Q-обучение — это алгоритм RL для поиска оптимальной функции q-значения. Это фундаментальный алгоритм в RL, который лежит в основе впечатляющих достижений в этой области за последние 10 лет.
Добро пожаловать на мой курс обучения с подкреплением ❤️
Это вторая часть моего практического курса по обучению с подкреплением, который проведет вас с нуля до HERO 🦸♂️.
Если вы пропустили часть 1, прочтите ее, чтобы ознакомиться с жаргоном и основами обучения с подкреплением.
Сегодня мы узнаем о Q-learning, классическом алгоритме RL, родившемся в 90-х годах.
А мы научим агента водить такси 🚕🚕🚕!
Ну, упрощенная версия среды такси, но такси в конце концов.
Весь код для этого урока находится в этом репозитории Github. Git клонирует его, чтобы решить сегодняшнюю проблему.

Часть 2
Содержимое
- Проблема вождения такси 🚕
- Окружающая среда, действия, состояния, награды
- Случайный базовый уровень агента 🤖🍷
- Агент Q-обучения 🤖🧠
- Настройка гиперпараметров 🎛️
- Резюме ✨
- Домашнее задание 📚
- Что дальше? ❤️
1. Проблема вождения такси 🚕
Мы научим агента водить такси с помощью Reinforcement Learning.
Вождение такси в реальном мире — очень сложная задача для начала. Из-за этого мы будем работать в упрощенной среде, которая охватывает 3 основные вещи, которые должен делать хороший таксист, а именно:
- забрать пассажиров и высадить их в нужном месте.
- езжайте безопасно, то есть без сбоев.
- водить их в кратчайшие сроки.
Мы будем использовать среду OpenAI Gym, называемую средой Taxi-v3.
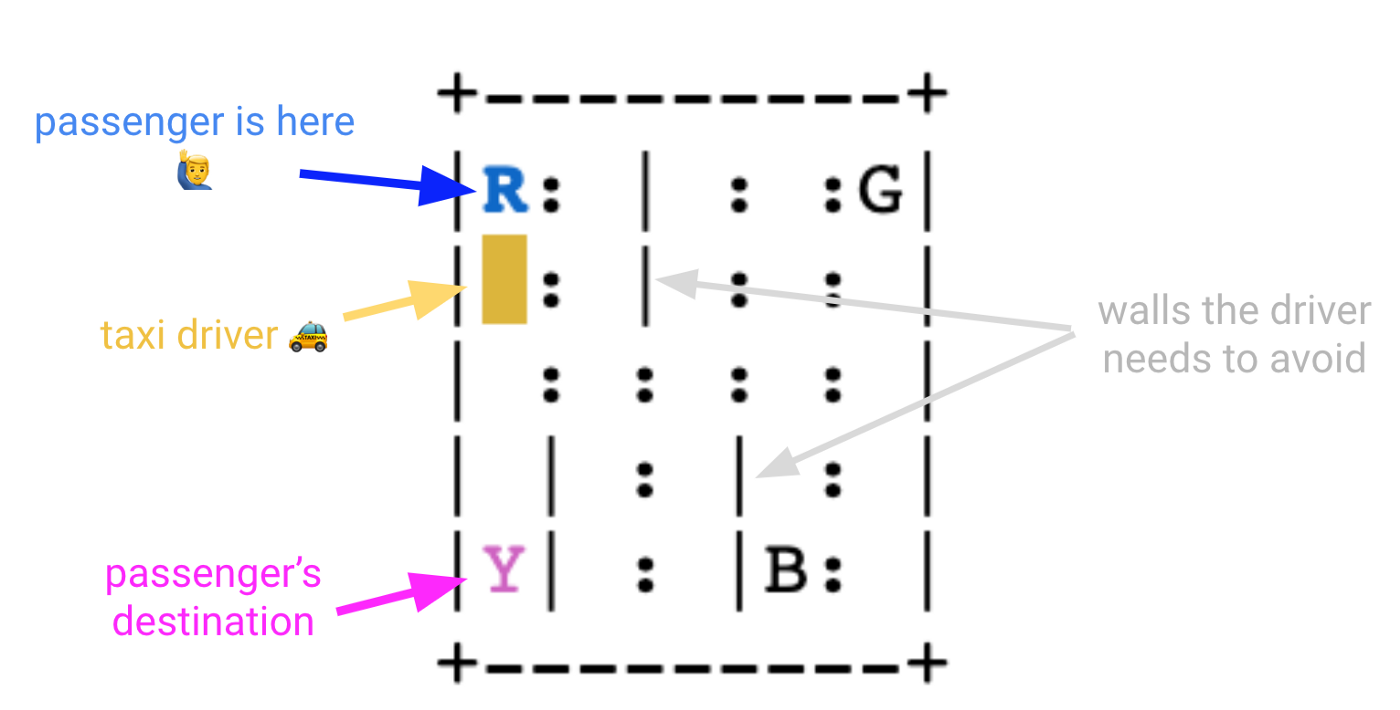
В мире сетки есть четыре обозначенных места, обозначенных буквами R (красный), G (зеленый), Y (желтый) и B (голубой).
Когда эпизод начинается, такси останавливается в случайном квадрате, а пассажир оказывается в случайном месте (R, G, Y или B).
Такси подъезжает к месту нахождения пассажира, забирает пассажира, едет к месту назначения пассажира (еще одно из четырех указанных мест), а затем высаживает пассажира. При этом наш водитель такси должен вести машину осторожно, чтобы не врезаться в стену, отмеченную как |. Как только пассажир высаживается, эпизод заканчивается.
