

Решение проблемы «Мальчик, который плакал», «Волк»: от индивидуальных предупреждений до совокупной уверенности
2 июля 2025 г.Авторы:
(1) MD Mainuddin, факультет компьютерных наук, Университет штата Флорида, Таллахасси, FL 32306 (mainuddi@cs.fsu.edu);
(2) Zhenhai Duan, кафедра компьютерных наук Флорида Университет штата Таллахасси, FL 32306 (duan@cs.fsu.edu);
(3) Yingfei Dong, факультет электротехники, Гавайский университет Гонолулу, HI 96822 США (yingfei@hawaii.edu).
Таблица ссылок
Аннотация и 1. Введение
2. Связанная работа
3. Фон на AutoEncoder и SPRT и 3.1. AutoEncoder
3.2. Тест на коэффициент последовательного вероятности
4. Дизайн Cumad и 4.1. Сетевая модель
4.2. Cumad: кумулятивное обнаружение аномалий
5. Оценные исследования и 5.1. Набор данных, функции и настройка системы Cumad
5.2. Результаты производительности
6. Выводы и ссылки
2. Связанная работа
Проблема обнаружения аномалий была изучена во многих различных областях применения, и было предложено множество методов, основанных на статистическом выводе, интеллектуальном анализе, обработке сигналов и недавно машинном обучении, среди прочего. Мы отмечаем, что в литературе по обнаружению аномалий аномалии были классифицированы по трем категориям: точечная аномалия, контекстуальная аномалия и коллективная аномалия [5]. Тем не менее, все они обеспокоены обнаружением отдельных аномальных событий, которые отличаются от совокупной аномалии, которую мы рассматриваем в этой статье. В совокупной аномалии мы больше обеспокоены причиной аномальных событий (например, скомпрометированного устройства IoT) вместо отдельных аномальных событий. Как следствие, нам необходимо накопить достаточные доказательства (индивидуальные аномальные события), чтобы прийти к выводу (например, если устройство IoT нарушено) при совокупном обнаружении аномалии.
Учитывая важность повышения безопасности IoT, было предложено много методов обнаружения атаки безопасности, включая различные решения на основе ML [3], [9]. Однако некоторым из них потребовалось учебные данные как доброкачественного трафика, так и атаки. Они не могут обнаружить новые атаки безопасности. Другие разработали схемы на основе обнаружения аномалий для обнаружения аномального трафика, возникающего из устройств IoT. Однако, как мы обсуждали в разделе 1, они часто вызывают большое количество ложных оповещений, что делает их непригодными для обнаружения скомпрометированных устройств IoT в развертывании реального мира.
В [10] Gelenbe и Nakip разработали онлайн -схему CDI для обнаружения скомпрометированных устройств IoT на основе автоматического обучения. Тем не менее, дизайн CDI была адаптирована к ботнету Mirai и может быть не эффективным для обнаружения других типов скомпрометированных устройств IoT. Кроме того, CDI по -прежнему нацелены только на индивидуальные аномальные события, вместо кумулятивного обнаружения аномалий, как мы выполняем в этой статье. Авторы [11] разработали федеративную схему самообучения, основанную на самообучении, для обнаружения скомпрометированных устройств IoT, где локальные шлюзы безопасности общаются с удаленной службой безопасности IoT для создания более полной обычной модели трафика устройств IoT. Чтобы дополнительно уменьшить ложные оповещения, генерируемые моделью обнаружения агрегированной аномалии, была принята схема на основе оконных условий, где аномалия была запускается только в том случае, если доля аномальных пакетов была больше, чем предварительно определенное пороговое значение. В [8] Meidan et al. Представлена система обнаружения аномалий на основе автоэкодера N-BAIOT для обнаружения компрометированных устройств IoT. N-BAIOT также попытался уменьшить количество ложных оповещений, вызванных системой обнаружения чистой аномалий, используя схему на основе окон с большинством голосов для принятия решения.
3. Фон на AutoEncoder и SPRT
В этом разделе мы предоставляем необходимый фон по автоэкодерке и тесту с последовательным коэффициентом вероятности (SPRT) для понимания разработки предлагаемой структуры CUMAD. Мы ссылаемся на заинтересованных читателей [6] и [7], соответственно, для подробного лечения по этим двум темам.
