

Обнаружение мелких объектов в компьютерном зрении: подход на основе патчей
9 января 2023 г.Есть много интересных и ценных задач Computer Vision. Например, допустим, у нас есть проект, в котором мы хотим искать заблудших людей в лесу с помощью дронов с камерами и компьютерного зрения. Или, может быть, нам нужно найти что-то маленькое и у нас есть качественная камера.
В таких случаях мы можем получить изображения с высоким разрешением в нашем наборе данных. Однако большинство моделей CV имеют более низкое разрешение изображения, потому что это повышает скорость (как при обучении, так и при выводе), и обычно вам не нужны очень высокие разрешения для обнаружения объекта.
Однако в нашем случае нам действительно нужно полное разрешение, потому что для поиска мы будем использовать дроны с камерами. Это означает, что даже люди будут отображаться на наших изображениях как крошечные объекты. Как мы справимся с такой задачей?
Набор данных
Все начинается с набора данных. Я попытался найти открытый набор данных и в итоге использовал TinyPerson. Это не идеальный набор данных для поиска пропавших людей, но мы будем использовать его в качестве примера.
Я преобразовал набор данных из формата COCO в формат формат YOLO, так как я собирался использовать модель из семейства YOLO. Кроме того, я немного отфильтровал набор данных, но ничего особенно важного. Чтобы преобразовать набор данных, я использовал этот репозиторий и немного изменил его, чтобы он работал в моем случае. Мой окончательный набор данных состоит из 1495 изображений. Я разделил его на train/val, где на проверку осталось 15%.
Несколько замечаний по этому набору данных.
Изображения сложные, на них может быть много людей, и они могут быть очень далеко.
Нередко не все отмечены ярлыками, что нехорошо.
Во всяком случае, вот хороший пример из набора данных:

Важно иметь в виду, что в этом наборе данных не так много изображений с высоким разрешением, что вызывает сожаление. Средний размер – 1920 x 1080.
Базовый уровень
В качестве базовой модели я взял предварительно обученную YOLOv5l6, которая использует изображения 1280 x 1280 и является довольно мощной моделью. Я также пробовал использовать YOLOv7-W6 с тем же размером изображения и аналогичным размером модели, но с этим набором данных я получил худшие результаты, поэтому Я остановился на YOLOv5.
Имея правильный набор данных, Yolov5 легко обучить командам, подобным этой:
python train.py --data dataset/dataset.yaml --weights yolov5m6.pt --img 1280 --batch 15 --epochs 80
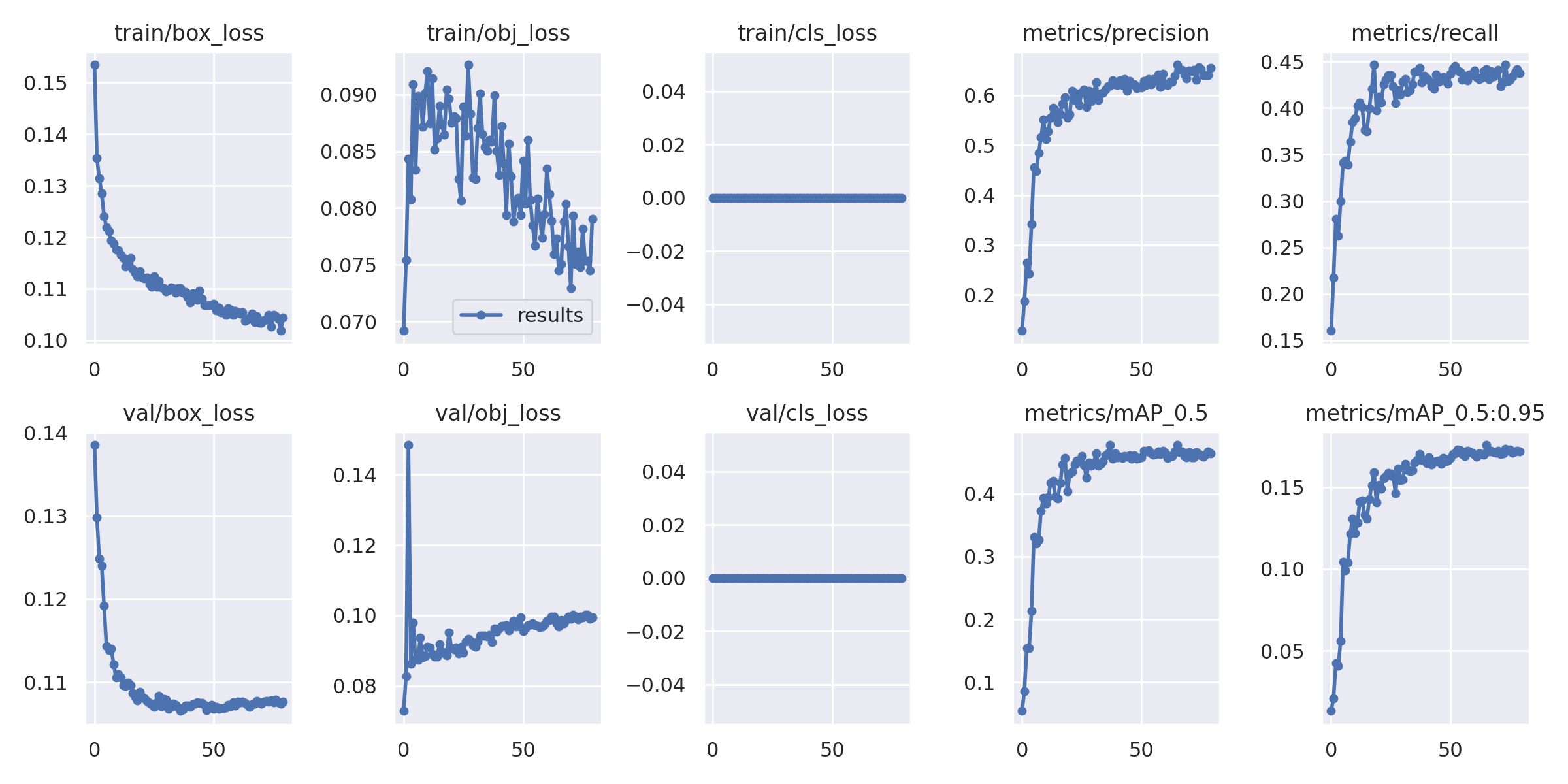
