Введение
Kafka – это платформа потоковой передачи, которая используется для обработки данных в режиме реального времени. В мире, где царят данные, Kafka — ценный инструмент для обучения разработчиков и инженеров данных. Однако локальная настройка Kafka может вызвать разочарование, что может препятствовать обучению. В этой статье я покажу вам самый быстрый способ настроить Kafka для разработки с помощью Docker, а также покажу, как эта настройка может поддерживать подключение локально и из других локальных контейнеров Docker.
В этом руководстве предполагается, что у вас есть некоторые знания об использовании Docker и docker-compose для разработки. Если вы новичок в Docker, я рекомендую сначала прочитать эту статью. Если вам нужно установить Docker, следуйте инструкциям здесь.
Обзор Кафки
На приведенной ниже диаграмме представлен общий обзор возможностей Kafka для начинающих. (в Kafka есть намного больше, например, Zookeeper, Consumer Groups, Partitions и т. д., но мы оставим это на другой раз.)
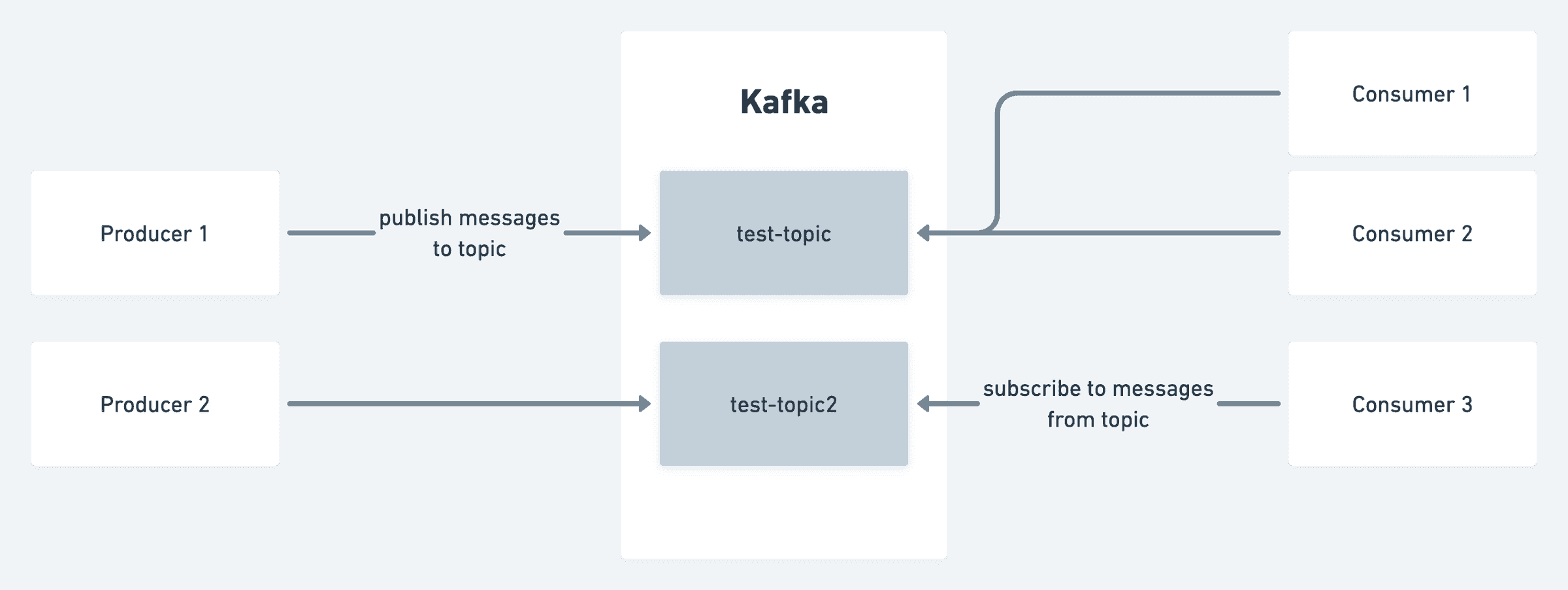
Kafka классифицирует данные по темам. Тема — это категория или имя фида, в котором публикуются записи.
