускать собственный код WebAssembly и двоичный код вместе с JavaScript.
Концепция функции поиска проста. Он принимает строку запроса в качестве параметра. В функции мы токенизируем запрос в условия поиска. Затем мы присваиваем рейтинг каждой статье в зависимости от того, сколько поисковых запросов она содержит. Наконец, мы ранжируем статьи по релевантности. Чем выше оценка, тем она более актуальна.
Поток выглядит так:
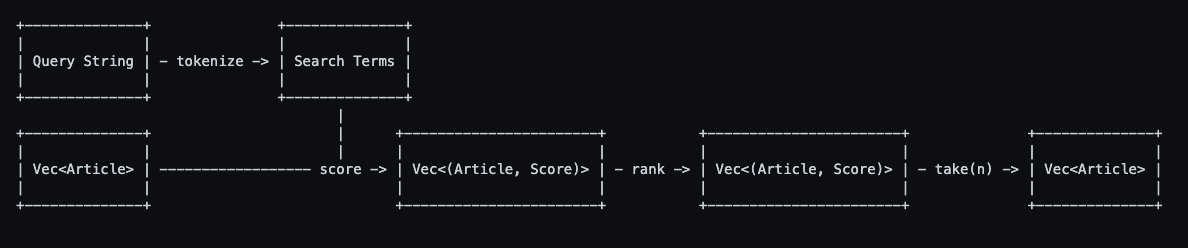
Оценка статей — это то место, где приходится больше всего вычислений. Наивным подходом было бы преобразование каждой статьи в набор хэшей, содержащий все уникальные слова в статье. Мы можем рассчитать оценку, просто подсчитав количество поисковых запросов в хеш-наборе.
Вы можете себе представить, что это не самый эффективный подход к памяти с набором хэшей. Есть лучшие структуры данных, чтобы заменить его: xor фильтры.
Что такое фильтры Xor?
Фильтры Xor – это относительно новые структуры данных, которые позволяют нам оценить, существует ли значение или нет. Это быстро и эффективно использует память, поэтому очень подходит для полнотекстового поиска.
Вместо того, чтобы хранить фактические входные значения, такие как набор хэшей, фильтры xor сохраняют отпечатки пальцев (L-битная хэш-последовательность) входных значений особым образом. /cs166.1216/lectures/13/Slides13.pdf#page=49). При поиске того, существует ли значение в фильтре, он проверяет, присутствует ли отпечаток значения.
Однако фильтры Xor имеют несколько недостатков:
- Фильтры Xor являются вероятностными, и есть шанс, что может произойти ложное срабатывание.
- Фильтры XOR не могут оценить наличие частичных значений. Таким образом, в моем случае полнотекстовый поиск сможет искать только полные слова.
Как я создавал фильтры Xor с помощью Rust?
Поскольку у меня были данные статьи, сгенерированные Contentlayer, я создал фильтры xor, передав им данные до сборки WebAssembly. Затем я сериализовал фильтры xor и сохранил их в файле. Чтобы использовать фильтры в WebAssembly, все, что мне нужно было сделать, это прочитать из файла хранилища и десериализовать фильтры.
Алгоритм создания фильтра выглядит следующим образом:

xorf crate — хороший выбор для реализации фильтров xor, поскольку он предлагает сериализацию/десериализацию и несколько функций, повышающих эффективность использования памяти и количество ложноположительных результатов. Он также предоставляет очень удобную структуру HashProxy для моего варианта использования, чтобы создать фильтр xor с фрагментом строк. Написанная на Rust конструкция примерно выглядит так:
ржавчина
используйте std::collections::hash_map::DefaultHasher;
используйте xorf::{Filter, HashProxy, Xor8};
мод утилиты;
fn build_filter(title: String, body: String) -> HashProxy
let title_tokens: HashSet
let body_tokens: HashSet
пусть токены: Vec
HashProxy::from(&токены)
Если вас интересует реальная реализация, вы можете подробнее прочитать в репозитории.