Прежде чем мы доберемся до этого, давайте хорошо разберемся, что такое действия, состояния и награды для этой среды.
2. Окружающая среда, действия, состояния, награды
👉🏽 блокноты/00_environment.ipynb
Давайте сначала загрузим среду:
```питон
импортный тренажерный зал
env = gym.make("Такси-v3").env
Какие действия агент может выбрать на каждом шаге?
- 0 ехать вниз
- 1 подъезд
- 2 диска вправо
- 3 диска осталось
- 4 забрать пассажира
- 5 высадки пассажира
```питон
print("Пространство действий {}".format(env.action_space))
А состояния?
- 25 возможных позиций такси, потому что мир представляет собой сетку 5x5.
- 5 возможных местоположений пассажира: R, G, Y, B, плюс случай, когда пассажир находится в такси.
- 4 пункта назначения
Что дает нам 25 х 5 х 4 = 500 состояний.
```питон
print("Пространство состояний {}".format(env.observation_space))
Как насчет наград?
- -1 награда за шаг по умолчанию. Почему -1, а не просто 0? Потому что мы хотим поощрить агента тратить меньше времени, штрафуя каждый лишний шаг. Это то, что вы ожидаете от таксиста, не так ли?
- Награда +20 за доставку пассажира в нужное место.
- -10 наград за выполнение пикапа или высадки в неправильном месте.
Вы можете прочитать награды и переходы среды (состояние, действие) → next_state из env.P.
```питон
env.P - двойной словарь.
- 1-й ключ представляет состояние, от 0 до 499
- 2-й ключ представляет действие, предпринятое агентом,
от 0 до 5
пример
состояние = 123
action = 0 # двигаться на юг
env.P[state][action][0] — список из 4 элементов
(вероятность, следующее_состояние, награда, выполнено)
- вероятность
В этой среде всегда 1, что означает
нет внешних/случайных факторов, определяющих
следующее_состояние
кроме действия агента a.
- next_state: в данном случае 223
- награда: -1 в данном случае
- сделано: логическое значение (True/False) указывает,
эпизод закончился (т.е. водитель уронил
пассажир в правильном пункте назначения)
print('env.P[состояние][действие][0]: ', env.P[состояние][действие][0])
Кстати, вы можете визуализировать среду в каждом состоянии, чтобы дважды проверить, что векторы env.P имеют смысл:
Из состояние=123
```javascript
Необходимо вызвать reset() хотя бы один раз, прежде чем заработает функция render()
env.reset()
окр.с = 123
env.render (режим = 'человек')
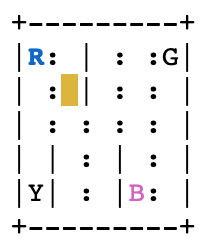
агент перемещается на юг action=0, чтобы добраться до state=223
```javascript
окр.с = 223
env.render (режим = 'человек')
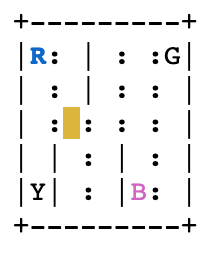
И награда -1, так как ни эпизод не закончился, ни водитель неправильно выбрал или уронил.
3. Случайный базовый уровень агента 🤖🍷
👉🏽 блокноты/01_random_agent_baseline.ipynb
Прежде чем приступить к реализации любого сложного алгоритма, всегда следует создавать базовую модель.
Этот совет относится не только к проблемам обучения с подкреплением, но и к проблемам машинного обучения в целом.
Очень заманчиво сразу перейти к сложным/причудливым алгоритмам, но если вы не очень опытны, вы потерпите ужасную неудачу.
Давайте возьмем случайного агента 🤖🍷 в качестве базовой модели.
```javascript
класс RandomAgent:
Этот таксист выбирает действия случайным образом.
Лучше не садись в это такси!
защита init(я, окружение):
self.env = окружение
def get_action(self, state) -> int:
У нас есть state в качестве входных данных для сохранения
единый API для всех наших агентов, но это
не используется.
т. е. агент не рассматривает состояние
окружающую среду при принятии решения о том, что делать дальше.
Вот почему мы называем это «случайным».
вернуть self.env.action_space.sample()
агент = RandomAgent (окружение)
Мы можем увидеть, как этот агент работает для заданного начального `state=123
```питон
установить начальное состояние окружения
env.reset()
состояние = 123
env.s = состояние
эпохи = 0
штрафы = 0 # неправильный прием или высадка
награда = 0
сохраняем кадры, чтобы потом их отображать
кадры = []
сделано = ложь
пока не сделано:
действие = агент.get_action (состояние)
состояние, награда, выполнено, информация = env.step(action)
если награда == -10:
штрафы += 1
кадры.дополнение({
'кадр': env.render(mode='ansi'),
'состояние': состояние,
'действие': действие,
'награда': награда
эпохи += 1
print("Временные шаги: {}".format(эпохи))
print("Примененные штрафы: {}".format(штрафы))

1420 шагов - это много! 😵
Вы получите разные числа, когда запустите этот код на своем ноутбуке из-за случайности в этом агенте. Но все равно результаты будут неизменно плохими.
Чтобы получить более репрезентативный показатель производительности, мы можем повторить один и тот же цикл оценки n=100 раз, начиная каждый раз со случайного состояния.