Производители публикуют сообщения на определенную тему. Сообщения могут быть в любом формате, наиболее популярными вариантами являются JSON и Avro. Например, платформа социальной сети может использовать производителя для публикации сообщений в теме, называемой сообщениями, всякий раз, когда пользователь создает сообщение.
Потребители подписываются на тему, чтобы использовать записи, опубликованные производителями. В примере с социальной сетью может быть потребитель, настроенный на использование темы сообщений для выполнения проверок безопасности сообщения перед его публикацией в глобальной ленте, а другой потребитель может асинхронно отправлять уведомления подписчикам пользователя.
Настройка Kafka в Docker
Мы будем использовать изображения bitnami для Kafka и Zookeeper. Я предпочитаю это образам wurstmeister, потому что его проще настроить и активнее поддерживать. Мы также будем использовать инструмент docker-compose для управления нашими контейнерами.
Создайте файл с именем docker-compose.yml и добавьте следующее содержимое:
# docker-compose.yml
version: "3.7"
services:
zookeeper:
restart: always
image: docker.io/bitnami/zookeeper:3.8
ports:
- "2181:2181"
volumes:
- "zookeeper-volume:/bitnami"
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka:
restart: always
image: docker.io/bitnami/kafka:3.3
ports:
- "9093:9093"
volumes:
- "kafka-volume:/bitnami"
environment:
- KAFKA_BROKER_ID=1
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CLIENT:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_CFG_LISTENERS=CLIENT://:9092,EXTERNAL://:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=CLIENT://kafka:9092,EXTERNAL://localhost:9093
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=CLIENT
depends_on:
- zookeeper
volumes:
kafka-volume:
zookeeper-volume:
Обратите внимание, что мы установили несколько переменных среды для контейнера Kafka. Дополнительные сведения см. в документации по образу bitnami/kafka. Обратите внимание, что мы также определили службу zookeeper. Это связано с тем, что Kafka зависит от Zookeeper для хранения метаданных о темах и разделах. В целях разработки вам не нужно взаимодействовать с ним и
вы можете спокойно игнорировать его на данный момент.
Чтобы запустить это, просто запустите docker-compose up -d, и вы должны увидеть следующий вывод:
$ docker-compose up -d
Creating network "kafka-on-docker_default" with the default driver
Creating volume "kafka-on-docker_kafka-volume" with default driver
Creating volume "kafka-on-docker_zookeeper-volume" with default driver
Creating kafka-on-docker_zookeeper_1 ... done
Creating kafka-on-docker_kafka_1 ... done
Взаимодействие с контейнером Kafka с вашего локального компьютера
kafkacat предлагает простой интерфейс командной строки для взаимодействия с Kafka. Это отличный инструмент для проверки работоспособности Kafka. Чтобы установить kafkacat, следуйте инструкциям на странице https://github.com/edenhill/kcat в зависимости от вашей операционной системы.
Чтобы проверить, работает ли Kafka, выполните следующую команду, чтобы получить список всех тем, которые сейчас есть в Kafka:
$ kcat -b localhost:9093 -L # list all topics currently in kafka
Metadata for all topics (from broker 1: localhost:9093/1):
1 brokers:
broker 1 at localhost:9093 (controller)
0 topics:
Обратите внимание, что мы используем localhost:9093 вместо стандартного порта 9092. Это связано с тем, что мы используем порт, открытый для нашего локального компьютера.
Чтобы протестировать производителя, выполните следующую команду:
$ kcat -b localhost:9093 -t test-topic -P # producer
one line per message
another line
Разделителем по умолчанию между сообщениями является новая строка. Когда вы закончите, нажмите ctrl-d, чтобы отправить сообщения.