Собираем все вместе
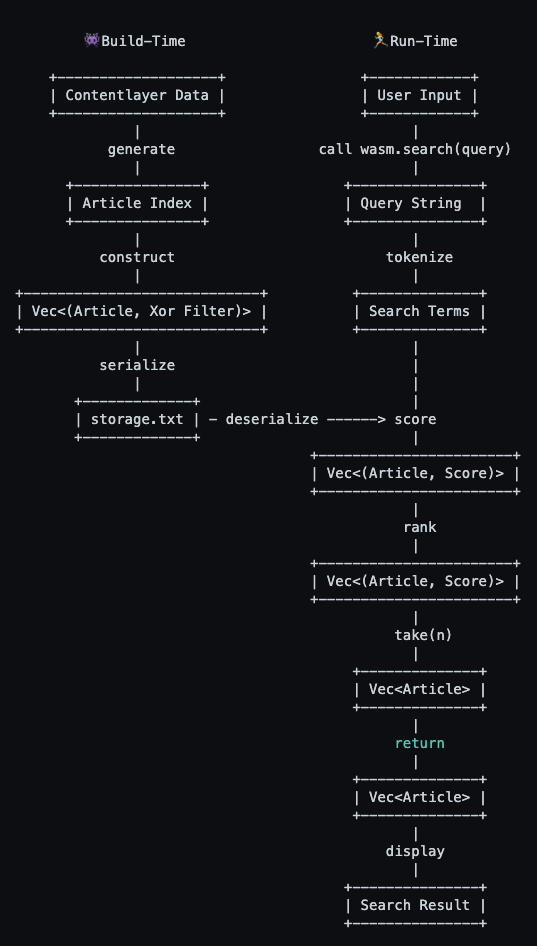
Интеграция WebAssembly в Next.js
Вот как я интегрировал скрипт генерации фильтра xor и WebAssembly в Next.js.
Структура файла выглядит следующим образом:
мое портфолио
├── next.config.js
├── страницы
├── скрипты
│ └── полнотекстовый поиск
├── компоненты
│ └── Search.tsx
└── васм
└── полнотекстовый поиск
Для поддержки WebAssembly я обновил конфигурацию Webpack, чтобы загружать модули WebAssembly как асинхронные модули. Чтобы заставить его работать для создания статического сайта, мне понадобился [обходной путь] (https://github.com/vercel/next.js/issues/25852) для создания модуля WebAssembly в каталоге .next/server, чтобы статические страницы могут успешно выполнять предварительный рендеринг при запуске скрипта next build.
следующий.config.js
```javascript
веб-пакет: функция (конфигурация, { isServer }) {
// это делает модули WebAssembly асинхронными модулями
config.experiments = { asyncWebAssembly: true }
// сгенерировать модуль wasm в ".next/server" для ssr и ssg
если (сервер) {
config.output.webassemblyModuleFilename =
'./../static/wasm/[modulehash].wasm'
} еще {
config.output.webassemblyModuleFilename = 'static/wasm/[modulehash].wasm'
вернуть конфигурацию
Это все, что нужно для интеграции✨
Использование WebAssembly в компоненте React
Чтобы собрать модуль WebAssembly из кода Rust, я использую wasm-pack.
Сгенерированный файл .wasm и связывающий код для JavaScript находятся в wasm/fulltext-search/pkg. Все, что мне нужно было сделать, это использовать next/dynamic для их динамического импорта. Как это:
компоненты/Search.tsx
```машинопись
импортировать React, {useState, useCallback, ChangeEvent, useEffect} из 'реагировать'
импортировать динамический из «следующего/динамического»
введите Заголовок = строка;
введите URL = строка;
введите SearchResult = [Title, Url][];
константный поиск = динамический ({
загрузчик: асинхронный () => {
const wasm = await import('../../wasm/fulltext-search/pkg')
возврат () => {
const [термин, setTerm] = useState('')
const [результаты, setResults] = useState
const onChange = useCallback((e: ChangeEvent
setTerm (e.target.value)
использоватьЭффект(() => {
const pending = wasm.search(термин, 5)
setResults (в ожидании)
}, [срок])
возврат (
<дел>
<ввод
значение = {термин}
при изменении={при изменении}
placeholder="🔭 поиск..."
{results.map(([название, URL]) => (
экспорт по умолчанию Поиск
Оптимизация размера кода WebAssembly
Без какой-либо оптимизации исходный размер файла Wasm составлял 114,56 КБ. Я использовал Twiggy, чтобы узнать размер кода.
```javascript
Неглубокие байты │ Неглубокие % │ Элемент
───────────────┼───────────┼───────────────────
117314 ┊ 100,00% ┊ Σ [всего 1670 строк]
По сравнению с 628 КБ файлов необработанных данных это было намного меньше, чем я ожидал. Я был рад отправить его в производство, но мне было любопытно посмотреть, какой размер кода я могу сократить с помощью рекомендаций по оптимизации Rust And WebAssembly Working Group.