```питон
из tqdm импортировать tqdm
n_эпизодов = 100
Для построения метрик
timesteps_per_episode = []
пенальти_за_эпизод = []
для i в tqdm (диапазон (0, n_episodes)):
сбросить среду в случайное состояние
состояние = env.reset()
эпохи, штрафы, награда, = 0, 0, 0
сделано = ложь
пока не сделано:
действие = агент.get_action (состояние)
next_state, награда, готово, информация = env.step(действие)
если награда == -10:
штрафы += 1
состояние = следующее_состояние
эпохи += 1
timesteps_per_episode.append(эпохи)
Пенальти_per_episode.append(пенальти)
Если вы начертите timesteps_per_episode и penalties_per_episode, вы увидите, что ни один из них не уменьшается по мере того, как агент завершает больше эпизодов. Другими словами, агент ничему НЕ УЧИТСЯ.
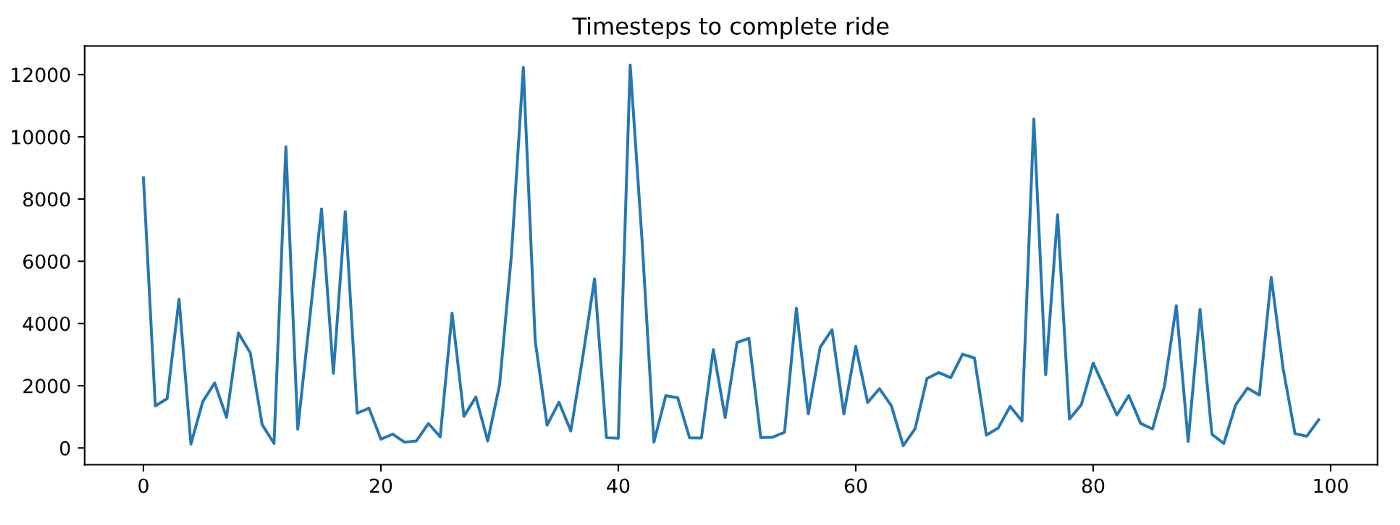
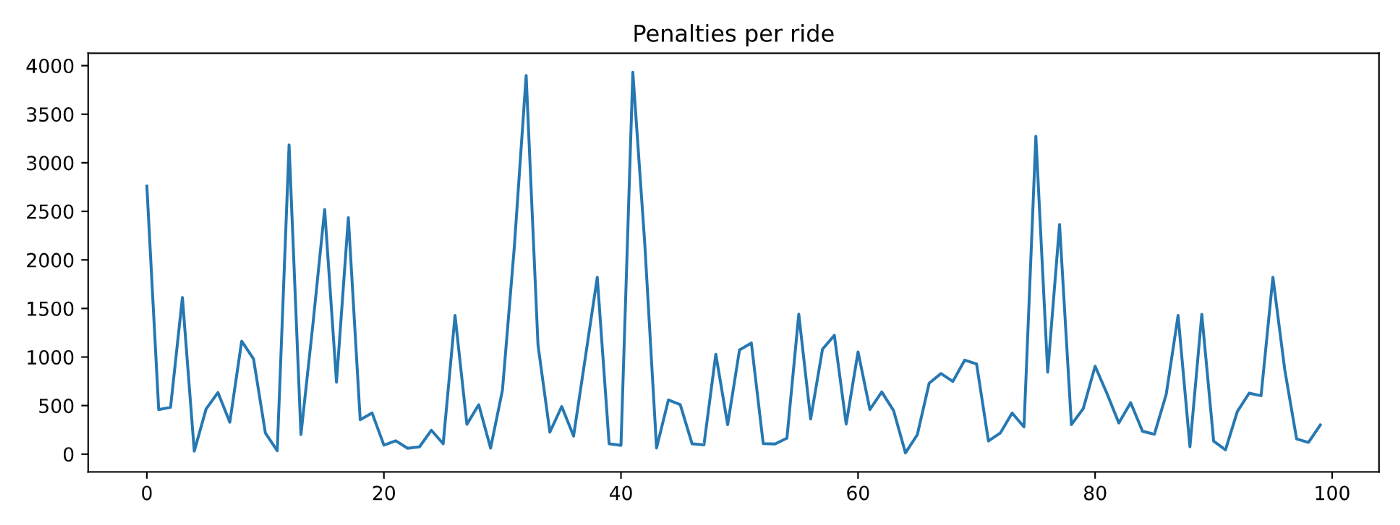
Если вам нужна сводная статистика производительности, вы можете взять средние значения:
```питон
print(f'Среднее количество шагов для завершения поездки: {np.array(timesteps_per_episode).mean()}')
print(f'Средние штрафы за завершение поездки: {np.array(penalties_per_episode).mean()}')

Реализация агентов, которые учатся, является целью обучения с подкреплением, а также этого курса.
