Что гарантирует стабильность системы при выполнении запросов к большим данным? Это эффективный механизм распределения и мониторинга памяти. Это то, как вы ускоряете вычисления, избегаете горячих точек памяти, быстро реагируете на нехватку памяти и минимизируете ошибки OOM.

С точки зрения пользователя базы данных, как он страдает от плохого управления памятью? Вот список вещей, которые раньше беспокоили наших пользователей:
* Ошибки OOM вызывают сбой внутренних процессов. Процитирую одного из членов нашего сообщества: Привет, Apache Doris, если у вас не хватает памяти, это нормально, если вы замедляете работу или не выполняете несколько задач, но устраивать простои — это просто не круто.
* Бэкенд-процессы потребляют слишком много памяти, но невозможно найти точную задачу, которая виновата, или ограничить использование памяти для одного запроса.
* Трудно установить правильный размер памяти для каждого запроса, поэтому велика вероятность того, что запрос будет отменен, даже если памяти достаточно.
* Запросы с высокой степенью параллелизма выполняются непропорционально медленно, а активные точки памяти трудно обнаружить.
* Промежуточные данные во время создания HashTable не могут быть сброшены на диски, поэтому запросы на соединение между двумя большими таблицами часто не выполняются из-за OOM.
К счастью, эти темные дни позади, потому что мы улучшили наш механизм управления памятью снизу вверх. Теперь будьте готовы; все будет интенсивно.
Распределение памяти
В Apache Doris у нас есть единственный интерфейс для выделения памяти: Распределитель. Он будет вносить коррективы по своему усмотрению, чтобы поддерживать эффективное и контролируемое использование памяти.
Кроме того, существуют MemTrackers для отслеживания выделенного или освобожденного размера памяти, а три разные структуры данных отвечают за выделение большого объема памяти при выполнении оператора (мы к ним сразу вернемся).
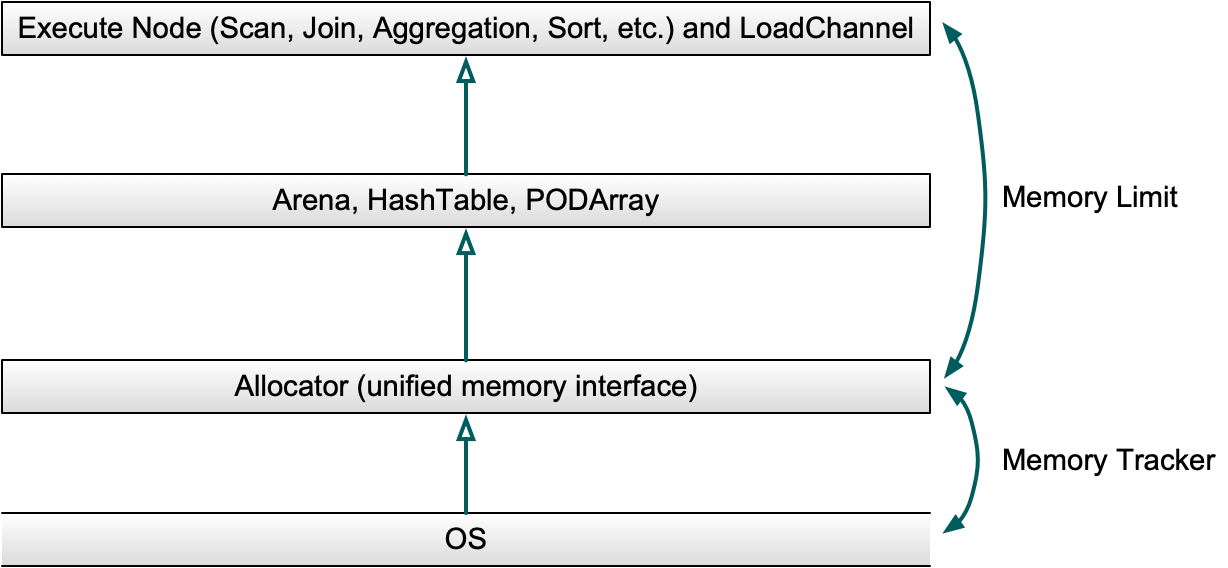
Структуры данных в памяти
Поскольку разные запросы имеют разные шаблоны областей памяти при выполнении, Apache Doris предоставляет три различные структуры данных в памяти: Arena, HashTable и PODArray. сильный>. Все они находятся под властью Распределителя.
