

Обработка данных в реальном времени: простая обработка 10 миллионов сообщений с помощью Golang, Kafka и MongoDB
13 июня 2023 г.Используя Kafka в течение нескольких лет, я приобрел опыт работы с ее моделью тем/подписчиков. Это распределенная платформа потоковой передачи событий с открытым исходным кодом, известная своей высокой пропускной способностью, отказоустойчивостью и масштабируемостью.
Он предназначен для эффективной и надежной обработки больших объемов данных в режиме реального времени, что делает его популярным выбором для создания надежных конвейеров данных и потоковых приложений.
MongoDB — отличное дополнение к Kafka для обработка данных в режиме реального времени. Его гибкая модель документа легко обрабатывает различные форматы данных, а его масштабируемость обеспечивает высокую скорость приема данных.
Функции MongoDB индексирования, запросов и набора реплик обеспечивают эффективный доступ и отказоустойчивость. Интеграция MongoDB с Kafka позволяет организациям создавать масштабируемые конвейеры данных в режиме реального времени для современных приложений.
В этой статье мы увидим пример обработки данных в реальном времени с помощью Go.
Предлагаемое приложение
Предположим, что каждая транзакция публикуется в теме Kafka. Каждая транзакция на сумму более 10 000 считается подозрительной, и мы хотим сохранить ее в MongoDB для дальнейшего анализа. Сообщение, публикуемое в теме, выглядит следующим образом: JSON:
{
"transaction_id": 4508561159,
"account_number": 395402066,
"transaction_type": "withdrawal",
"transaction_amount": 2718.79,
"transaction_time": "2023-06-11T16:34:46.150535-03:00",
"location": "Jacksonville, FL"
}
Вот общая архитектура: n 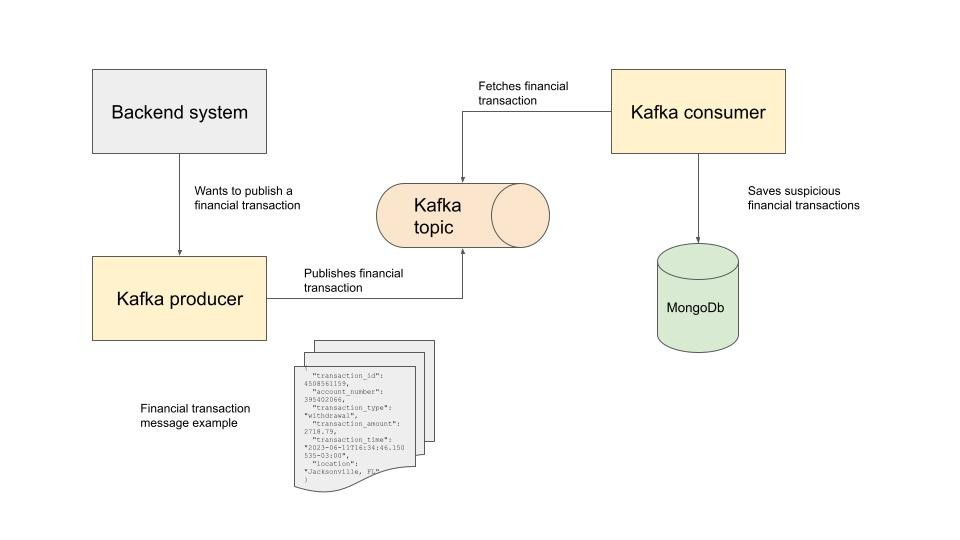 Коротко о горутинах Golang
Коротко о горутинах Golang
Если вы знакомы с Go, до этого момента вы, возможно, думали об использовании горутины для обработки сообщений одновременно. И вы правильно догадались: мы их используем.
Вот абстракция рабочего пула, которую мы будем использовать для нескольких разных задач в системе:
task/task.go
// Copyright (c) 2023 Tiago Melo. All rights reserved.