Давайте реализуем наш первый «интеллектуальный» агент, используя Q-обучение, один из самых ранних и наиболее часто используемых алгоритмов RL, которые существуют.
4. Агент Q-обучения 🤖🧠
Q-learning (от Chris Walkins 🧠 и Peter Dayan 🧠) представляет собой алгоритм поиска оптимального функция q-значения.
Как мы говорили в часть 1, функция q-значения Q(s, a) связана с политикой \ *π ** – это общее вознаграждение, которое агент ожидает получить, когда в состоянии s агент выполняет действие a и после этого следует политике π* .
Оптимальная функция q-значения **Q*(s, a) ** – это функция q-значения, связанная с оптимальной политикой π*.
Если вы знаете Q*(s, a) , вы можете вывести π*: то есть вы выбираете в качестве следующего действия то, которое максимизирует Q*(s, a) для текущего состояния s.
Q-обучение — это итеративный алгоритм для вычисления все более и более точных приближений к оптимальному
функция q-значения Q*(s, a), начиная с произвольного начального предположения Q⁰(s, a)
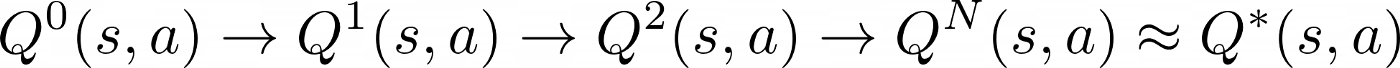
В табличной среде, такой как Taxi-v3, с конечным числом состояний и действий, q-функция по существу является матрицей. В нем столько строк, сколько состояний, и столбцов, сколько действий, то есть 500 x 6.
Хорошо, но как именно вычислить следующее приближение Q¹(s, a) из Q⁰(s, a)?
Это ключевая формула Q-обучения:
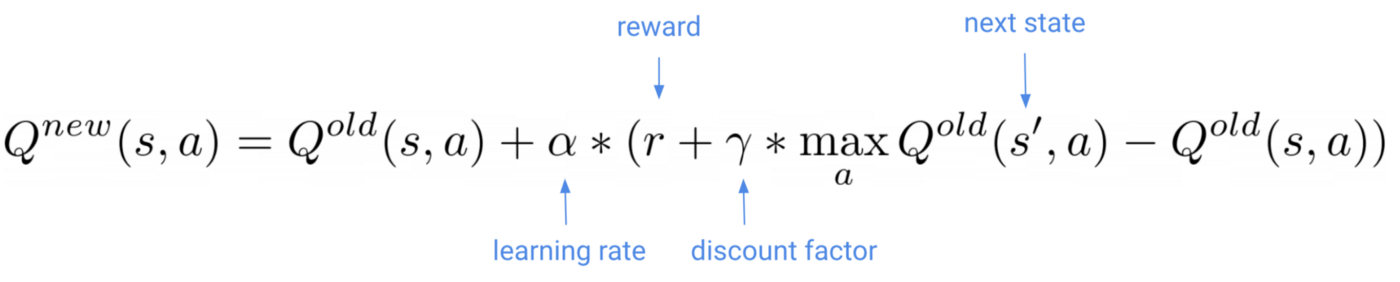
По мере того, как наш q-агент перемещается по среде и наблюдает за следующим состоянием s’ и наградой r, вы обновляете свою матрицу q-значений с помощью этой формулы.
Какова скорость обучения 𝛼 в этой формуле?
Скорость обучения (как обычно в машинном обучении) — это небольшое число, которое определяет, насколько велики обновления q-функции. Вам нужно настроить его, так как слишком большое значение вызовет нестабильное обучение, а слишком маленькое может быть недостаточно, чтобы избежать локальных минимумов.
И этот коэффициент скидки 𝛾?
Коэффициент дисконтирования – это (гипер) параметр от 0 до 1, который определяет, насколько наш агент заботится о вознаграждениях в отдаленном будущем по сравнению с вознаграждениями в ближайшем будущем.
- Когда 𝛾=0, агент заботится только о максимальном немедленном вознаграждении. Как это бывает в жизни, максимизация немедленного вознаграждения — не лучший рецепт для достижения оптимальных долгосрочных результатов. Это происходит и в агентах RL.
- Когда 𝛾=1, агент оценивает каждое свое действие на основе суммы всех своих будущих вознаграждений. В этом случае агент одинаково взвешивает немедленные вознаграждения и будущие вознаграждения.
Коэффициент дисконтирования обычно представляет собой промежуточное значение, т.е. 0,6.
Подводить итоги…
если вы
- тренироваться достаточно долго
- с достойной скоростью обучения и коэффициентом дисконтирования
- и агент достаточно исследует пространство состояний
- и вы обновляете матрицу значений q с помощью формулы Q-обучения
ваше начальное приближение в конечном итоге сойдется к оптимальной q-матрице.
