Кэширование – это стратегия, которая помогает экономить ресурсы и повышать производительность. Если у вас есть часто выполняемый дорогостоящий запрос с редко меняющимся результатом, кэширование является идеальным решением.
Кэшируя результат этого запроса, вы можете вернуть кешированный результат, когда это необходимо. Результат тот же, но вы избавляетесь от необходимости выполнять дорогостоящий запрос. Выигрывают все.
В этой статье мы рассмотрим использование функций Salesforce для кэширования ресурсоемких запросов.
Например, мы хотим запросить некоторое значение для большого количества записей, и страница, требующая этого запроса, часто загружается. Однако результат не изменится от одного выполнения запроса к другому.
Введение в проблему
В нашей демонстрации пример запроса будет «количество компаний, в которых работает более 10 000 сотрудников». Мы представляем вариант использования, в котором есть страница, которую часто загружает наш отдел продаж, и часть страницы показывает общее количество компаний в нашей организации Salesforce, которые соответствуют этому условию.
В идеале ресурсоемкий запрос не будет выполняться каждый раз при загрузке страницы, а вместо этого мы должны реализовать механизм кэширования.
Чтобы решить эту проблему, мы:
- Используйте Heroku Connect, чтобы синхронизировать наш список компаний из Salesforce с Heroku Postgres (или используйте таблицу уже в Postgres).
2. Создайте функцию Salesforce, чтобы запрашивать Postgres и возвращать этот счетчик.
3. Сохраните полученное значение в Heroku Redis в течение указанного времени.
4. Используйте функцию Salesforce для проверки значения в Redis. Если значение существует в Redis, верните его. Если нет, запустите запрос и сохраните результат в Redis.
Поток данных выглядит следующим образом:
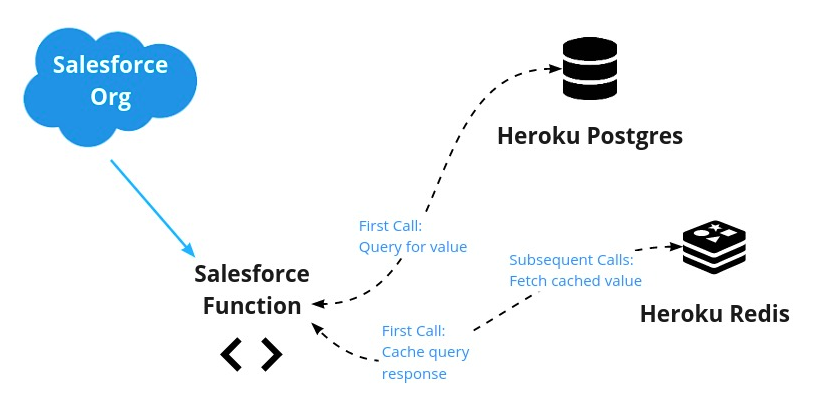
Конечно, в Apex есть API кэша платформы для упрощения кэширование для определенных случаев использования. В нашем случае — и в демонстрационных целях — мы изучим это решение для кэширования, использующее функции Salesforce.
Прежде чем мы продолжим, давайте кратко представим каждый из элементов нашей системы.
* Функция Salesforce: функция Salesforce, позволяющая запускать некоторый код (JavaScript или Java в настоящее время являются поддерживаемые языки), который все еще находится в защищенной области вашей организации Salesforce, но не работает в вашей организации. Это позволяет разгрузить большие рабочие нагрузки или привести к превышению лимитов.
* Heroku Connect: инструмент семейства Salesforce для двунаправленной синхронизации данных между вашей организацией Salesforce и Heroku Postgres. Как и в случае с функциями Salesforce, вы можете использовать этот инструмент, не влияя на ограничения Salesforce.
* Heroku Postgres: полностью управляемый экземпляр PostgreSQL< /a> (реляционная база данных) на Heroku.
* Heroku Redis: полностью управляемый экземпляр Redis (хранилище ключей и значений в памяти) на Heroku.
Предпосылки
Чтобы использовать все вышеперечисленные компоненты, у вас должны быть следующие компоненты:
* аккаунт Heroku * Создано приложение Heroku с Postgres и Redis дополнения прилагаются * Организация Salesforce с включенными функциями. * Локальная среда разработки функций Salesforce. * [Необязательно] Heroku Connect синхронизируется с Postgres (прилагается пример набора данных)
Имея предварительные условия, мы можем начать их подключение. Сначала мы рассмотрим подключение сред. Затем мы рассмотрим код, необходимый для реализации волшебства.
Доступ к службам данных Heroku из функции Salesforce
С вашими учетными записями и доступом мы можем двигаться вперед с самой функцией. Предположим, вы начинаете новый проект и у вас есть пустая база данных Postgres.
Если вы новичок в функциях, мы рекомендуем пройти этот базовый процесс, чтобы получить представление о вещах, прежде чем привлекать дополнительные части. Если у вас уже есть проект Salesforce или вы синхронизируете данные через Heroku Connect, вы можете изменить следующие команды в соответствии со своими потребностями.