// Use of this source code is governed by the MIT License that can be found in
// the LICENSE file.
package task
import (
"context"
"sync"
)
// Worker must be implemented by types that want to use
// the run pool.
type Worker interface {
Work(ctx context.Context)
}
// Task provides a pool of goroutines that can execute any Worker
// tasks that are submitted.
type Task struct {
ctx context.Context
work chan Worker
wg sync.WaitGroup
}
// New creates a new work pool.
func New(ctx context.Context, maxGoroutines int) *Task {
t := Task{
// Using an unbuffered channel because we want the
// guarantee of knowing the work being submitted is
// actually being worked on after the call to Run returns.
work: make(chan Worker),
ctx: ctx,
}
// The goroutines are the pool. So we could add code
// to change the size of the pool later on.
t.wg.Add(maxGoroutines)
for i := 0; i < maxGoroutines; i++ {
go func() {
for w := range t.work {
w.Work(ctx)
}
t.wg.Done()
}()
}
return &t
}
// Shutdown waits for all the goroutines to shutdown.
func (t *Task) Shutdown() {
close(t.work)
t.wg.Wait()
}
// Do submits work to the pool.
func (t *Task) Do(w Worker) {
t.work <- w
}
n Структура Task представляет собой пул go-процедур, которые могут выполнять задачи, отправленные путем реализации интерфейса Worker. Интерфейс Worker определяет одну функцию Work(ctx context.Context), которая представляет работу, которую должна выполнить каждая задача.
Функция New инициализирует новый пул рабочих процессов, создавая экземпляр Task. Он принимает максимальное количество горутин в качестве параметра и устанавливает канал (work) для получения и распределения задач.
Канал не буферизован, чтобы обеспечить активную обработку работы после возврата вызова Run. Указанное значение maxGoroutines определяет количество горутин в пуле.
Каждая горутина прослушивает канал work, выполняет полученные задачи, вызывая свою функцию Work, и завершает работу, когда канал закрывается.
Функция Shutdown изящно завершает работу пула рабочих процессов, закрывая канал work и ожидая, пока все горутины завершат свои задачи с помощью sync.WaitGroup. .
Функция Do используется для отправки задач в рабочий пул. Он добавляет заданный рабочий процесс (w) в канал work, позволяя горутине из пула подобрать его и обработать задачу асинхронно.
В целом, эта абстракция пула рабочих процессов обеспечивает способ управления фиксированным пулом горутин, которые могут эффективно выполнять различные задачи одновременно, повышая общую производительность и использование ресурсов.
Продюсер Кафки
Он принимает текстовый файл, содержащий финансовую транзакцию json в каждой строке. Цель состоит в том, чтобы заставить производителя читать данный файл, строка за строкой, и публиковать каждую строку в теме Kafka.
producer/producer.go
// Copyright (c) 2023 Tiago Melo. All rights reserved.
// Use of this source code is governed by the MIT License that can be found in
// the LICENSE file.
package main
import (
"bufio"
"fmt"
"log"
"os"
"os/signal"
"syscall"
"time"
"github.com/confluentinc/confluent-kafka-go/kafka"
"github.com/jessevdk/go-flags"
"github.com/pkg/errors"
"github.com/tiagomelo/realtime-data-kafka/config"
"github.com/tiagomelo/realtime-data-kafka/screen"
"github.com/tiagomelo/realtime-data-kafka/stats"
)
const bootstrapServersKey = "bootstrap.servers"
func stringPrt(s string) *string {
return &s
}
func run(log *log.Logger, cfg *config.Config, transactionsFile string) error {
log.Println("main: Initializing Kafka producer")
defer log.Println("main: Completed")
producer, err := kafka.NewProducer(&kafka.ConfigMap{
bootstrapServersKey: cfg.KafkaBrokerHost,
})
if err != nil {
return errors.Wrap(err, "creating producer")
}
defer producer.Close()
file, err := os.Open(transactionsFile)
if err != nil {
return errors.Wrapf(err, "opening file %s", transactionsFile)
}
defer file.Close()
// Make a channel to listen for an interrupt or terminate signal from the OS.
// Use a buffered channel because the signal package requires it.
shutdown := make(chan os.Signal, 1)
signal.Notify(shutdown, os.Interrupt, syscall.SIGTERM)
// Make a channel to listen for errors coming from the listener. Use a
// buffered channel so the goroutine can exit if we don't collect this error.