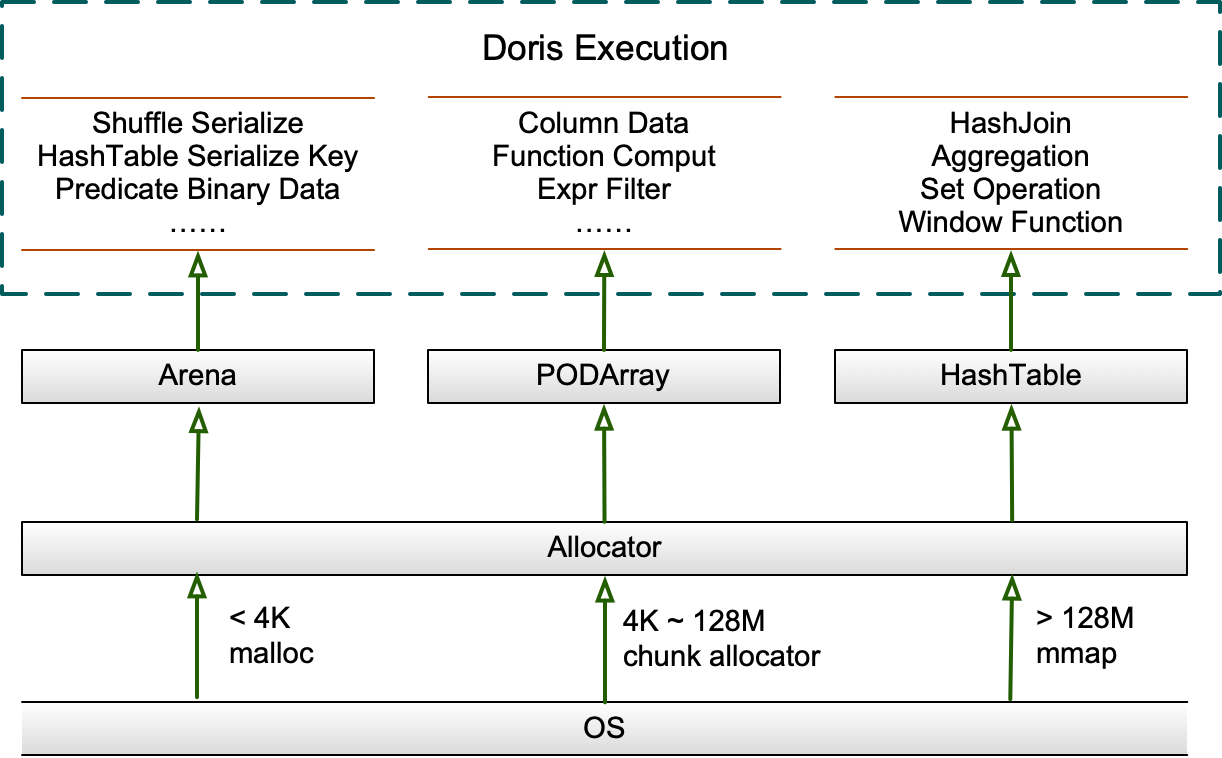
- Арена
Арена — это пул памяти, в котором хранится список фрагментов, которые должны быть выделены по запросу от Распределителя. Куски поддерживают выравнивание памяти. Они существуют в течение всего срока службы Арены и освобождаются при ее уничтожении (обычно после выполнения запроса).
Блоки в основном используются для хранения сериализованных или десериализованных данных во время перемешивания или сериализованных ключей в хэш-таблицах.
Начальный размер чанка составляет 4096 байт. Если текущий фрагмент меньше запрошенной памяти, в список будет добавлен новый фрагмент.
Если текущий фрагмент меньше 128M, новый фрагмент будет удвоен; если он больше 128 МБ, новый фрагмент будет максимум на 128 МБ больше, чем требуется.
Старый небольшой кусок не будет выделяться для новых запросов. Существует курсор, чтобы отметить разделительную линию между выделенными и нераспределенными фрагментами.
- Хеш-таблица
HashTables применимы для хэш-соединений, агрегаций, операций с множествами и оконных функций. Структура PartitionedHashTable поддерживает не более 16 вложенных HashTable. Он также поддерживает параллельное слияние хеш-таблиц, и каждое вложенное хеш-соединение можно масштабировать независимо.
Это может уменьшить общее использование памяти и задержку, вызванную масштабированием.
Если текущая HashTable меньше 8 М, она будет масштабирована в 4 раза;
Если размер больше 8 М, масштаб будет увеличен в 2 раза.
Если он меньше 2 ГБ, он будет масштабироваться при заполнении на 50 %;
и если он больше 2G, он будет масштабироваться, когда он будет заполнен на 75%.
Вновь созданные HashTables будут предварительно масштабироваться в зависимости от того, сколько данных в них будет храниться. Мы также предоставляем различные типы HashTable для различных сценариев. Например, для агрегации можно применить PHmap.
- PODArray
PODArray, как следует из названия, представляет собой динамический массив POD. Разница между ним и std::vector заключается в том, что PODArray не инициализирует элементы. Он поддерживает выравнивание памяти и некоторые интерфейсы std::vector.
Масштабируется в 2 раза. При уничтожении вместо вызова функции деструктора для каждого элемента освобождается память всего PODArray. PODArray в основном используется для сохранения строк в столбцах и применим во многих вычислениях функций и фильтрации выражений.