Вуаля!
Давайте тогда реализуем класс Python для Q-агента.
```питон
импортировать numpy как np
класс QАгент:
def init(self, env, alpha, gamma):
self.env = окружение
таблица с q-значениями: n_states * n_actions
self.q_table = np.zeros([env.observation_space.n,
env.action_space.n])
гиперпараметры
self.alpha = альфа # скорость обучения
self.gamma = гамма # коэффициент дисконтирования
def get_action (я, состояние):
вернуть np.argmax (self.q_table [состояние])
def update_parameters (я, состояние, действие, вознаграждение, следующее_состояние):
Формула Q-обучения
old_value = self.q_table[состояние, действие]
next_max = np.max (self.q_table [next_state])
новое_значение = \
старое_значение + \
self.alpha * (награда + self.gamma * next_max - old_value)
обновить q_table
self.q_table[состояние, действие] = новое_значение
Его API такой же, как и для RandomAgent выше, но с дополнительным методом update_parameters(`). Этот метод берет вектор перехода (состояние, действие, вознаграждение, следующее_состояние) и обновляет аппроксимацию матрицы q-значений self.q_table, используя приведенную выше формулу Q-обучения.
Теперь нам нужно подключить этого агента к циклу обучения и вызывать его метод update_parameters() каждый раз, когда агент собирает новый опыт.
Кроме того, помните, что нам нужно гарантировать, что агент исследует достаточно пространства состояний. Помните параметр исследования-эксплуатации, о котором мы говорили в часть 1? В этот момент в игру вступает параметр эпсилон.
Давайте обучим агента для n_episodes = 10 000 и используем epsilon = 10%
```питон
импортировать случайный
из tqdm импортировать tqdm
разведка vs эксплуатация prob
эпсилон = 0,1
n_эпизодов = 10000
Для построения метрик
timesteps_per_episode = []
пенальти_за_эпизод = []
для i в tqdm (диапазон (0, n_episodes)):
состояние = env.reset()
эпохи, штрафы, награда, = 0, 0, 0
сделано = ложь
пока не сделано:
если random.uniform(0, 1) < эпсилон:
Исследуйте пространство действия
действие = env.action_space.sample()
еще:
Использование изученных значений
действие = агент.get_action (состояние)
next_state, награда, готово, информация = env.step(действие)
agent.update_parameters (состояние, действие, вознаграждение, следующее_состояние)
если награда == -10:
штрафы += 1
состояние = следующее_состояние
эпохи += 1
timesteps_per_episode.append(эпохи)
Пенальти_per_episode.append(пенальти)
И постройте timesteps_per_episode и penalties_per_episode
```питон
импортировать панд как pd
импортировать matplotlib.pyplot как plt
рис, топор = plt.subplots (figsize = (12, 4))
ax.set_title("Временные шаги для завершения поездки")
pd.Series(timesteps_per_episode).plot(kind='line')
plt.show()
рис, топор = plt.subplots (figsize = (12, 4))
ax.set_title("Штрафы за поездку")
pd.Series(penalties_per_episode).plot(kind='line')
plt.show()
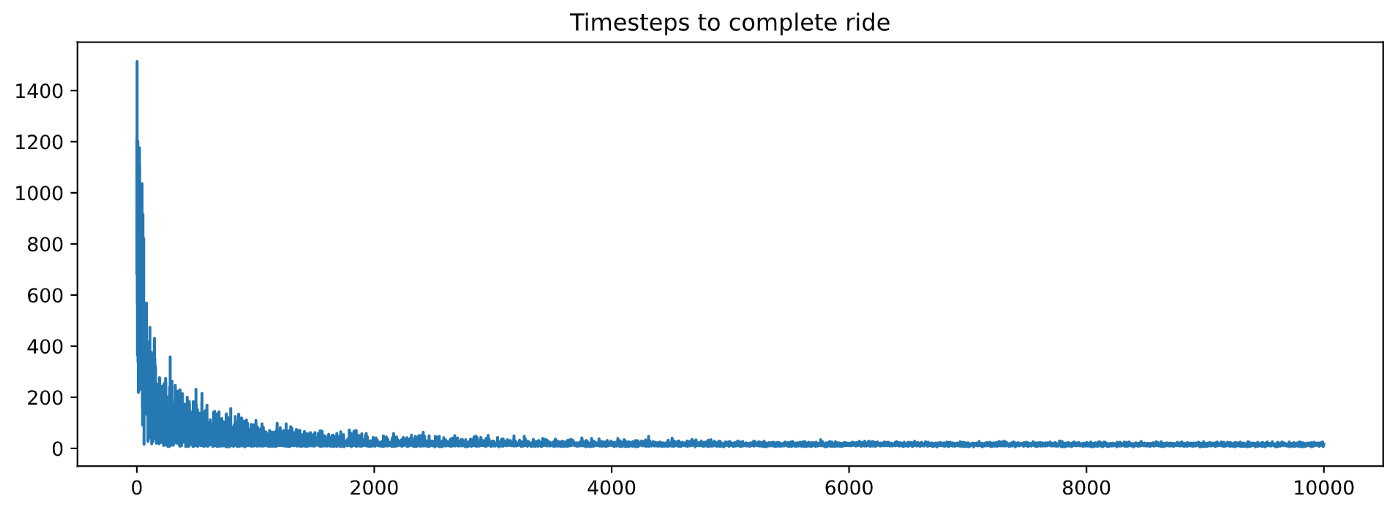
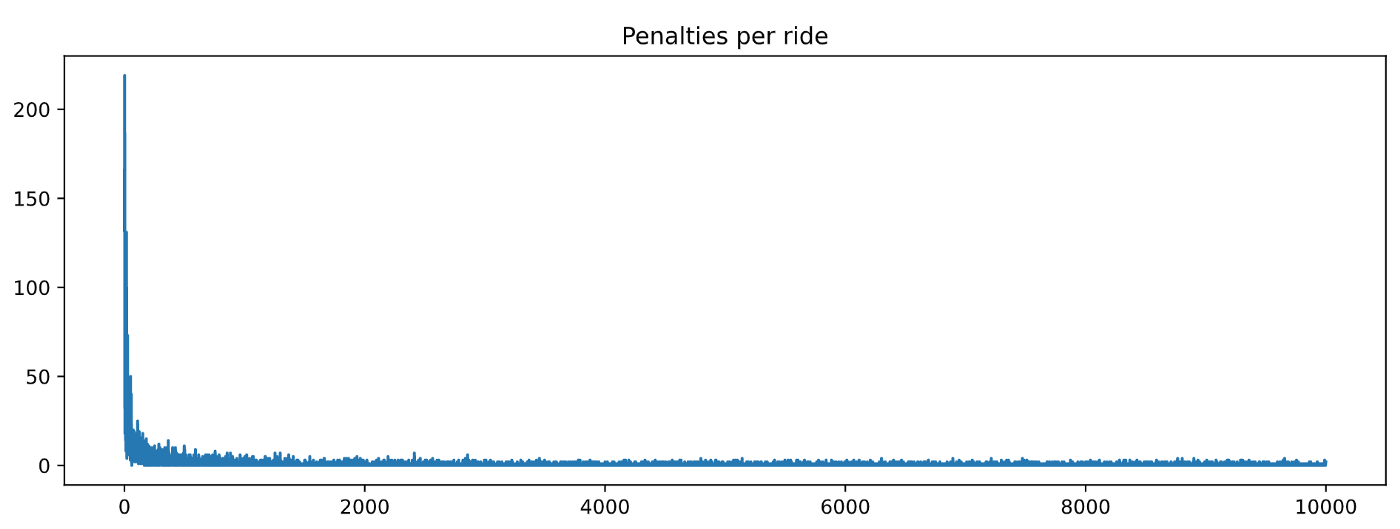
Хороший! Эти графики выглядят намного лучше, чем для RandomAgent. Обе метрики уменьшаются при обучении, а это значит, что наш агент обучается 🎉🎉🎉.
На самом деле мы можем видеть, как агент едет, начиная с того же state = 123, что и для RandomAgent.