(К сведению: нажатие ctrl+c не сработает, вам придется повторить попытку.)
Чтобы прочитать созданные вами сообщения, выполните следующую команду, чтобы запустить потребителя:
$ kcat -b localhost:9093 -t test-topic -C # consumer
one line per message
another line
% Reached end of topic test-topic [0] at offset 2
Однако публикация произвольного текста — это не совсем то, что нам нужно, поэтому давайте попробуем вместо этого публиковать сообщения JSON. Чтобы сделать это проще для расширения мы напишем несколько скриптов Python для создания и использования сообщений.
Для начала необходимо установить библиотеку kafka-python. Вы можете сделать это, запустив pip install kafka-python, или если вы
более продвинутый, используйте virtualenv и вместо этого установите из requirements.txt.
# producer.py
from kafka import KafkaProducer
from datetime import datetime
import json
producer = KafkaProducer(
bootstrap_servers=['localhost:9093'],
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
producer.send('posts', {'author': 'choyiny', 'content': 'Kafka is cool!', 'created_at': datetime.now().isoformat()})
Ниже приведен пример потребителя Python, который подписывается на post и выводит каждое значение.
# consumer.py
from kafka import KafkaConsumer
import json
consumer = KafkaConsumer(
'posts',
bootstrap_servers=['localhost:9093'],
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
# note that this for loop will block forever to wait for the next message
for message in consumer:
print(message.value)
Подключение к Kafka из другого контейнера Docker
Если вы создаете сообщения в теме Kafka, вы, скорее всего, запланировали место назначения для сообщений. Например, приведенный выше фрагмент показывает, как вы можете написать свой собственный потребитель Python. Иногда, однако, вам может понадобиться передать ваши сообщения другому базу данных, такую как Clickhouse или Elasticsearch, для дальнейшей обработки или визуализации.
Хотя вы можете вставлять сообщения непосредственно в Clickhouse, для более масштабируемого решения вы можете использовать массовую вставку для минимизировать транзакции. (Опять же, это тема для другого раза... наша цель действительно состоит в том, чтобы запустить POC.)
Давайте покажем пример интеграции нашей Dockerized Kafka с Clickhouse, базой данных OLAP. (Какие Clickhouse будет отдельной статьей...)
Чтобы узнать больше о механизме таблиц Clickhouse, см. Использование механизма таблиц Kafka.
Создайте файл с именем docker-compose.yml и добавьте следующее содержимое:
# docker-compose.yml
version: "3.7"
services:
clickhouse:
restart: always
image: clickhouse/clickhouse-server
ports:
- "8123:8123"
- "9000:9000"
volumes:
- "clickhouse-volume:/var/lib/clickhouse/"
volumes:
clickhouse-volume:
Теперь мы готовы подключиться к Clickhouse. Выполните следующую команду, чтобы запустить контейнер Clickhouse:
$ docker-compose -f clickhouse.docker-compose.yml exec clickhouse clickhouse-client
ClickHouse client version 22.11.2.30 (official build).
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 22.11.2 revision 54460.
Warnings:
* Linux is not using a fast clock source. Performance can be degraded. Check /sys/devices/system/clocksource/clocksource0/current_clocksource
0cd6f3269407 :)
Это интерактивная оболочка, позволяющая выполнять команды SQL. Чтобы создать таблицу, выполните следующую команду:
-- create messages queue
CREATE TABLE default.message_queue
(
created_at DateTime,
content String,
author String
)
ENGINE = Kafka(
'kafka:9092',
'posts',
'clickhouse',
'JSONEachRow'
) settings kafka_thread_per_consumer = 1, kafka_num_consumers = 1;
Обратите внимание, что мы используем kafka:9092 в качестве строки подключения вместо localhost:9093 при локальном подключении к Kafka. Этот
потому что мы подключаемся к нему через внутреннюю сеть Docker.
