

Speechverse против SOTA: речевые модели с несколькими задачами в реальных эталонах
18 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 подхода
2.1 Архитектура
2.2 Multimodal Trancing Paneletuning
2.3 Учебное обучение программы с эффективным характеристиком параметров
3 эксперименты
4 Результаты
4.1 Оценка моделей речи.
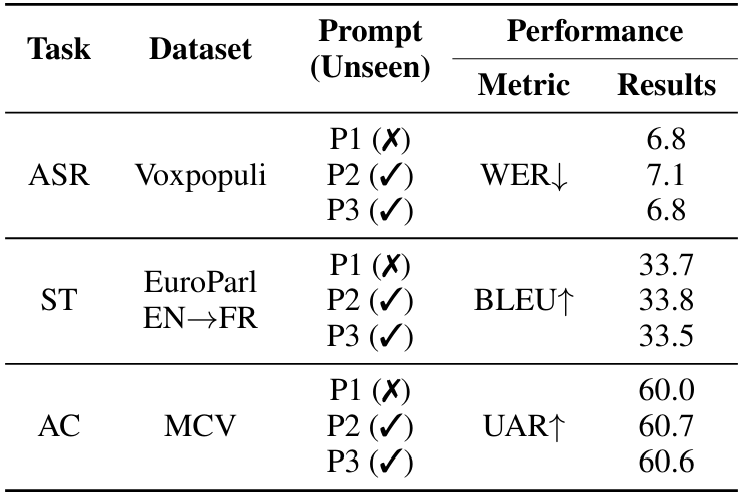
4.2 Обобщение между инструкциями
4.3 Стратегии повышения производительности
5 Связанная работа
6 Заключение, ограничения, заявление о этике и ссылки
Приложение
A.1 Audio Encoder перед тренировкой
A.2 Гиперпараметры
A.3 Задачи
4.1 Оценка моделей речи.
Мы оцениваем сквозные обученные совместные речевые и языковые модели (E2E-SLM), используя структуру речи для 11 уникальных задач по нескольким доменам и наборам данных. Сначала мы оцениваем основную возможность понимания речи Speechverse через тесты ASR. Затем мы оцениваем более сложные задачи SLU и паралингвистические речевые задачи в таблицах 2 и 3 соответственно.
4.1.1 Производительность на ASR и SLU задач
Во-первых, мы оцениваем производительность речевых моделей на четырех общедоступных наборах данных ASR, а именно Libri-Test-Clean, Libri-Test-Other, Voxpopuli и Commonvoice. Числа WER для каждого из этих наборов данных представлены в таблице 2. Речичная ASR в строке 2 использует ту же модель, что и модель ASR, специфичную для конкретной задачи (Task-FT) в строке 3. При сравнении нашей предварительной модели ASR, специфичной для задачи, которая также служит в качестве инициализации для многозадачного финала, чтобы шептать ASR, наша модель немного лучшая производительность в среднем. Тем не менее, WER увеличивается в обеих многозадачных моделях с многозадажным WLM, выполняемым аналогично шепоту на трех из четырех тестовых наборов. Более низкая производительность многозадачной речивой модели по сравнению с специфической задачей модели, вероятно, обусловлена наборами данных более низкого веса при построении партий во время обучения в нескольких задачах. Это было сделано, чтобы сбалансировать производительность во всех задачах, поскольку распределение данных несбалансировано между различными задачами.