Сначала создайте проект Salesforce DX, чтобы разместить свою функцию.
sfdx force:project:create -n MyDataProj
Затем перейдите в каталог проекта и выполните следующую команду, чтобы создать новую функцию JavaScript.
sf generate function -n yourfunction -l javascript
Это создаст папку /functions с шаблоном приложения Node.js.
Затем свяжите свою функцию Salesforce и свои среды Heroku, добавив своего пользователя Heroku в качестве соавтора в вычислительную среду вашей функции:
sf env compute collaborator add --heroku-user <yourherokuaccount@email.com>
Среды теперь могут совместно использовать сервисы обработки данных Heroku.
Затем вам нужно будет получить имя вычислительной среды, чтобы вы могли подключить к ней хранилища данных.
sf env list
Чтобы подключить хранилища данных Heroku, вам также понадобятся имена надстроек. Вы можете получить название дополнений с помощью следующей команды:
heroku addons -a <yourherokuapp>
Вывод будет выглядеть следующим образом. «Имя» каждой надстройки отображается фиолетовым цветом (например, postgresql-closed-46065).
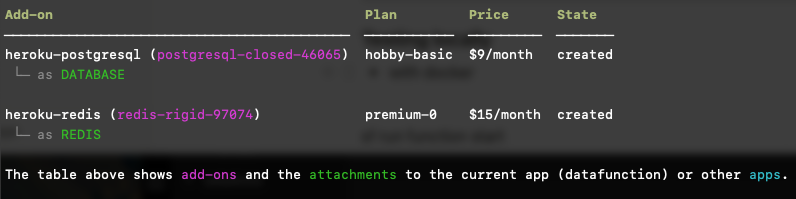
Используя названия вычислительной среды и надстроек, выполните следующие команды, чтобы подключить Postgres и Redis к вашей вычислительной среде:
heroku addons:attach <your-heroku-postgres-name> --app <your-compute-environment-name>
heroku addons:attach <your-heroku-redis-name> --app <your-compute-environment-name>
Теперь, когда мы подключили нашу среду Salesforce Function к нашим хранилищам данных Heroku, мы можем написать код нашей функции Salesforce.
Реализация функции Salesforce
Прежде чем мы начнем писать код JavaScript для этой функции Salesforce, давайте настроим нашу локальную среду разработки с необходимыми библиотеками.
В развернутой среде наша функция будет получать информацию о подключении к данным из переменных среды. Для нашей локальной среды мы будем использовать пакет узла dotenv для чтения файла с именем .env. с этой информацией. Мы можем создать этот файл с помощью следующей команды:
heroku config -a <yourherokuapp> --shell > .env
Далее давайте установим пакеты, необходимые для взаимодействия с Postgres и Redis, вместе с dotenv:
npm install dotenv pg redis
Настройка нашего проекта завершена. Давайте напишем код нашей функции.
Подключение к Heroku Postgres и Redis
Давайте начнем с добавления кода, который позволяет нам читать и сохранять данные в Heroku Postgres и Heroku Redis. (Примечание. В Heroku Devcenter есть полезная документация по подключению к Postgres и Redis из Node.js.)
Код нашей функции будет находиться в файле index.js папки functions нашего проекта (например, MyDataProj/functions/index.js). ). Мы открываем этот файл и добавляем следующие строки вверху. Эти строки будут импортировать модули, которые мы только что установили.
import "dotenv/config";
import pg from "pg";
const { Client } = pg;
import { createClient } from 'redis';
Основной частью функции является раздел, который экспортируется. Значение, возвращенное из этого блока, будет возвращено вызывающей функции.
export default async function (event, context, logger) {
}
Чтобы наш код оставался чистым и модульным, давайте сначала напишем несколько вспомогательных функций внизу файла. Нам нужны функции, которые мы можем вызывать для управления нашим подключением к Postgres и Redis. Под (и вне) экспортируемой функции мы добавляем следующие две вспомогательные функции:
/* Helper functions */
// Connect to PostgreSQL
async function pgConnect() {
const DATABASE_URL = process.env.DATABASE_URL;
if (!DATABASE_URL) {
throw new Error("DATABASE_URL is not set");
}
const client = new Client({
connectionString: DATABASE_URL,
ssl: {
rejectUnauthorized: false
}
});
await client.connect();
return client;
}
// Connect to Redis
async function redisConnect() {
const REDIS_URL = process.env.REDIS_URL;
if (!REDIS_URL) {
throw new Error("REDIS_URL is not set");
}
const redis = createClient({
url: process.env.REDIS_URL,
socket: {
tls: true,
rejectUnauthorized: false
}
});
await redis.connect();
redis.on('error', err => {
console.log('Error ' + err);
});
return redis;
}
Загрузить образец набора данных
Для простоты нашего примера давайте загрузим небольшой набор данных в Postgres. Мы можем создать таблицу с именем «company», выполнив команды базы данных, указанные в следующем суть.
