
Репликация баз данных PostgreSQL с использованием асинхронного Python и RabbitMQ для обеспечения высокой доступности
5 мая 2022 г.Важность репликации
Базы данных являются одним из столпов любого приложения. Если сервер базы данных выйдет из строя, вся система больше не будет выполнять свои основные функции: аутентифицировать пользователей, публиковать наши любимые посты на Hackernoon, хранить комментарии к селфи влюбленных…
Вот почему проектирование системы для Высокой доступности (способность распределенной системы работать непрерывно без сбоев в течение заданного периода времени) имеет важное значение.
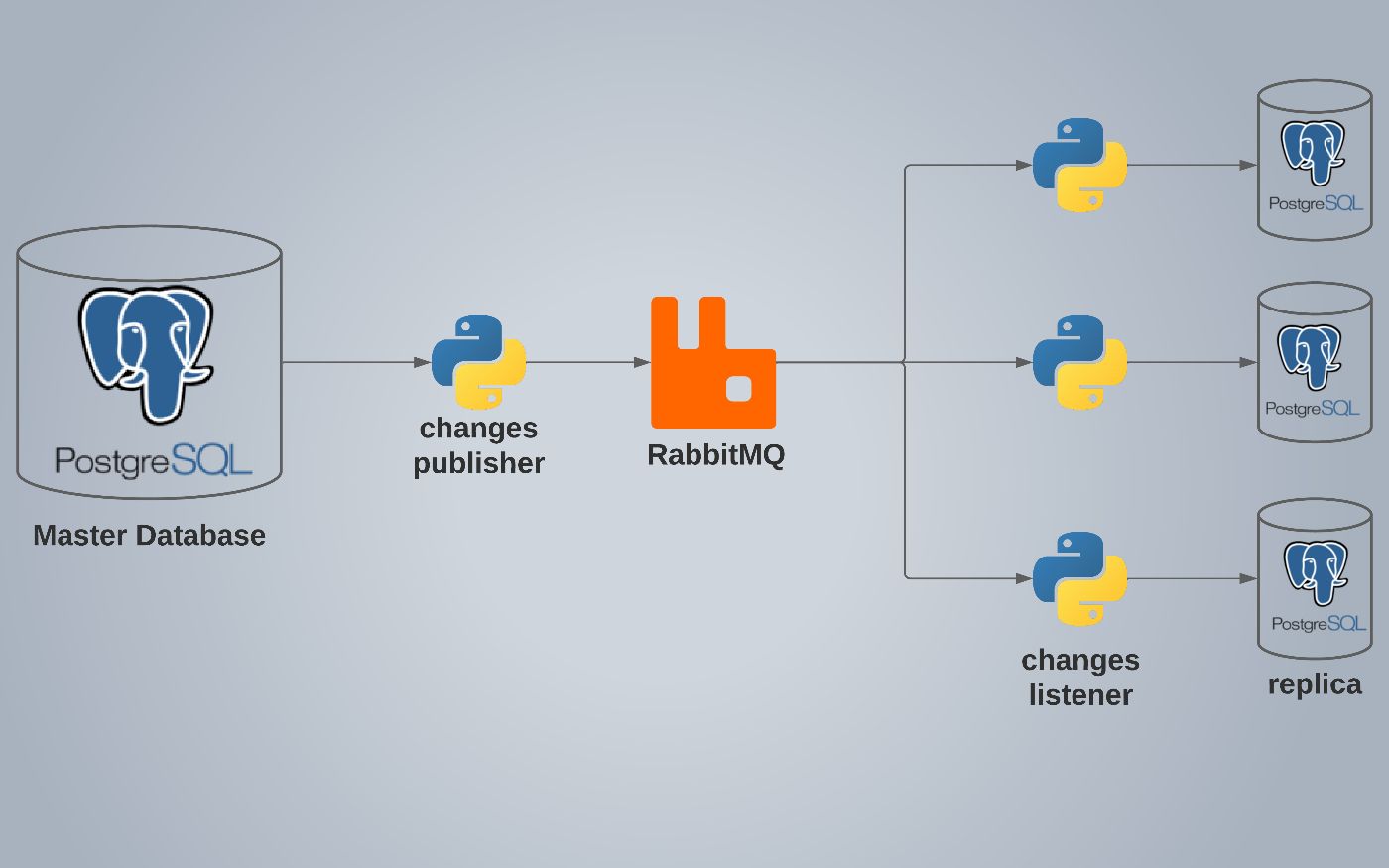
Одним из решений для достижения высокой доступности является наличие большего количества компонентов, чем необходимо. Таким образом, для нашей системы баз данных мы можем реплицировать основную базу данных, а в случае сбоя заменить ее на одну из рабочих реплик.