Я получил mAP50 около 0,477 для исходного уровня. Вы можете увидеть, что в этом наборе данных это нормальная карта доступа.
Поэтому мы все еще теряем некоторые данные в большинстве случаев в нашем базовом плане, поскольку мы изменяем размер каждого изображения до 1280 x 1280.
Когда наши объекты такие маленькие, мы не хотим этого делать. Лучше было бы сохранить полное разрешение. Но модели оптимизированы для размера тренировочного изображения, поэтому нам нужно использовать 1280 x 1280 или 640 x 640 в случае семейства YOLO.
Подход на основе исправлений
Это еще один подход, который может нам помочь.
Что, если мы возьмем каждое изображение и обрежем его с помощью скользящего окна фиксированного размера, а затем используем кадрирование в качестве обучающих данных?
Давайте возьмем меньшую модель с входным размером 640x640 и сократим наш набор данных до этого размера. Вот как я это вижу: В качестве примера возьмем изображение размером 1920x1080. Мы можем разделить его на 6 изображений (патчей) размером 640x640. Мы не можем разрезать его точно, у нас будут пересечения, и это нормально:

Синие прямоугольники — это патчи первого ряда, а зеленые — второго. Здесь у нас нет пересечения между столбцами только потому, что 1920 делится на 640, но у нас есть пересечение между первой и второй строками. Этим пересечением мы снижаем вероятность того, что наш объект будет обрезан по краю заплатки, хотя она и так мала, потому что наши объекты маленькие.
И не забывайте, что вам нужно выполнить тот же процесс со своими ярлыками.
В любом случае, мы можем использовать этот подход для любого изображения, независимо от размера (если оно больше, чем размер нашего патча).
Это позволяет нам:
- Чтобы не потерять разрешение изображения
- Чтобы использовать оптимальный размер входных данных для модели, независимо от того, какие размеры изображений у нас изначально были.
Этот подход также хорош, если у вас недостаточно памяти на вашем графическом процессоре. Вы можете оказаться в такой ситуации с 3D очень часто. TorchIO — хорошая библиотека для этих задач. Но в нашем случае я решил использовать простой кастомный патчер, специально написанный для моделей YOLO.
Вот мой utils.py:
from typing import List
def xywh_to_xyxy(
lines: List[str],
img_height: int,
img_width: int) -> List[List[int]]:
'''
This function gets list with YOLO labels in a format:
label, x-center, y-center, bbox width, bbox height
coordinates are in relative scale (0-1).
Returns list of lists with xyxy format and absolute scale.