```питон
установить начальное состояние окружения
состояние = 123
env.s = состояние
эпохи = 0
штрафы = 0
награда = 0
сохраняем кадры, чтобы потом их отображать
кадры = []
сделано = ложь
пока не сделано:
действие = агент.get_action (состояние)
next_state, награда, готово, информация = env.step(действие)
agent.update_parameters (состояние, действие, вознаграждение, следующее_состояние)
если награда == -10:
штрафы += 1
кадры.дополнение({
'кадр': env.render(mode='ansi'),
'состояние': состояние,
'действие': действие,
'награда': награда
состояние = следующее_состояние
эпохи += 1
print("Временные шаги: {}".format(эпохи))
print("Примененные штрафы: {}".format(штрафы))

Если вы хотите сравнить точные числа, вы можете оценить производительность q-агента, скажем, на 100 случайных эпизодах и вычислить среднее количество временных меток и наложенных штрафов.
Немного об эпсилон-жадных политиках
При оценке агента по-прежнему рекомендуется использовать положительное значение эпсилон, а не эпсилон = 0.
Почему так? Разве наш агент не полностью обучен? Зачем нам сохранять этот источник случайности при выборе следующего действия?*
Причина в том, чтобы предотвратить переоснащение. Даже для такого небольшого состояния, пространство действия в Taxi-v3 (т.е. 500 x 6) вполне вероятно, что во время обучения наш агент не побывал в достаточном количестве определенных состояний.
Следовательно, его производительность в этих состояниях может быть не на 100% оптимальной, в результате чего агент «застревает» в почти бесконечном цикле неоптимальных действий.
Если эпсилон — небольшое положительное число (например, 5%), мы можем помочь агенту избежать этих бесконечных циклов неоптимальных действий.
Используя небольшой эпсилон при оценке, мы применяем так называемую эпсилон-жадную стратегию.
Давайте оценим нашего обученного агента на n_episodes = 100, используя epsilon = 0,05. Обратите внимание, что цикл выглядит почти так же, как цикл поезда выше, но без вызова update_parameters()
```питон
импортировать случайный
из tqdm импортировать tqdm
разведка vs эксплуатация prob
эпсилон = 0,05
n_эпизодов = 100
Для построения метрик
timesteps_per_episode = []
пенальти_за_эпизод = []
для i в tqdm (диапазон (0, n_episodes)):
состояние = env.reset()
эпохи, штрафы, награда, = 0, 0, 0
сделано = ложь
пока не сделано:
если random.uniform(0, 1) < эпсилон:
Исследуйте пространство действия
действие = env.action_space.sample()
еще:
Использование изученных значений
действие = агент.get_action (состояние)
next_state, награда, готово, информация = env.step(действие)
agent.update_parameters (состояние, действие, вознаграждение, следующее_состояние)
если награда == -10:
штрафы += 1
состояние = следующее_состояние
эпохи += 1
timesteps_per_episode.append(эпохи)
Пенальти_per_episode.append(пенальти)
```питон
print(f'Среднее количество шагов для завершения поездки: {np.array(timesteps_per_episode).mean()}')
print(f'Средние штрафы за завершение поездки: {np.array(penalties_per_episode).mean()}')

Эти цифры выглядят намного лучше, чем для RandomAgent.