Представляем решение
Во-первых, мы должны перечислить наши ограничения:
- клиенты должны напрямую подключаться к базе данных и не взаимодействовать с нашей системой репликации.
- вся наша система должна быть очень быстрой и ресурсоэффективной
Как узнать, какая часть таблиц базы данных была вставлена, удалена или изменена?
ТРИГГЕРЫ! ОНИ ЗАМЕЧАТЕЛЬНЫЕ !!
Триггеры базы данных позволяют нам выполнять функции SQL при получении события. Событием может быть любая операция, такая как INSERT, UPDATE, DELETE или TRUNCATE. Триггеры полезны в самых разных случаях, например для проверки ограничений или повышения производительности. В нашем случае мы будем использовать триггеры для уведомления нашего слушателя Python об удалении или добавлении данных. Мы определяем процедуру под названием notify_account_changes(), которая будет обрабатывать отправку уведомлений об изменениях в базе данных. Вот как определить триггер для таблицы «пользователи»:
```sql
СОЗДАТЬ ТРИГГЕР users_changed
ПОСЛЕ ВСТАВКИ ИЛИ ОБНОВЛЕНИЯ
НА пользователей
ДЛЯ КАЖДОГО РЯДА
ВЫПОЛНИТЬ ПРОЦЕДУРУ notify_account_changes();
Хорошо, теперь к следующей проблеме.
Как, черт возьми, теперь мы можем уведомлять программы за пределами нашего сервера об этих изменениях?
из документации PostgreSQL (https://www.postgresql.org/docs/current/sql-notify.html):
Команда
NOTIFYотправляет событие уведомления вместе с дополнительной строкой «полезной нагрузки» каждому клиентскому приложению, которое ранее выполнилоLISTEN channelдля указанного имени канала в текущей базе данных.
Другими словами, мы можем иметь много слушателей на канале, выполнив LISTEN имя_канала. А для отправки уведомлений мы используем команду NOTIFY или встроенную системную функцию pg_notify('channel_name', 'payload'). Полезная нагрузка — это сообщение, которое мы хотим отправить. В нашем случае полезная нагрузка уведомления будет включать:
- TG_TABLE_NAME: имя таблицы, которая запустила триггер.
- TG_OP: операция запуска триггера (INSERT, DELETE…).
- NEW: это переменная, заданная TRIGGER, чтобы мы знали, какие новые вставленные или обновленные данные.
- OLD: это также переменная, заданная TRIGGER, чтобы мы знали старые значения перед обновлением или удалением записи.
Вот код для notify_account_changes()
```sql
СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ФУНКЦИЮ notify_account_changes()
Возврат триггера AS
НАЧИНАТЬ
ВЫПОЛНИТЬ pg_notify(
'пользователи_изменены',
json_build_object(
'стол', TG_TABLE_NAME,
'операция', TG_OP,
'новая_запись', row_to_json(NEW),
'старая_запись', row_to_json(OLD)
)::текст
ВОЗВРАТ НОВОГО;
КОНЕЦ;
$$ ЯЗЫК plpgsql;
Теперь мы получили уведомление об изменениях от триггеров. На этом этапе мы завершили работу с базой данных.
Прослушивание уведомлений от Python
для подключения к PostgreSQL мы будем использовать единственную и неповторимую библиотеку «psycopg2».
мы можем установить его, используя:
``` ударить
pip установить psycopg2
Чтобы подключиться к базе данных PostgreSQL и начать прослушивание:
```питон
conn = psycopg2.connect(host="localhost", dbname="ИМЯ БД", пользователь="ИМЯ ПОЛЬЗОВАТЕЛЯ", пароль="ПАРОЛЬ")
conn.set_isolation_level (psycopg2.extensions.ISOLATION_LEVEL_AUTOCOMMIT)
курсор = соединение.курсор()
cursor.execute("СЛУШАТЬ пользователей_изменено;")
cursor.execute() позволяет нам выполнять команды SQL, такие как SELECT или INSERT…
Теперь, когда мы слушаем уведомления. Как мы можем их разобрать?
```питон
деф handle_notify():
конн.опрос()
для уведомления в conn.notify:
печать (уведомить.полезная нагрузка)
conn.notify.clear()
петля = uvloop.new_event_loop()
asyncio.set_event_loop(цикл)
loop.add_reader (соединение, handle_notify)
loop.run_forever()
Здесь мы использовали асинхронные библиотеки uvloop и asyncio. Строка loop.add_reader(conn, handle_notify) позволяет нам вызывать функцию handle_notify() только тогда, когда файловый дескриптор conn (который представляет соединение с нашей базой данных) имеет входящий поток данных. После выполнения INSERT INTO users VALUES (2,'al');
Результат:
```json
"таблица": "пользователи",
"операция": "ВСТАВИТЬ",
"новый рекорд" : {
"идентификатор": 2,
"имя": "аль"
"старая_запись": ноль
Теперь, когда мы получили всю необходимую информацию об изменениях в базе данных. Как мы можем воспроизвести это?