'''
labels = []
for _, cur_line in enumerate(lines):
cur_line = cur_line.split(' ')
cur_line[-1] = cur_line[-1].split('n')[0]
# convert from relative to absolute scale (0-1 to real pixel numbers)
x, y, w, h = list(map(float, cur_line[1:]))
x = int(x * img_width)
y = int(y * img_height)
w = int(w * img_width)
h = int(h * img_height)
# convert to xyxy
left, top, right, bottom = x - w // 2, y - h // 2, x + w // 2, y + h // 2
labels.append([int(cur_line[0]), left, top, right, bottom])
return labels
def xyxy_to_xywh(
label: List[int],
img_width: int,
img_height: int) -> List[float]:
'''
This function gets list with label and coordinates in a format:
label, x1, y1, x2, y2
coordinates are in absolute scale.
Returns list with xywh format and relative scale
'''
x1, y1, x2, y2 = list(map(float, label[1:]))
w = x2 - x1
h = y2 - y1
x_cen = round((x1 + w / 2) / img_width, 6)
y_cen = round((y1 + h / 2) / img_height, 6)
w = round(w / img_width, 6)
h = round(h / img_height, 6)
return [label[0], x_cen, y_cen, w, h]
А вот и сам патчер:
from typing import Union
from pathlib import Path
import numpy as np
from skimage import io
from utils import xywh_to_xyxy, xyxy_to_xywh
class Patcher:
def __init__(
self, path_to_save: Union[Path, str], base_path: Union[Path, str]
) -> None:
self.path_to_save = path_to_save
self.create_folders()
self.base_path = base_path
def create_folders(self) -> None:
self.path_to_save.mkdir(parents=True, exist_ok=True)
(self.path_to_save / "images").mkdir(exist_ok=True)
(self.path_to_save / "labels").mkdir(exist_ok=True)
def patch_sampler(
self,
img: np.ndarray,
fname: str,
patch_width: int = 640,
patch_height: int = 640,
) -> None:
# Get image size and stop if it's smaller than patch size
img_height, img_width, _ = img.shape
if img_height < patch_height or img_width < patch_width:
return
# Get number of horisontal and vertical patches
horis_ptch_n = int(np.ceil(img_width / patch_width))
vertic_ptch_n = int(np.ceil(img_height / patch_height))
y_start = 0
##### Prepare labels
label_path = (self.base_path / "labels" / fname).with_suffix(".txt")
with open(label_path) as f:
lines = f.readlines()
all_labels = xywh_to_xyxy(lines, *img.shape[:2])
#####
# Run and create every crop
for v in range(vertic_ptch_n):
x_start = 0
for h in range(horis_ptch_n):
idx = v * horis_ptch_n + h
x_end = x_start + patch_width
y_end = y_start + patch_height
# Get the crop
cropped = img[y_start:y_end, x_start:x_end]
##### Get labels patched
cur_labels = []
for label in all_labels:
cur_label = label.copy()
# Check if label is insde the crop
if (