Можно сказать, наш агент научился водить такси!
Q-обучение дает нам метод вычисления оптимальных q-значений. Но а как насчет гиперпараметров альфа, гамма и эпсилон ?
Я выбрал их для вас довольно произвольно. Но на практике вам нужно будет настроить их для ваших проблем с RL.
Давайте рассмотрим их влияние на обучение, чтобы лучше понять, что происходит.
5. Настройка гиперпараметров 🎛️
👉🏽 блокноты/03_q_agent_hyperparameters_analysis.ipynb
Давайте обучим нашего q-агента, используя разные значения альфа (скорость обучения) и гамма (коэффициент дисконтирования). Что касается «эпсилон», мы сохраняем его на уровне 10%.
Чтобы код оставался чистым, я инкапсулировал определение q-agent внутри src/q_agent.py, а цикл обучения внутри функции train() в src/loops.py
```питон
Не нужно копировать и вставлять тот же QAgent
определение в каждом блокноте, не так ли?
из src.q_agent импортировать QAgent
гиперпараметры
Задачи RL полны этих гиперпараметров.
На данный момент поверьте мне, когда я устанавливаю эти значения.
Позже мы поиграем с ними и посмотрим, как они влияют на обучение.
альфа = [0,01, 0,1, 1]
гамма = [0,1, 0,6, 0,9]
```питон
импортировать панд как pd
из поезда импорта src.loops
разведка vs эксплуатация prob
начнем с постоянной вероятности 10%.
эпсилон = 0,1
n_эпизодов = 1000
результаты = pd.DataFrame()
для альфы в альфах:
для гаммы в гаммах:
print(f'альфа: {альфа}, гамма: {гамма}')
агент = QAgent (окружение, альфа, гамма)
_, сроки, штрафы = поезд(агент,
окружение,
n_эпизодов,
эпсилон)
собираем временные шаги и штрафы для этой пары
гиперпараметров (альфа, гамма)
результаты_ = pd.DataFrame()
results_['временные шаги'] = временные шаги
results_['пенальти'] = пенальти
результаты_['альфа'] = альфа
результаты_['гамма'] = гамма
результаты = pd.concat([результаты, результаты_])
индекс -> серия
результаты = результаты.reset_index(). переименовать (
столбцы={'индекс': 'эпизод'})
добавить столбец с двумя гиперпараметрами
результаты['гиперпараметры'] = [
f'альфа={а}, гамма={г}'
для (a, g) в zip (результаты ['альфа'], результаты ['гамма'])
Давайте построим временные шаги для каждого эпизода для каждой комбинации гиперпараметров.
```питон
импортировать Seaborn как sns
импортировать matplotlib.pyplot как plt
рис = plt.gcf()
fig.set_size_inches(12, 8)
sns.lineplot('эпизод', 'временные шаги',
оттенок='гиперпараметры', данные=результаты)
Графика выглядит вычурно-вычурно, но уж слишком шумно 😵.
Однако вы можете заметить, что когда «альфа = 0,01», обучение происходит медленнее. альфа (скорость обучения) определяет, насколько мы обновляем q-значения на каждой итерации. Слишком маленькое значение означает более медленное обучение.
Давайте отбросим альфа = 0,01 и проведем 10 прогонов обучения для каждой комбинации гиперпараметров. Мы усредняем временные интервалы для каждого номера эпизода от 1 до 1000, используя эти 10 прогонов.
Я создал функцию train_many_runs() в файле src/loops.py, чтобы код блокнота был чище:
```питон
из src.loops импортировать train_many_runs
альфа = [0,1, 1]
гамма = [0,1, 0,6, 0,9]
эпсилон = 0,1
n_эпизодов = 1000
n_runs = 10
результаты = pd.DataFrame()
для альфы в альфах:
для гаммы в гаммах:
print(f'альфа: {альфа}, гамма: {гамма}')
агент = QAgent (окружение, альфа, гамма)
временные интервалы, штрафы = train_many_runs(агент,
окружение,
n_эпизодов,
эпсилон,
n_runs)
собираем временные шаги и штрафы для этой пары
гиперпараметры (альфа, гамма)
результаты_ = pd.DataFrame()
results_['временные шаги'] = временные шаги
results_['пенальти'] = пенальти
результаты_['альфа'] = альфа
результаты_['гамма'] = гамма
результаты = pd.concat([результаты, результаты_])
индекс -> серия
результаты = результаты.reset_index(). переименовать (
столбцы={'индекс': 'эпизод'})
результаты['гиперпараметры'] = [
f'альфа={а}, гамма={г}'
для (a, g) в zip (результаты ['альфа'], результаты ['гамма'])]
Похоже, что значение alpha = 1.0 работает лучше всего, в то время как gamma оказывает меньшее влияние.