Прежде чем мы это сделаем, мы должны решить некоторые проблемы:
- Очереди NOTIFY PostgreSQL не являются постоянными. Если мы не слушаем, уведомления будут потеряны.
- Наличие большого количества подключений слушателей может замедлить работу сервера базы данных.
Представляем RabbitMQ
для решения этих проблем мы представляем RabbitMQ.
RabbitMQ — это брокер обмена сообщениями — посредник для обмена сообщениями. Это дает вашим приложениям общую платформу для отправки и получения сообщений, а ваши сообщения — безопасное место для жизни до тех пор, пока они не будут получены.
RabbitMQ позволяет нам отправлять сообщения с помощью очередей в разные части нашей распределенной системы. Он использует постоянные очереди для сохранения сообщений и транзакций, чтобы гарантировать их правильное выполнение.
Так как же работает RabbitMQ?
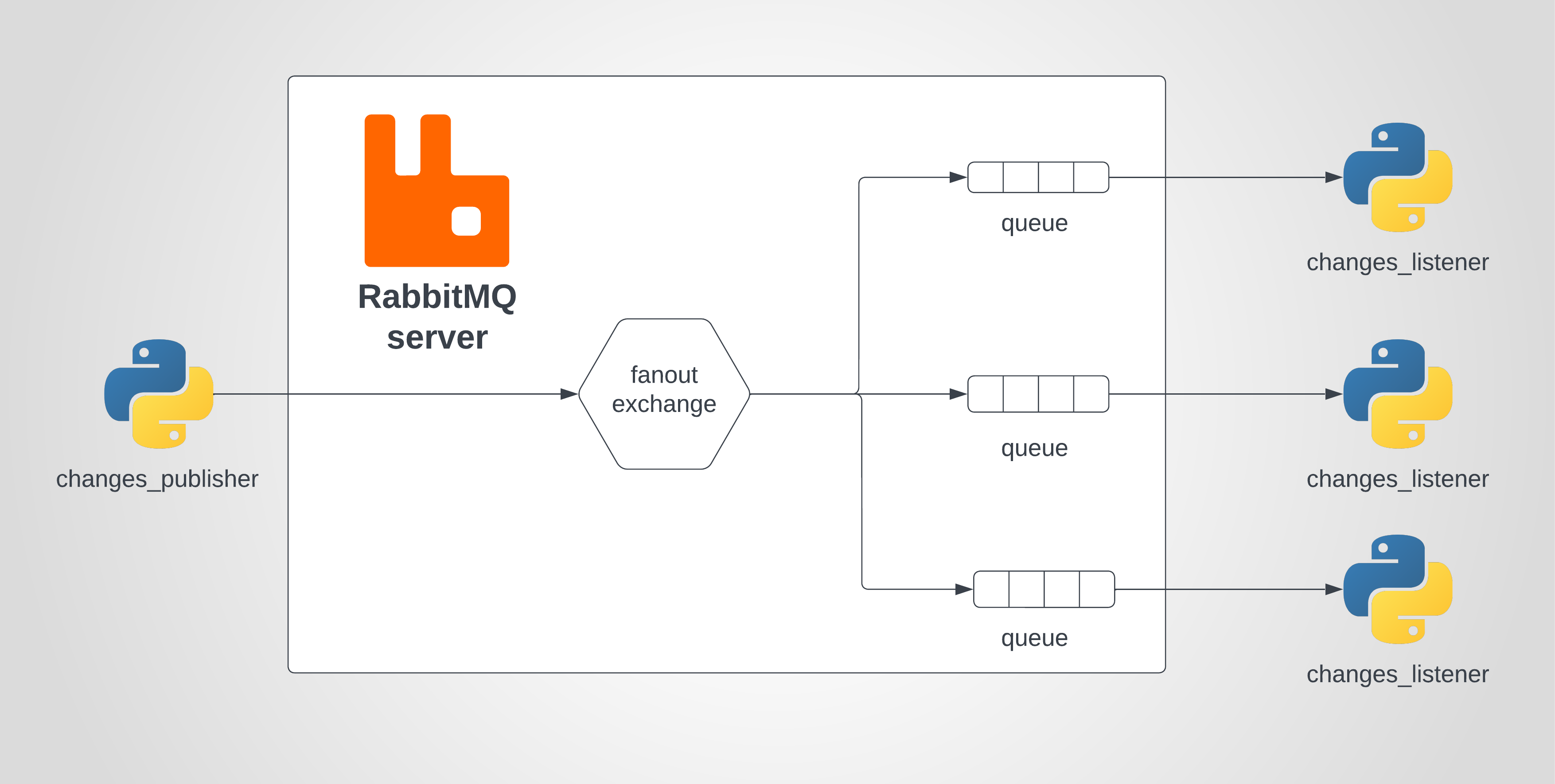
Каждый скрипт python changes_listener будет иметь свою собственную очередь. для отправки сообщений во все очереди мы отправим их на разветвленный обмен с помощью скрипта changes_publisher. обмен разветвления рассылает каждое сообщение всем подключенным очередям.