Загрузите содержимое этого списка в файл с именем company.sql. Чтобы запустить команды базы данных из интерфейса командной строки Heroku, выполните следующие действия:
heroku pg:psql -a <yourherokuapp>
DATABASE=> i /path/to/company.sql
Вы можете убедиться, что ваш образец набора данных был загружен, выполнив следующий запрос:
DATABASE=> select * from company;
Напишите основную функцию
Все готово! Теперь у нас осталось немного кода для нашей фактической функции. Код нашей функции доступен в виде gist и выглядит следующим образом. Вы можете скопировать это в свой файл index.js.
Мы рассмотрим и объясним каждый раздел кода.
export default async function (event, context, logger) {
logger.info(`Invoking Datafunction with payload ${JSON.stringify(event.data || {})}`);
const redis = await redisConnect();
let cached = {};
// Check Redis for cached entry first
let big_biz_count = await redis.get(`big_biz`);
if (big_biz_count) {
// If cached entry found, return it and be done.
logger.info(`Found cache entry = ${big_biz_count}`);
cached = "true"
redis.quit();
return { big_biz_count, cached }
} else {
// If cached entry not found, then:
// 1. Run the Postgres query
// 2. Store the result in Redis
// 3. Return the result and be done
logger.info(`did not find in cache, returned ${big_biz_count}`);
cached = "false"
const pg = await pgConnect();
const { rows } = await pg.query('SELECT COUNT(*) FROM company WHERE employees>10000;');
big_biz_count = rows[0].count.toString();
redis.set(`big_biz`, big_biz_count, {
EX: 30, // seconds to keep before expiring
NX: true
});
// Close the connections
redis.quit();
pg.end();
// Return the value from Postgres, now stored in Redis
return { big_biz_count, cached }
}
}
Объяснение кода
Как упоминалось в начале этой статьи, мы хотим узнать, сколько компаний имеют более 10 000 сотрудников, и вернуть это число. Мы хотим кэшировать число, потому что это «дорогой запрос».
В нашем примере стол небольшой, поэтому он не такой уж и дорогой. Однако он представляет собой «дорогой запрос», который мы можем захотеть выполнить в реальной жизни. Вы поняли идею.
Давайте пройдемся по основным разделам кода нашей функции.
- Подключитесь к Redis и проверьте, есть ли там значение.
const redis = await redisConnect();
let cached = {};
let big_biz_count = await redis.get(`big_biz`);
- Если значение есть, то есть оно было кэшировано, мы можем вернуть кэшированное значение и закончить.
if (big_biz_count) {
cached = "true"
redis.quit();
return { big_biz_count, cached }
- Если кэшированное значение не найдено, у нас нет другого выбора, кроме как выполнить запрос в нашей базе данных Postgres.
} else {
cached = "false"
const pg = await pgConnect();
const { rows } = await pg.query('SELECT COUNT(*) FROM company WHERE employees>10000;');
big_biz_count = rows[0].count.toString();
- Затем мы сохраняем значение, возвращенное из нашего запроса, в Redis.
redis.set(`big_biz`, big_biz_count, {
EX: 30, // seconds to keep before expiring
NX: true
});
- Наконец, мы закрываем наши подключения к хранилищу данных и возвращаем результат запроса.
redis.quit();
pg.end();
return { big_biz_count, cached }
Вы можете немного изменить код или добавить обработку ошибок. Однако на самом базовом уровне это все, что нужно.
Проверка функции
Теперь, когда у нас есть функция Salesforce, мы можем протестировать ее локально. Сначала мы запускаем сервер функций.
sf run function start
Затем мы вызываем функцию с полезной нагрузкой с другого терминала.
sf run function -l http://localhost:8080 -p '{"payloadID": "info"}'
Когда вы вызываете функцию для тестовой базы данных в первый раз, вы должны увидеть следующий вывод, потому что в кэше не было значения:
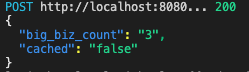
Однако после первого запуска значение сохраняется в нашем экземпляре Heroku Redis. Последующий запуск функции Salesforce возвращает то же значение, но на этот раз значение cached равно true.
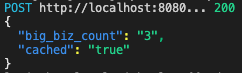
Когда мы добавили значение в Redis, мы установили срок действия кеша на 10 секунд. Это облегчает тестирование. Однако в реальной среде продолжительность жизни ваших значений кэша должна иметь смысл для вашего делового варианта использования.
Например, если результат изменяется после ночного запуска отчета, можно установить срок действия кэша каждые 24 часа. Более того, вы можете создать еще одну функцию Salesforce, которая обновит кэш новым значением сразу после завершения отчета.
Все содержимое index.js можно загрузить здесь.
Заключение
Мы сделали это. Кэширование — отличная стратегия для снижения нагрузки на ресурсы при одновременном обеспечении более быстрых ответов. С помощью функций Salesforce мы можем подключить наши организации Salesforce к хранилищам данных Heroku (таким как Postgres и Redis) и создать механизмы для кэширования.
Функции Salesforce позволяют нам выполнять задачи, которые обычно требуют большой нагрузки, вызывают тайм-ауты или превышают другие ограничения, установленные Salesforce. Кэширование — это всего лишь один вариант использования, но он может дать огромные преимущества, и его легко реализовать. А теперь повеселитесь!
Фото Нейта Гранта на Unsplash