Давайте создадим еще несколько таблиц для визуализации данных:
-- create messages table
CREATE TABLE default.messages
(
created_at DateTime,
content String,
author String
)
ENGINE = MergeTree
ORDER BY created_at;
-- create materialized view
CREATE MATERIALIZED VIEW default.messages_mv
TO default.messages
AS SELECT * FROM default.message_queue;
Я оставлю читателю в качестве упражнения придумать SQL-запросы для выбора данных в таблице messages.
Связать все вместе
Для нашего демонстрационного приложения мы создадим конечную точку API POST /posts в Python Flask, и вместо того, чтобы сохранять ее напрямую в базе данных, мы собираемся создать ее в теме Kafka сообщения. Следуйте инструкциям ниже или клонируйте это демо-репозиторий. Кроме того, поскольку мы настроили Clickhouse для получения сообщений от Kafka, мы сможем видеть сообщения в пользовательском интерфейсе Clickhouse.
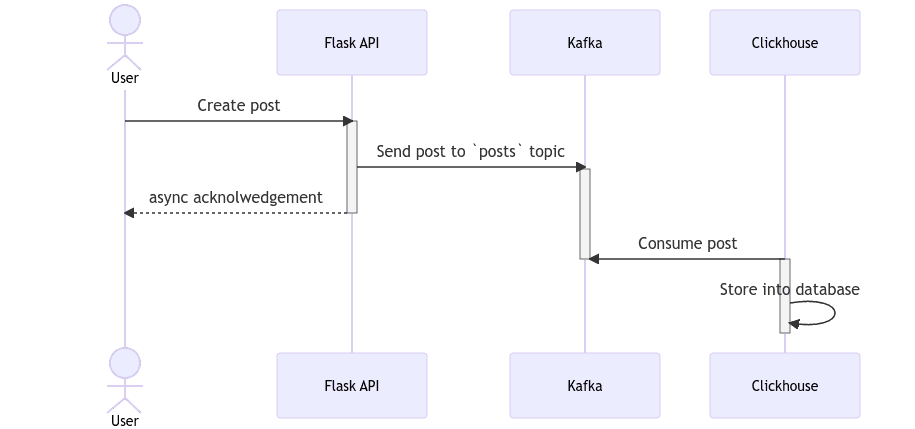
Вот простой код для конечной точки API:
# app.py
# fun fact: This snippet was generated entirely by Copilot
from flask import Flask, request
from kafka import KafkaProducer
from datetime import datetime
import json
app = Flask(__name__)
producer = KafkaProducer(
bootstrap_servers=['kafka:9093'],
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
@app.route('/posts', methods=['POST'])
def create_post():
post = request.get_json()
# clickhouse can only parse strings without milliseconds
post['created_at'] = datetime.now().strftime("%Y-%m-%dT%H:%M:%S")
producer.send('posts', post)
return 'ok'
Чтобы запустить это, вы можете использовать следующую команду:
$ flask run
После запуска вы можете попробовать конечную точку, выполнив команду curl:
$ curl -X POST -H "Content-Type: application/json" -d '{"author": "choyiny", "content": "Kafka is cool!"}' http://localhost:5000/posts
Было бы здорово, если бы это сработало с первого раза, однако вот команды, которые вы можете использовать для извлечения журналов из Clickhouse для проверки ошибок:
$ docker-compose exec clickhouse tail -f /var/log/clickhouse-server/clickhouse-server.log
Чтобы удалить поврежденные сообщения из темы кафки, достаточно просто полностью удалить тему с помощью этой команды:
$ docker-compose exec kafka /opt/bitnami/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic posts
В идеале ошибок быть не должно. Я оставлю читателю в качестве упражнения снова подключиться к Clickhouse и проверить, используются ли данные из Kafka.
И вот оно! Комплексное решение с Kafka на Docker в локальной среде. Опять же, весь код доступен в этом демонстрационном репозитории. Если у вас есть какие-либо вопросы, не стесняйтесь, напишите комментарий ниже!
:::информация Также опубликовано здесь.
:::