Интерфейс памяти
Являясь единственным интерфейсом, который координирует Arena, PODArray и HashTable, распределитель выполняет распределение памяти (MMAP) для запросов размером более 64 МБ.
Те, что меньше 4 КБ, будут напрямую выделены из системы через malloc/free; а те, что между ними, будут ускорены с помощью кэширующего ChunkAllocator общего назначения, который, согласно результатам нашего тестирования, увеличивает производительность на 10%.
ChunkAllocator попытается получить фрагмент указанного размера из FreeList текущего ядра без блокировок; если такого фрагмента не существует, он будет пытаться использовать другие ядра в режиме блокировки; если это все еще не удается, он запросит указанный объем памяти у системы и инкапсулирует его в блок.
Мы выбрали Jemalloc, а не TCMalloc, испытав их оба. Мы попробовали TCMalloc в наших тестах с высокой степенью параллелизма и заметили, что Spin Lock в CentralFreeList занимает 40% от общего времени запроса.
Отключение «агрессивного освобождения памяти» улучшило ситуацию, но это привело к гораздо большему использованию памяти, поэтому нам пришлось использовать отдельный поток для регулярной очистки кеша. Jemalloc, с другой стороны, был более производительным и стабильным в запросах с высокой степенью параллелизма.
После тонкой настройки для других сценариев он показал ту же производительность, что и TCMalloc, но потреблял меньше памяти.
Повторное использование памяти
Повторное использование памяти широко применяется на исполнительном уровне Apache Doris. Например, блоки данных будут повторно использоваться во время выполнения запроса. Во время Shuffle на стороне отправителя будет два блока, и они будут работать попеременно: один получает данные, а другой передает RPC.
При чтении планшета Дорис повторно использует столбец предиката, реализует циклическое чтение, фильтрацию, копирование отфильтрованных данных в верхний блок, а затем очистку.
При приеме данных в таблицу Aggregate Key, как только MemTable, которая кэширует данные, достигает определенного размера, они будут предварительно агрегированы, а затем будут записаны дополнительные данные.
Повторное использование памяти выполняется и при сканировании данных. Перед началом сканирования под задачу сканирования будет выделено количество свободных блоков (в зависимости от количества сканеров и потоков).
Во время каждого планирования сканера один из свободных блоков будет передаваться на уровень хранения для чтения данных.
После чтения данных блок будет помещен в очередь производителя для использования верхних операторов в последующих вычислениях. Как только оператор верхнего уровня скопирует вычислительные данные из блока, блок вернется в свободные блоки для следующего планирования сканера.
Поток, который предварительно выделяет свободные блоки, также будет отвечать за их освобождение после сканирования данных, поэтому не будет дополнительных накладных расходов. Количество свободных блоков каким-то образом определяет параллелизм сканирования данных.
Отслеживание памяти
Apache Doris использует MemTrackers для отслеживания выделения и освобождения памяти при анализе горячих точек памяти. MemTrackers хранит записи о каждом запросе данных, приеме данных, задаче сжатия данных и размере памяти каждого глобального объекта, такого как Cache и TabletMeta.
Он поддерживает как ручной подсчет, так и автоматическое отслеживание MemHook. Пользователи могут просматривать использование памяти в режиме реального времени в серверной части Doris на веб-странице.
Структура MemTrackers
Система MemTracker до Apache Doris 1.2.0 имела иерархическую древовидную структуру, состоящую из process_mem_tracker, query_pool_mem_tracker, query_mem_tracker, instance_mem_tracker, ExecNode_mem_tracker и т. д.
MemTrackers двух соседних слоев имеют отношение родитель-потомок. Следовательно, любые ошибки вычислений в дочернем MemTracker будут накапливаться до самого верха и приводить к большей степени достоверности.
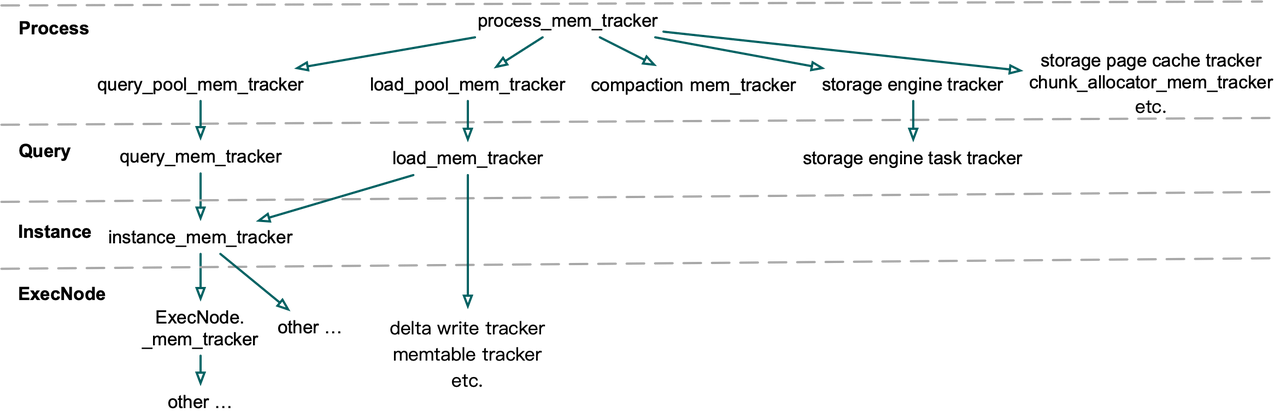
В Apache Doris 1.2.0 и новее мы значительно упростили структуру MemTrackers. MemTrackers делятся только на два типа в зависимости от их роли: MemTracker Limiter и остальные.