Чтобы использовать RabbitMQ с python, мы будем использовать библиотеку pika.
``` ударить
пип установить пика
В changes_publisher.py мы подключимся к серверу RabbitMQ. Затем мы создадим обмен с именем «replication». Для каждого полученного уведомления мы будем транслировать его во все очереди RabbitMQ.
```питон
соединение = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
канал = соединение.канал()
channel.exchange_declare (exchange = 'репликация', exchange_type = 'разветвление')
деф handle_notify():
конн.опрос()
для уведомления в conn.notify:
channel.basic_publish(exchange='replication', routing_key='', body=notify.payload)
conn.notify.clear()
И в нашем changes_listener.py
```питон
соединение = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
канал = соединение.канал()
channel.exchange_declare (exchange = 'репликация', exchange_type = 'разветвление')
результат = channel.queue_declare (очередь = '', исключительный = Истина)
имя_очереди = результат.метод.очередь
channel.queue_bind (обмен = 'репликация', очередь = имя_очереди)
Обратный вызов def (канал, метод, свойства, тело):
op = json.loads(body.decode('utf-8'))
печать (оп)
channel.basic_consume (queue = имя_очереди, on_message_callback = обратный вызов, auto_ack = True)
канал.start_consuming()
Здесь мы подключаемся к RabbitMQ, объявляем разветвленный обмен «репликацией», объявляем временную очередь, привязываем очередь к обмену и начинаем потреблять сообщения. при каждом новом полученном сообщении будет выполняться наша функция обратного вызова.
Выполнение этого SQL-запроса UPDATE users SET name='alfonso' WHERE id=2; приведет к следующему выводу из changes_listener.py:
```json
'таблица': 'пользователи',
'операция': 'ОБНОВЛЕНИЕ',
'новый рекорд': {
'идентификатор': 2,
'имя': 'альфонсо'
'старая_запись': {
'идентификатор': 2,
'имя': 'аль'
Запись изменений в реплики
Теперь, когда мы получили изменения в нашем скрипте Python, все, что осталось сделать, это зафиксировать эти изменения. Для этого нам нужно изменить нашу функцию обратного вызова, чтобы она генерировала SQL-команды из каждого полученного сообщения JSON:
```javascript
деф операция_обработчик (оп):
Деф handle_insert():
таблица, данные = op['таблица'], op['новая_запись']
sql = f"""ВСТАВИТЬ В {таблицу}
ЗНАЧЕНИЯ ('{данные['id']}','{данные['имя']}');
вернуть sql
SQL = Нет
если op['операция'] == 'ВСТАВИТЬ':
sql = handle_insert()
здесь мы можем добавить другие обработчики операций
вернуть sql
Обратный вызов def (канал, метод, свойства, тело):
op = json.loads(body.decode('utf-8'))
sql = обработчик_операции (оп)
курсор.execute(sql)
В обратном вызове, когда мы получаем сообщение, мы конвертируем его в словарь и передаем в operation_handler(op). Эта функция рассмотрит сообщение и вернет соответствующий SQL, используя его значения.
ЭТО ОНО. ТЕПЕРЬ У НАС ВСЕ ЧАСТИ РАБОТАЮТ.
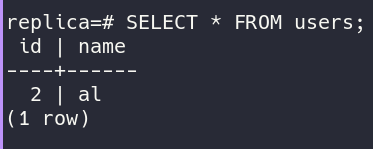
Если мы проверим базу данных реплики после выполнения простого SQL-запроса INSERT INTO users VALUES (2,'al'); мы обнаружим это:
PS: PostgreSQL имеет встроенные опции для репликации базы данных, но наше решение позволяет нам полностью контролировать процесс репликации. Мы можем реплицировать только определенные таблицы, определенных пользователей или изменять записи как угодно.
Заключительные примечания
Шаг за шагом мы завершили внедрение нашей системы репликации базы данных. Мы перешли от настройки триггеров и уведомлений в базе данных к трансляции изменений с помощью RabbitMQ и, наконец, к записи изменений обратно в реплику PostgreSQL.
Внедрение этого решения было непростым, потребовалось много штук, но оно того стоило. Предоставление пользователям нулевого времени простоя является огромным бизнес-преимуществом.
Вот код проекта https://github.com/Bechir-Brahem/postgres-database-replicator
Спасибо, что читаете <3
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27283)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)