Первый эксперимент заключался в переключении LTO и опробовании различных уровней выбора. Следующая конфигурация дает наименьший размер кода .wasm:
Груз.томл
``ямл
[профиль.релиз]
- уровень выбора = 's'
- лто = правда
``` ударить
Неглубокие байты │ Неглубокие % │ Элемент
───────────────┼───────────┼───────────────────
111319 ┊ 100,00% ┊ Σ [всего 1604 строки]
Затем я заменил распределитель по умолчанию на wee_alloc.
wasm/полнотекстовый поиск/src/lib.rs
ржавчина
-
[глобальный_аллокатор]
- статический ALLOC: wee_alloc::WeeAlloc = wee_alloc::WeeAlloc::INIT;
``` ударить
Неглубокие байты │ Неглубокие % │ Элемент
───────────────┼───────────┼───────────────────
100483 ┊ 100,00% ┊ Σ [всего 1625 строк]
Затем я попробовал инструмент wasm-opt в Binaryen.
```javascript
wasm-opt -Oz -o wasm/полнотекстовый-поиск/pkg/полнотекстовый_поиск_core_bg.wasm wasm/полнотекстовый-поиск/pkg/полнотекстовый_поиск_core_bg.wasm
``` Баш
Неглубокие байты │ Неглубокие % │ Элемент
───────────────┼───────────┼───────────────────
100390 ┊ 100,00% ┊ Σ [всего 1625 строк]
Это на 14,4% меньше исходного размера кода.
В конце концов, я смог запустить полнотекстовый поисковик в:
- 98,04 КБ в чистом виде
- 45,92 КБ в сжатом виде
Не плохо😎
Это действительно быстро?
Я профилировал производительность с помощью web-sys и собрал некоторые данные:
- количество поисков: 208
- мин: 0,046 мс
- макс: 0,814 мс
- среднее значение: 0,0994 мс ✨
- стандартное отклонение: 0,0678
В среднем полнотекстовый поиск занимает менее 0,1 мс.
Это довольно быстро😎
Последние мысли
После некоторых экспериментов мне удалось создать быстрый и легкий полнотекстовый поиск с фильтрами WebAssembly, Rust и xor. Он хорошо интегрируется с Next.js и созданием статических сайтов.
Скорость и размер идут с некоторыми компромиссами, но они не оказывают большого влияния на пользовательский опыт. Если вам нужна более полная функция поиска, вот несколько интересных продуктов:
Поисковые системы SaaS
- [Алголия] (https://www.algolia.com/)
Статические поисковые системы
- [маленький поиск] (https://github.com/tinysearch/tinysearch)
Серверные поисковые системы
- [Meilisearch] (https://www.meilisearch.com/)
- [Typesense] (https://typesense.org/)
Встроенные в браузер поисковые системы
- [FlexSearch] (https://github.com/nextapps-de/flexsearch)
- [Мини-поиск] (https://github.com/lucaong/minisearch)
- [Elasticlunr.js] (http://elasticlunr.com/)
Рекомендации
- Статья: [Крошечная, статическая, полнотекстовая поисковая система с использованием Rust и WebAssembly — Матиас Эндлер] (https://endler.dev/2019/tinysearch)
- Статья: Написание системы полнотекстового поиска с использованием фильтров Блума — Ставрос Корокитакис
- Статья: Next.js — Динамический импорт
- Веб-сайт: [Портфолио До-Чи Лиу] (https://dawchihliou.github.io/)
- Веб-сайт: Meilisearch
- Веб-сайт: Typesense
- Веб-сайт: [Алголия] (https://www.algolia.com/)
- Веб-сайт: Elasticlunr.js
- Веб-сайт: Rust
- Веб-сайт: WebAssembly
- Веб-сайт: MDN WebAssembly
- Веб-сайт: Next.js
- Веб-сайт: Могу ли я использовать WebAssembly?
- Лекция: [Приблизительные запросы на членство — Стэнфорд] (https://web.stanford.edu/class/archive/cs/cs166/cs166.1216/lectures/13/Slides13.pdf#page=49)
- Вики: Полнотекстовый поиск
- GitHub: [пример Next.js и WebAssembly] (https://github.com/vercel/next.js/tree/canary/examples/with-webassembly)
- GitHub: dawchihliou.github.io
- GitHub: [Webpack 5 прерывает динамический импорт wasm для SSR] (https://github.com/vercel/next.js/issues/25852)
- Github: tinysearch
- GitHub: Meilisearch
- GitHub: xorf
- GitHub: wasm-pack
- GitHub: Binaryen
- GitHub: Twiggy
- GitHub: Clippy
- GitHub: web-sys
- GitHub: once_cell
- GitHub: [Bincode] (https://github.com/bincode-org/bincode)
- GitHub: wee_alloc
- GitHub: Serde
- GitHub: [В любом случае] (https://github.com/dtolnay/anyhow)
- GitHub: Contentlayer
- GitHub: FlexSearch
- GitHub: MiniSearch
Эта статья также была размещена на веб-сайте Доу-Чи.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27234)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)