MemTracker Limiter, отслеживающий использование памяти, уникален для каждой задачи запроса/приема/уплотнения и глобального объекта; в то время как другие MemTrackers отслеживают горячие точки памяти при выполнении запроса, такие как HashTables в функциях Join/Aggregation/Sort/Window и промежуточные данные в сериализации, чтобы дать представление о том, как память используется в различных операторах, или предоставить ссылку на управление памятью в сброс данных.
Родительско-дочерние отношения между MemTracker Limiter и другими MemTrackers проявляются только при печати моментальных снимков. Вы можете думать о такой связи как о символической ссылке. Они не потребляются одновременно, и жизненный цикл одного не влияет на жизненный цикл другого.
Это упрощает их понимание и использование разработчиками.
MemTrackers (включая MemTracker Limiter и другие) помещаются в группу Maps. Они позволяют пользователям распечатывать общие снимки типа MemTracker, снимки задач запроса/загрузки/сжатия, а также определять запрос/загрузку с наибольшим использованием памяти или наибольшим перерасходом памяти.
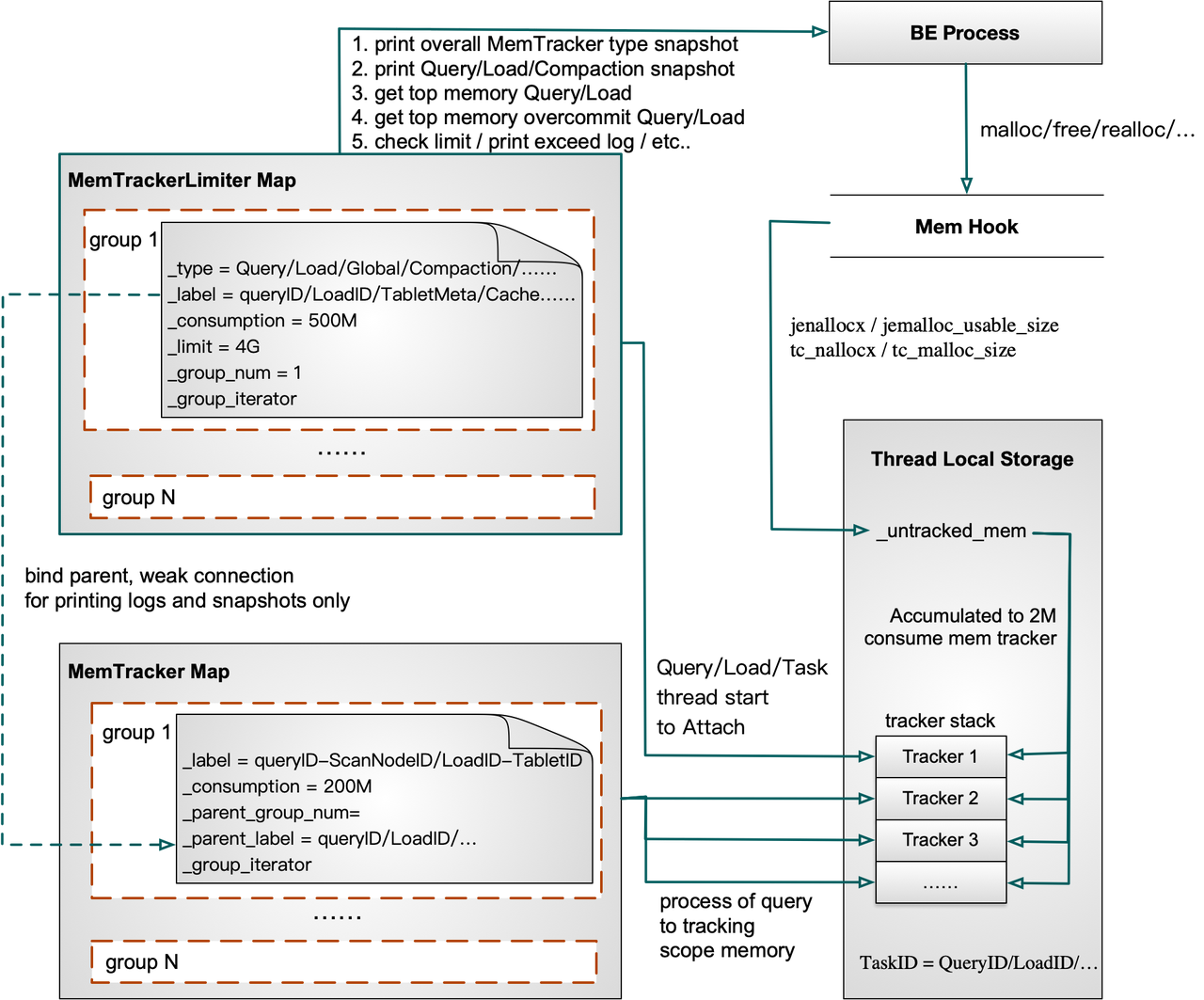
Как работает MemTracker
Чтобы рассчитать использование памяти для определенного выполнения, MemTracker добавляется в стек в Thread Local текущего потока. Перезагружая malloc/free/realloc в Jemalloc или TCMalloc, MemHook получает фактический размер выделенной или освобожденной памяти и записывает его в Thread Local текущего потока.