label[1] > x_start
and label[2] > y_start
and label[3] < x_end
and label[4] < y_end
):
# Change scale from original to crop
cur_label[1] -= x_start
cur_label[2] -= y_start
cur_label[3] -= x_start
cur_label[4] -= y_start
label_yolo = xyxy_to_xywh(cur_label, patch_width, patch_height)
cur_labels.append(label_yolo)
# Save the label file to the disk
if len(cur_labels):
with open(
self.path_to_save / "labels" / f"{fname}_{idx}.txt", "a") as f:
f.write("n".join("{} {} {} {} {}".format(*tup) for tup in cur_labels))
f.write("n")
#####
# Save the crop to disk
io.imsave(self.path_to_save / "images" / f"{fname}_{idx}.jpg", cropped)
# Get horisontal shift for the next crop
x_start += int(
patch_width - (patch_width - img_width % patch_width) /
(img_width // patch_width)
)
# Get vertical shift for the next crop
y_start += int(
patch_height - (patch_height - img_height % patch_height) /
(img_height // patch_height)
)
def main():
'''
base path structure:
-> dataset
---> train
-----> images (folder with images)
-----> labels (folder with labels)
---> valid
-----> images (folder with images)
-----> labels (folder with labels)
'''
base_path = Path("")
# path were you want to save patched dataset
path_to_save = Path("")
for split in ['train', 'valid']:
images_folder_path = base_path / split / "images"
patcher = Patcher(path_to_save / split, base_path / split)
for image_path in images_folder_path.glob("*"):
if image_path.name.startswith("."):
continue
image = io.imread(image_path)
fname = image_path.stem
patcher.patch_sampler(image, fname)
if __name__ == "__main__":
main()
Обучить YOLOv5 по-прежнему легко:
python train.py --data dataset/dataset.yaml --weights yolov5m.pt --img 640 --batch 40 --epochs 80
mAP немного увеличился - до 0,499:
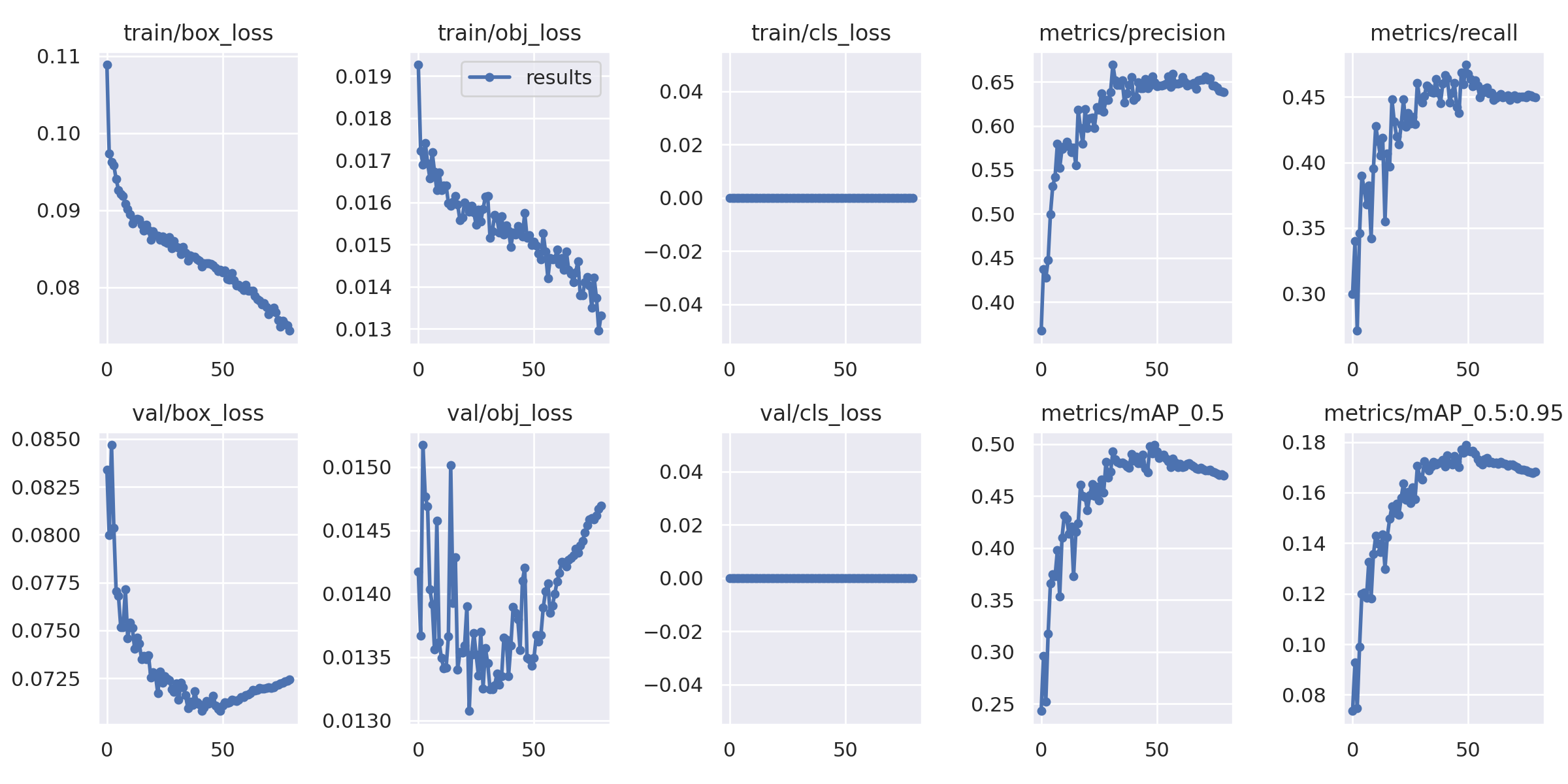
Итак, мы увеличили наше mAP на 4%, что немного, и наше новое решение будет немного медленнее (как при выводе, так и при обучении). Но эта техника будет работать лучше, чем выше разрешение ваших изображений. И мы видим разницу даже в размере нашего изображения.
Заключение
Наилучший вариант использования этой техники — когда вы не боитесь похудеть, чтобы повысить точность, и у вас есть изображения с высоким разрешением и небольшими объектами. В других подобных случаях вы также можете попробовать это решение после того, как у вас будет базовый уровень. Не забудьте сначала разделить набор данных, а затем образцы исправлений, чтобы избежать утечки данных.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27466)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)