Когда дело доходит до задач SLU, часто задается частый вопрос, если сквозная модель может превзойти каскадный трубопровод, который транскрибирует речь через ASR, а затем питает ее в языковую модель. Чтобы исследовать это, мы провели эксперименты по пяти семантическим понимающим задачам, используя те же модели фундамента, что и речи. Модель Text Foundation была дополнительно настроена на данные из пяти задач SLU отдельно, так как мы обнаружили, что производительность FLAN-T5 на этих эталонных испытательных наборах была довольно плохой. Мы также сообщаем о производительности при кормлении транскриптов и неплохих земли в тонкую настройку LLM, чтобы обеспечить результаты верхней границы. На 4 из 5 задач, исключая извлечение ключевых слов, сквозные обученные модели превосходят каскадный трубопровод. В частности, более часто используемые задачи, такие как классификация намерений, маркировка слотов и перевод речи, работают лучше, чем каскадная система, демонстрируя эффективность наших моделей, обученных с использованием речи. Мы также заметили, что речевые модели на задаче KWS опережают каскадный трубопровод по абсолютным 10% по точению, в то же время значительно выполняя задачу KWE. Поскольку задача поиска ключевых слов требует, чтобы охват внимания была сосредоточена на конкретном интересе, совместное моделирование помогает повысить точность, преодолевая распространение ошибок, присутствующее в каскадном трубопроводе. Мы также провели исследование абляции, чтобы определить, выгодно ли задача KWE дальше от совместного декодирования транскрипции ASR и ключевых слов. Мы заметили улучшение производительности, сократив разрыв к каскадному трубопроводу. Результаты этого исследования подробно описаны в подразделе 4.3.2. При сравнении многозадачных моделей с специфичными для задачи моделей речи, существует незначительная деградация в производительности, но разница не является существенной. В целом, многозадачная модель, обученная либо энкодером WAVLM, либо с энкодером Best-RQ, превзойденными каскадными системами в большинстве задач.
4.1.2 Производительность по паралингвистическим задачам
Результаты в таблице 3 демонстрируют четкие улучшения производительности в различных задачах обработки паралингвистической речи при использовании многозадачного обучения по сравнению с точной настройкой модели Wavlm независимо для каждой задачи. В частности, речевая модель, обученная многозадажным обучением с использованием Audio Enocoder Best-RQ (Multytask-BRQ), достигает прибыли по сравнению с базовой моделью Wavlm в 4,8% абсолютного распознавания эмоций, 6,6% при классификации звуков и 2,5% при классификации акцентов. Более скромные выгоды наблюдаются с помощью речевой модели, обученной с использованием многозадачного обучения с помощью Encoder Wavlm (Multysk-WLM). Адаптивная комбинация Unified Prevation из всех слоев энкодера помогает многозадачности Best-RQ модели улучшить разнообразную эффективность паралингвистических задач. В целом, многозадачное обучение обеспечивает заметные улучшения в обобщении и эффективности модели для разнообразного набора речевых задач по сравнению с конкретной задачей точной настройки базовой модели Wavlm. Результаты подчеркивают преимущества обучения общими представлениями по соответствующим задачам с использованием методов обучения с несколькими задачами.
4.1.3 Сравнение с моделями SOTA
Таблица 4 Стремление речевых моделей против современных моделей (SOTA) по пяти разнообразным задачам: автоматическое распознавание речи (ASR), перевод речи (ST), классификация намерений (IC), наполнение слотов (SF) и распознавание эмоций (ER). В этих задачах Speechverse демонстрирует конкурентоспособную или превосходную производительность по сравнению с предварительными специализированными моделями. Сравнивая нашу предварительную модель ASR, специфичную для конкретной задачи, которая также служит инициализацией для нескольких задач, для шепота ASR, наша модель в среднем достигает немного лучшей производительности. Тем не менее, многозадачная модель (Multysk-WLM) выполняла аналогично шепоту трех из четырех тестовых наборов. При оценке перевода речи в трех языковых парах, специфическая задача речевая модель.