Когда выполнение будет выполнено, соответствующий MemTracker будет удален из стека. В нижней части стека находится MemTracker, который записывает использование памяти в течение всего процесса выполнения запроса/загрузки.
Теперь позвольте мне объяснить упрощенный процесс выполнения запроса.
* После запуска внутреннего узла Doris использование памяти всеми потоками будет записано в Process MemTracker.
* Когда запрос отправлен, Query MemTracker будет добавлен в стек локального хранилища потока (TLS) в потоке выполнения фрагмента.
* После планирования ScanNode ScanNode MemTracker будет добавлен в стек локального хранилища потока (TLS) в потоке выполнения фрагмента. Затем любая память, выделенная или освобожденная в этом потоке, будет записана как в Query MemTracker, так и в ScanNode MemTracker.
* После планирования сканера в стек TLS потока сканера будут добавлены Query MemTracker и Scanner MemTracker.
* Когда сканирование будет завершено, все MemTrackers в стеке TLS потока сканера будут удалены. Когда планирование ScanNode выполнено, ScanNode MemTracker будет удален из потока выполнения фрагмента. Затем, аналогичным образом, когда планируется узел агрегации, AggregationNode MemTracker добавляется в стек TLS потока выполнения фрагмента и удаляется после завершения планирования.
* Если запрос завершен, Query MemTracker будет удален из стека TLS потока выполнения фрагмента. На данный момент этот стек должен быть пуст. Затем из QueryProfile можно просмотреть пиковое использование памяти во время всего выполнения запроса, а также на каждом этапе (сканирование, агрегирование и т. д.).
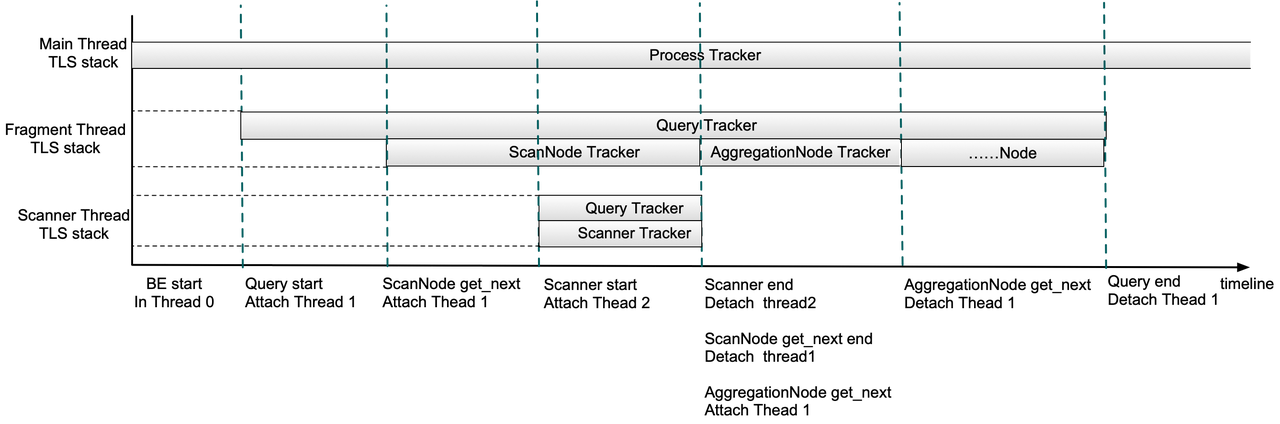
Как использовать MemTracker
Бэкэнд-веб-страница Doris демонстрирует использование памяти в реальном времени, которое делится на типы: запрос/загрузка/сжатие/глобальное. Отображается текущее потребление памяти и пиковое потребление.