Поздравляем! Вы настроили свою первую скорость обучения в этом курсе 🥳
Настройка гиперпараметров может занять много времени и утомительно. Существуют отличные библиотеки для автоматизации ручного процесса, которому мы только что следовали, например Optuna, но мы поиграем с этим позже в ходе курса. А пока наслаждайтесь ускорением тренировок, которое мы только что обнаружили.
Подождите, а что происходит с этим эпсилон = 10% , в котором я сказал вам доверять мне?
Является ли текущее значение 10% лучшим?
Проверим сами.
Мы берем лучшие найденные альфа и гамма, т.е.
альфа = 1.0
gamma = 0,9(мы могли бы взять также0,1или0,6)
И тренируйтесь с разными «эпсилонами = [0,01, 0,1, 0,9]»
```питон
лучшие гиперпараметры на данный момент
альфа = 1,0
гамма = 0,9
эпсилон = [0,01, 0,10, 0,9]
n_runs = 10
n_эпизодов = 200
результаты = pd.DataFrame()
для эпсилон в эпсилонах:
печать (ф'эпсилон: {эпсилон}')
агент = QAgent (окружение, альфа, гамма)
временные интервалы, штрафы = train_many_runs(агент,
окружение,
n_эпизодов,
эпсилон,
n_runs)
собираем временные шаги и штрафы для этой пары
гиперпараметры (альфа, гамма)
результаты_ = pd.DataFrame()
results_['временные шаги'] = временные шаги
results_['пенальти'] = пенальти
результаты_['эпсилон'] = эпсилон
результаты = pd.concat([результаты, результаты_])
индекс -> серия
results = results.reset_index().rename(columns={'index': 'эпизод'})
И постройте получившиеся кривые временных шагов и штрафов:
```javascript
рис = plt.gcf()
fig.set_size_inches(12, 8)
sns.lineplot('эпизод', 'временные шаги', оттенок='эпсилон', данные=результаты)
plt.show()
рис = plt.gcf()
fig.set_size_inches(12, 8)
sns.lineplot('эпизод', 'штрафы', оттенок='эпсилон', данные=результаты)
Как видите, и эпсилон = 0,01, и эпсилон = 0,1 работают одинаково хорошо, поскольку они обеспечивают правильный баланс между разведкой и эксплуатацией.
С другой стороны, эпсилон = 0,9 является слишком большим значением, вызывающим «слишком большую» случайность во время обучения и не позволяющим нашей q-матрице сходиться к оптимальной. Обратите внимание, как производительность стабилизируется примерно на 250 временных шагах в эпизоде.
В общем, наилучшей стратегией выбора гиперпараметра «эпсилон» является прогрессивный эпсилон-распад. То есть в начале обучения, когда агент очень не уверен в своей оценке q-значения, лучше всего посетить как можно больше состояний, и для этого отлично подходит большой эпсилон (например, 50%).
По мере обучения, когда агент уточняет свою оценку q-значения, исследовать так много уже не оптимально. Вместо этого, уменьшая эпсилон, агент может научиться совершенствовать и точно настраивать значения q, чтобы они быстрее сходились к оптимальным. Слишком большой эпсилон может вызвать проблемы со сходимостью, как мы видим для эпсилон = 0,9.
Мы будем настраивать эпсилоны по ходу, так что пока я не буду слишком настаивать. Еще раз наслаждайтесь тем, что мы сделали сегодня. Это довольно примечательно.

6. Резюме ✨
Поздравляем (вероятно) с решением вашей первой задачи по обучению с подкреплением.
Вот ключевые выводы, на которых я хочу, чтобы вы уснули:
- Сложность задачи обучения с подкреплением напрямую связана с количеством возможных действий и состояний. Taxi-v3 представляет собой табличную среду (т. е. конечное число состояний и действий), поэтому она проста.
- Q-обучение — это алгоритм обучения, который отлично работает в табличных средах.
- Независимо от того, какой алгоритм RL вы используете, есть гиперпараметры, которые необходимо настроить, чтобы ваш агент изучил оптимальную стратегию.
- Настройка гиперпараметров — трудоемкий процесс, но необходимый для обучения наших агентов. Мы будем совершенствоваться в этом по ходу курса.
7. Домашнее задание 📚
Вот что я хочу, чтобы вы сделали:
- Git clone репо на локальный компьютер.
- Настройка среда для этого урока
01_taxi.
- Откройте
01_taxi/otebooks/04_homework.ipynbи попробуйте выполнить 2 задания.
Я называю их вызовами (а не упражнениями), потому что они непростые. Я хочу, чтобы вы попробовали их, испачкали руки и (возможно) преуспели.
В первом задании я предлагаю вам обновить функцию train()src/loops.py, чтобы она принимала эпсилон, зависящий от эпизода.
Во втором задании я хочу, чтобы вы улучшили свои навыки работы с Python и реализовали параллельную обработку, чтобы ускорить эксперименты с гиперпараметрами.
Как обычно, если вы застряли и вам нужна обратная связь, напишите мне по адресу plabartabajo@gmail.com.
Я буду более чем счастлив помочь вам.
8. Что дальше? ❤️
В следующей части мы собираемся решить новую задачу RL.
Более тяжелый.
Использование нового алгоритма RL.
С большим количеством Python.
И будут новые вызовы.
И веселье!
До скорого!
Хотите стать профессионалом в области машинного обучения и получить доступ к лучшим курсам по машинному обучению и науке о данных?
Хорошего дня 🧡❤️💙
Пау