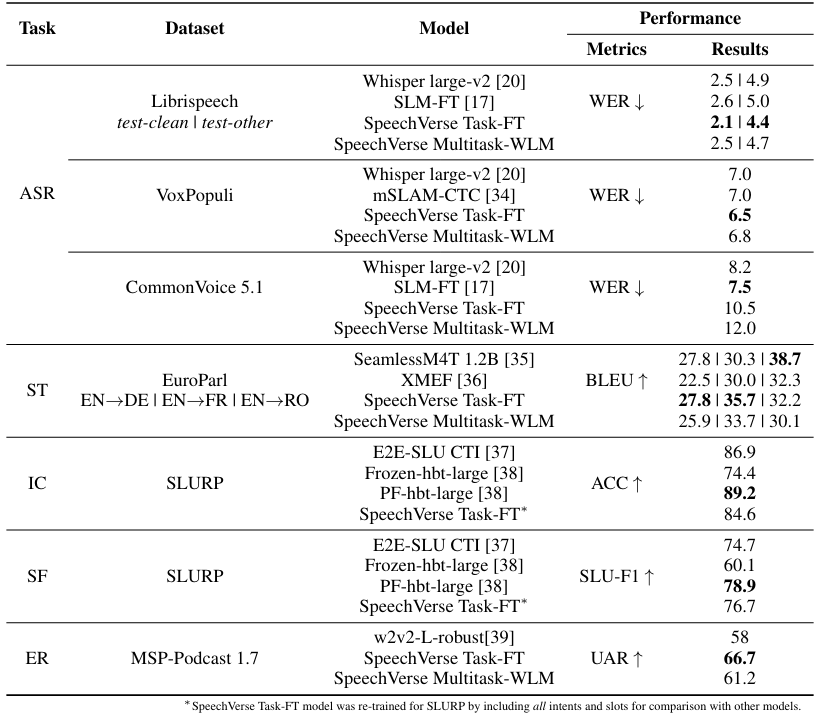
Превзошел SeamlessM4T в двух парах, в то время как многозадачная модель речи достигла конкурентной работы по сравнению с предыдущей работой в среднем. Обе модели не работали хорошо на английском и румынской паре. Общая производительность речевых моделей при переводе речи сильно ограничена возможностями базовой языковой модели Flust5. Возможности перевода речи не могут превышать качество перевода, предоставленное Flust5 в качестве модели базового языка. Чтобы оценить речевые речи по заданиям понимания разговорного языка, таких как классификация намерений (IC) и наполнение слотов (SF), мы перепровеили специфическую задачу модель речевой речи, включив все 69 намерений (как видные, так и невидимые), а также все слоты. Это позволило нам сравнить речи с предыдущей работой над полными намерениями и наборами слотов. Наша речевая модель достигла конкурентной работы с предыдущей SOTA (PF-HBT-Large) на заполнении слотов, но значительно отставала от классификации намерений с более низкой абсолютной точностью на 5%. Тем не менее, речи, превзошла ту же модель SOTA (Frozen-HBT-Large) на 10%, когда веса энкодера замораживались во время тонкой настройки. Чтобы дополнительно проанализировать разрыв в предыдущем современном искусстве, мы провели эксперимент, позволяя настраивать вес аудио-энкодера во время точной настройки. Это достигло 89,5% точности, сопоставив предыдущую SOTA. Это говорит о том, что производительность классификации намерений может переоценить определенные акустические условия набора данных Slurp, когда выполняется полная точная настройка. Речевая модель, которая была обучена сквозной, специально для задачи распознавания эмоций, достигла 8% абсолютного улучшения невзвешенного среднего отзыва по сравнению с предыдущей современной моделью (W2V2-L-Robust). Напротив, многозадачная речевая модель показала 3% лучше, чем предыдущий современный арт. Тем не менее, одно ключевое отличие состоит в том, что предыдущая работа SOTA, обученная набору данных MSP-Podcast 1.7, в то время как мы использовали версию 1.11 для обучения. Версия для тестового набора оставалась неизменной между двумя подходами. В целом, речевая модель продемонстрировала конкурентную эффективность по сравнению с предыдущими специализированными моделями в некоторых случаях при оценке по различным задачам.
Авторы:
(1) Nilaksh Das, AWS AI Labs, Amazon и равный вклад;
(2) Saket Dingliwal, AWS AI Labs, Amazon (skdin@amazon.com);
(3) Шрикант Ронанки, AWS AI Labs, Amazon;
(4) Рохит Патури, AWS AI Labs, Amazon;
(5) Zhaocheng Huang, AWS AI Labs, Amazon;
(6) Prashant Mathur, AWS AI Labs, Amazon;
(7) Цзе Юань, AWS AI Labs, Amazon;
(8) Дхануш Бекал, AWS AI Labs, Amazon;
(9) Син Ниу, AWS AI Labs, Amazon;
(10) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon;
(11) Xilai Li, AWS AI Labs, Amazon;
(12) Карел Мунднич, AWS AI Labs, Amazon;
(13) Моника Сункара, AWS AI Labs, Amazon;
(14) Даниэль Гарсия-Ромеро, AWS AI Labs, Amazon;
(15) Кю Дж. Хан, AWS AI Labs, Amazon;
(16) Катрин Кирххофф, AWS AI Labs, Amazon.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)