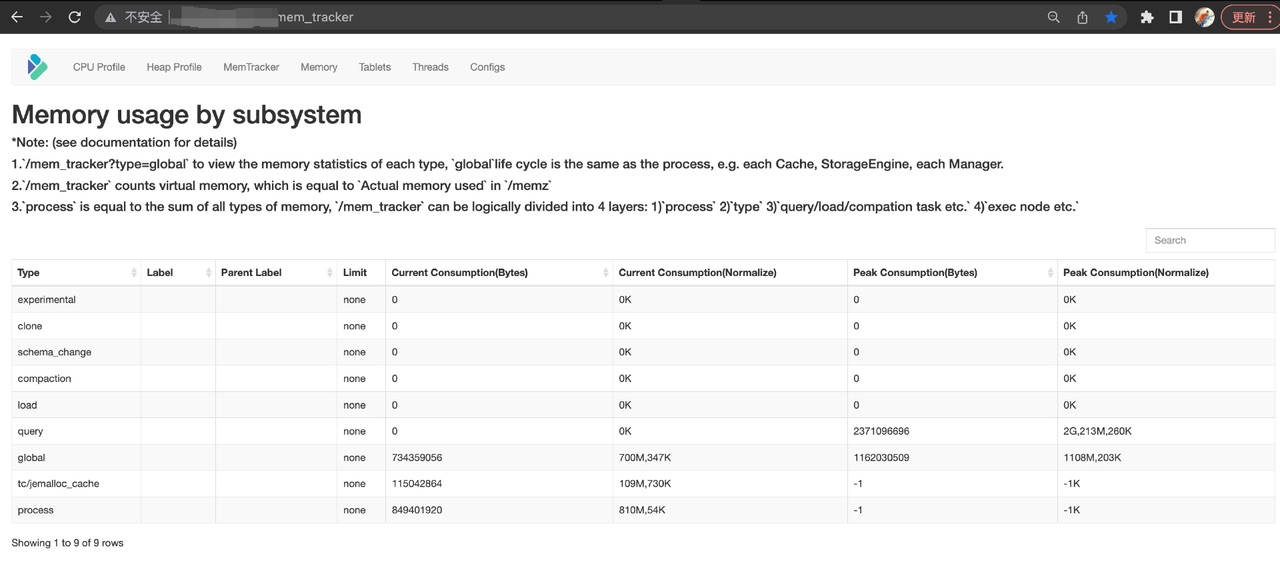
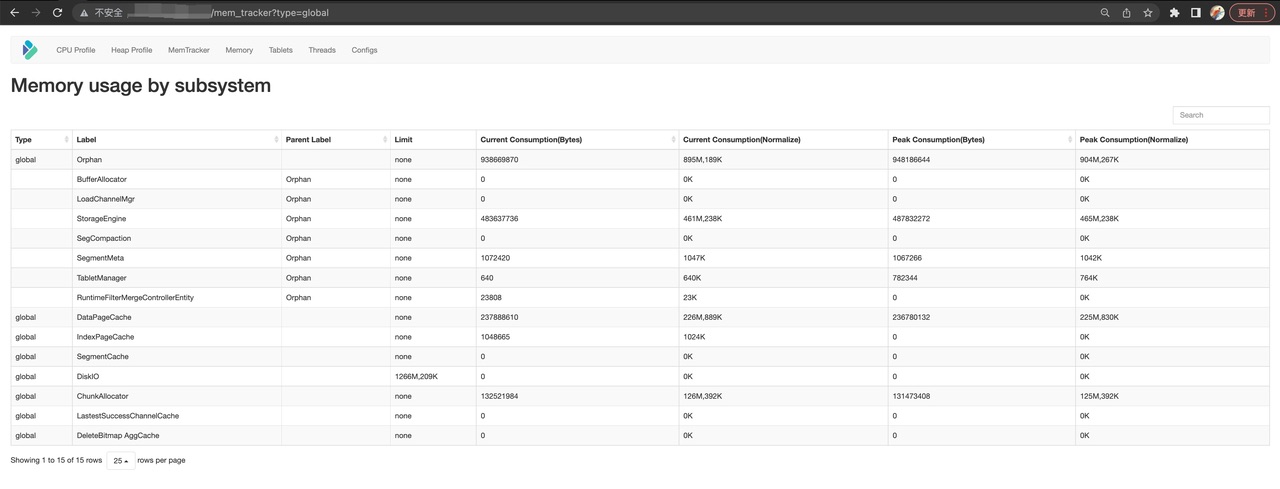
К глобальным типам относятся MemTrackers of Cache и TabletMeta.