3.1. AutoEncoder
AutoEncoder - это неконтролируемая нейтральная сеть, которая направлена на то, чтобы реконструировать вход на выходе. Рисунок 1 иллюстрирует простой стандартный (недооверенный) AutoEncoder.
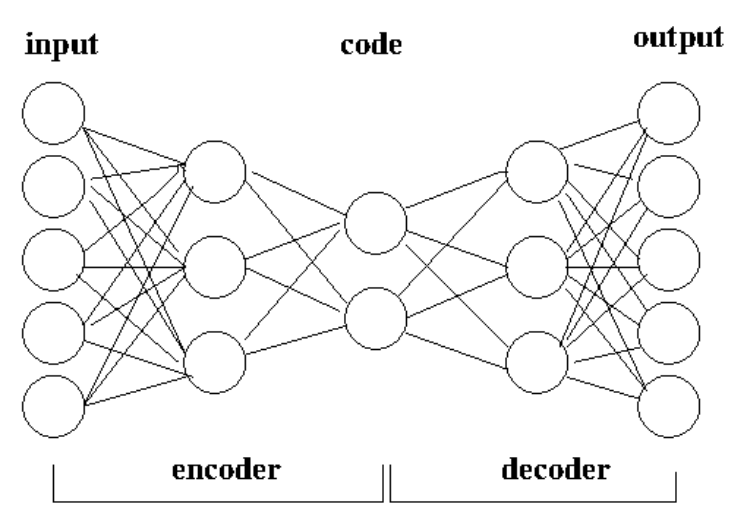
Автоэкодер может рассматриваться как состоящий из двух компонентов: энкодера F и декодера g. Приведенные входные данные x, функция Encoder F отображает x на представление скрытого пространства или код H, то есть h = f (x). Используя соответствующий код H в качестве ввода, функция декодера G пытается реконструировать исходный вход x на его выходе x ′, то есть x ′ = g (h). Объединяя функцию энкодера и функцию декодера вместе, мы имеем x ′ = g (f (x)). Пусть l (x, x ′) - ошибка реконструкции, то есть разница между x и x ′. Аутоизмечатель стремится минимизировать L (x, x ′). Мы отмечаем, что существуют разные определения L (x, x ′), и одно из наиболее распространенных определений - это средние квадратные ошибки (MSE). Отметим, что в примере AutoEncoder на рисунке 1 как энкодер, так и декодер имеют только один скрытый слой. Это только для иллюстрации. В действительности у них может быть много скрытых слоев, в зависимости от конкретного требования применения.
Автокодеры традиционно используются в приложениях сокращения размерности и обучения функций, сосредоточив внимание на сжатом коде автоэкодора, который содержит представление исходных данных скрытого пространства. С другой стороны, автоэнкодеры также обладают несколькими желаемыми свойствами, что делает их привлекательным кандидатом на обнаружение аномалий. Например, автоэкодер способен извлекать важные особенности исходных данных для удаления зависимости в исходных данных. Что еще более важно, автоэнкодер может только изучать свойства или распределения данных, которые он видел на этапе обучения, то есть точки данных в наборе обучения. Он превосходит реконструкцию данных, которые похожи на учебные данные, но плохо выполняют данные, которые сильно отличаются от учебных данных, с точки зрения ошибки реконструкции L (x, x ′).
Это привлекательная собственность автоэнкодеров при применении обнаружения аномалий. Например, в контексте обнаружения скомпрометированных устройств IoT мы можем установить нормальную поведенческую модель устройства IoT, используя автоэкодер, обучая его с доброкачественным сетевым трафиком, прежде чем устройство будет скомпрометировано. Мы можем продолжить мониторинг устройства IoT, передавая соответствующий сетевой трафик устройства в обученную модель. Если ошибка реконструкции не превышает предварительно указанный порог, мы считаем, что соответствующий сетевой трафик является доброжелательным. Когда ошибка реконструкции больше порога, мы утверждаем, что сетевой трафик является аномальным.
Эта статья естьДоступно на Arxivв соответствии с CC по 4.0 Deed (Attribution 4.0 International) лицензия.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)