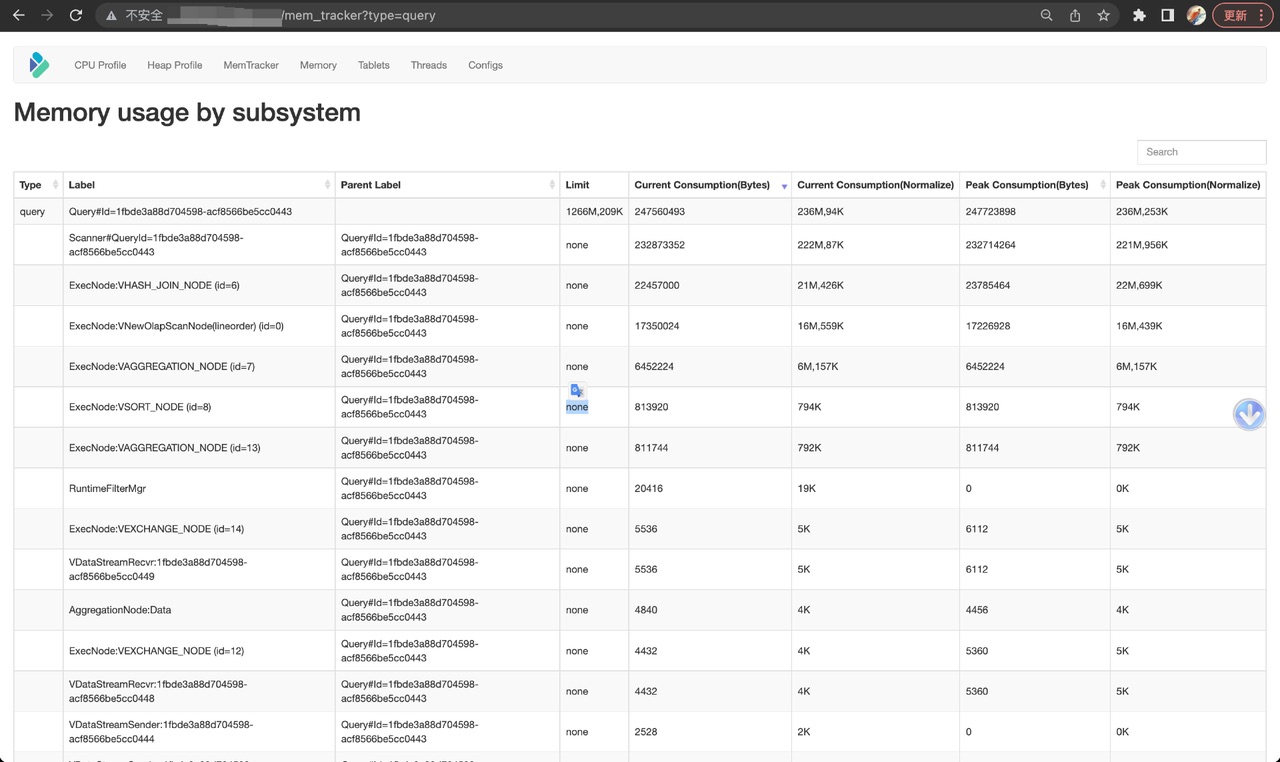
Из типов запросов вы можете увидеть текущее потребление памяти и пиковое потребление текущего запроса, а также операторы, которые он включает (вы можете сказать, как они связаны, по меткам). Статистику памяти по историческим запросам можно просмотреть в журналах аудита Doris FE или в журналах BE INFO.
Ограничение памяти
Благодаря широкому внедрению отслеживания памяти в серверные части Doris мы стали на один шаг ближе к устранению OOM, причины простоя серверной части и крупномасштабных сбоев запросов. Следующим шагом является оптимизация лимита памяти для запросов и процессов, чтобы контролировать использование памяти.
Ограничение памяти по запросу
Пользователи могут устанавливать ограничение памяти для каждого запроса. Если этот лимит будет превышен во время выполнения, запрос будет отменен. Но начиная с версии 1.2 мы разрешили Memory Overcommit, который является более гибким контролем ограничения памяти.
Если ресурсов памяти достаточно, запрос может потреблять больше памяти, чем ограничение, без отмены, поэтому пользователям не нужно уделять дополнительное внимание использованию памяти; если их нет, запрос будет ждать, пока не будет выделено новое пространство памяти, и только когда вновь освобожденной памяти будет недостаточно для запроса, запрос будет отменен.
В Apache Doris 2.0 мы реализовали безопасность исключений для запросов. Это означает, что любое недостаточное выделение памяти приведет к немедленной отмене запроса, что избавляет от необходимости проверять состояние "Отмена" на последующих шагах.
Ограничение памяти для процесса
На регулярной основе серверная часть Doris извлекает физическую память процессов и текущий доступный объем памяти из системы. Тем временем он собирает моментальные снимки MemTracker всех задач Query/Load/Compaction.
Если внутренний процесс превышает лимит памяти или памяти недостаточно, Дорис освободит часть памяти, очистив кэш и отменив ряд запросов или задач приема данных. Они будут регулярно выполняться отдельным потоком GC.
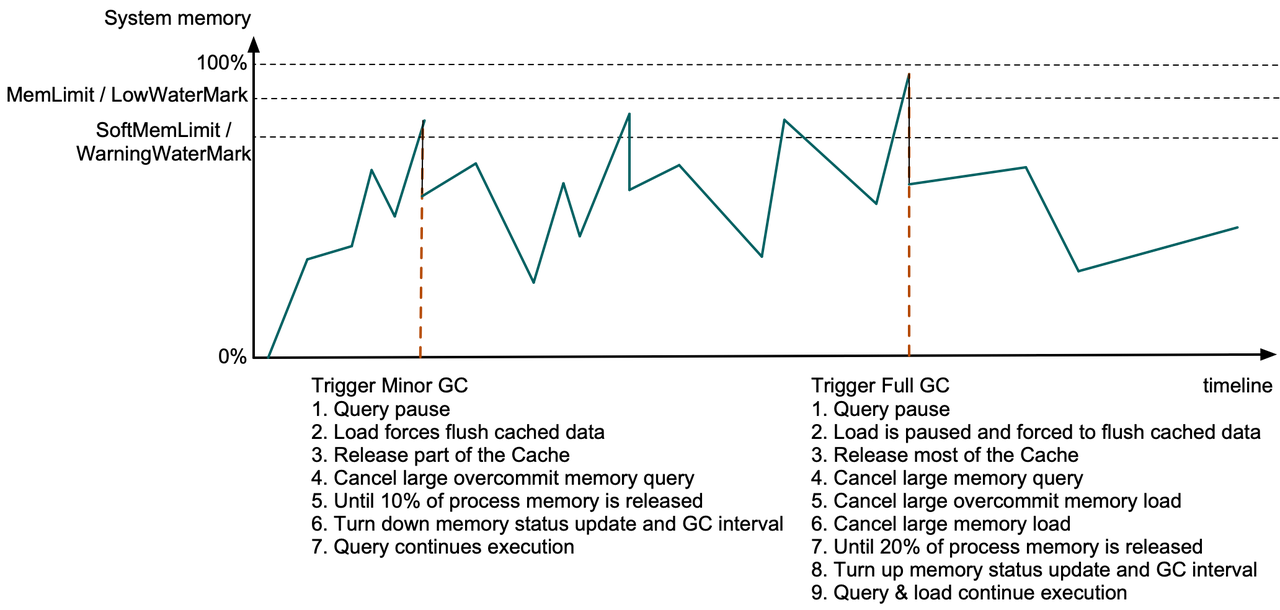
Если потребляемая память процесса превышает SoftMemLimit (по умолчанию 81% от общей системной памяти) или объем доступной системной памяти падает ниже предупреждающего водяного знака (менее 3,2 ГБ), незначительный GC будет сработал.
В этот момент выполнение запроса будет приостановлено на этапе выделения памяти, кэшированные данные в задачах приема данных будут принудительно сброшены, а часть кэша страниц данных и устаревшего кэша сегментов будут освобождены.
Если только что освобожденная память не покрывает 10 % памяти процесса, с включенной функцией Memory Overcommit, Дорис начнет отменять запросы, которые являются самыми большими «избыточными выделениями», пока не будет достигнута цель 10 % или все запросы не будут отменены.
Затем Дорис сократит интервал проверки системной памяти и интервал GC. Запросы будут продолжены после того, как станет доступно больше памяти.
Если потребляемая память процесса превышает MemLimit (по умолчанию 90 % от общего объема системной памяти) или объем доступной системной памяти падает ниже нижней отметки (менее 1,6 ГБ), Полный сборщик мусора будет отключен. сработал.
В это время задачи приема данных будут остановлены, а весь кэш страниц данных и большинство других кэшей будут освобождены.
Если после всех этих шагов вновь освобожденная память не покрывает 20% памяти процесса, Дорис просмотрит все MemTrackers и найдет самые требовательные к памяти запросы и задачи загрузки, и отменит их одну за другой.
Только после достижения цели 20 % интервал проверки системной памяти и интервал GC будут увеличены, а запросы и задачи загрузки будут продолжены. (Одна операция сборки мусора обычно занимает от сотен мкс до десятков мс.)
Влияния и результаты
После оптимизации распределения памяти, отслеживания памяти и ограничения памяти мы значительно повысили стабильность и производительность Apache Doris в качестве платформы для хранения аналитических данных в режиме реального времени. Сбой OOM в бэкэнде сейчас редкость.
Даже при наличии OOM пользователи могут найти корень проблемы на основе журналов, а затем устранить ее. Кроме того, благодаря более гибким ограничениям памяти для запросов и приема данных пользователям не нужно тратить дополнительные усилия на управление памятью, когда ее достаточно.
На следующем этапе мы планируем обеспечить завершение запросов при перерасходе памяти, что означает, что меньшее количество запросов придется отменять из-за нехватки памяти.
Мы разбили эту задачу на конкретные направления работы: безопасность исключений, изоляция памяти между группами ресурсов и механизм сброса промежуточных данных.
Если вы хотите познакомиться с нашими разработчиками, здесь вы нас найдете.