serverErrors := make(chan error, 1)
stats := &stats.KafkaProducerStats{}
screen, err := screen.NewKafkaProducerScreen(stats)
if err != nil {
return errors.New("starting screen")
}
start := time.Now()
go func() {
for {
time.Sleep(time.Second * time.Duration(1))
stats.UpdateElapsedTime(time.Since(start))
screen.UpdateContent(false)
}
}()
deliveryChan := make(chan kafka.Event)
scanner := bufio.NewScanner(file)
go func() {
for scanner.Scan() {
line := scanner.Text()
if err := producer.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: stringPrt(cfg.KafkaTopic), Partition: kafka.PartitionAny},
Value: []byte(line),
}, deliveryChan); err != nil {
log.Printf("%v when publishing to kafka topic %s", err, cfg.KafkaTopic)
}
stats.IncrTotalPublishedMessages()
delivery := <-deliveryChan
m := delivery.(*kafka.Message)
if m.TopicPartition.Error != nil {
stats.IncrTotalFailedMessageDeliveries()
}
}
if err := scanner.Err(); err != nil {
errors.Wrapf(err, "reading file %s", transactionsFile)
}
}()
// Wait for any error or interrupt signal.
select {
case err := <-serverErrors:
return err
case sig := <-shutdown:
screen.UpdateContent(true)
log.Printf("run: %v: Start shutdown", sig)
return nil
}
}
var opts struct {
File string `short:"f" long:"file" description:"input file" required:"true"`
}
func main() {
const (
envFile = ".env"
logFileName = "logs/producer.txt"
)
flags.ParseArgs(&opts, os.Args)
logFile, err := os.OpenFile(logFileName, os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
if err != nil {
fmt.Printf(`opening log file "%s": %v`, logFileName, err)
}
log := log.New(logFile, "KAFKA PRODUCER : ", log.LstdFlags|log.Lmicroseconds|log.Lshortfile)
cfg, err := config.Read(envFile)
if err != nil {
log.Println(errors.Wrap(err, "reading config"))
fmt.Println(errors.Wrap(err, "reading config"))
os.Exit(1)
}
if err := run(log, cfg, opts.File); err != nil {
log.Println(err)
fmt.Println(err)
os.Exit(1)
}
}
Основные выводы:
* В качестве клиент Kafka.
* У нас есть канал доставки, где мы можем проверить, было ли сообщение опубликовано или нет.
* github.com/pterm/pterm используется для украшения вывода консоли. Не забудьте проверить screen/screen.go, чтобы узнать, что он делает.
Потребитель Кафки
consumer/consumer.go
// Copyright (c) 2023 Tiago Melo. All rights reserved.
// Use of this source code is governed by the MIT License that can be found in
// the LICENSE file.
package main
import (
"context"
"fmt"
"log"
"os"
"os/signal"
"runtime"
"syscall"
"time"
"github.com/confluentinc/confluent-kafka-go/kafka"
"github.com/pkg/errors"
"github.com/tiagomelo/realtime-data-kafka/config"
"github.com/tiagomelo/realtime-data-kafka/mongodb"
"github.com/tiagomelo/realtime-data-kafka/screen"
"github.com/tiagomelo/realtime-data-kafka/stats"
"github.com/tiagomelo/realtime-data-kafka/task"
kafkaWorker "github.com/tiagomelo/realtime-data-kafka/task/worker/kafka"
)
// Useful constants.
const (
bootstrapServersKey = "bootstrap.servers"
groupIdKey = "group.id"
autoOffsetResetKey = "auto.offset.reset"
autoOffsetReset = "earliest"
enablePartitionEofKey = "enable.partition.eof"
)
func run(log *log.Logger) error {
const envFile = ".env"
log.Println("main: Initializing Kafka consumer")
defer log.Println("main: Completed")
ctx := context.Background()
cfg, err := config.Read(envFile)
if err != nil {
return errors.Wrap(err, "reading config")
}
consumer, err := kafka.NewConsumer(&kafka.ConfigMap{
bootstrapServersKey: cfg.KafkaBrokerHost,
groupIdKey: cfg.KafkaGroupId,
autoOffsetResetKey: autoOffsetReset,
enablePartitionEofKey: false,
})
if err != nil {
return errors.Wrapf(err, "connecting to broker %s", cfg.KafkaBrokerHost)
}
if err := consumer.SubscribeTopics([]string{cfg.KafkaTopic}, nil); err != nil {
return errors.Wrapf(err, "subscribing to topic %s", cfg.KafkaTopic)
}
db, err := mongodb.Connect(ctx, cfg.MongodbHostName, cfg.MongodbDatabase, cfg.MongodbPort)
if err != nil {
return errors.Wrapf(err, "connecting to mongodb")
}
// Make a channel to listen for an interrupt or terminate signal from the OS.
// Use a buffered channel because the signal package requires it.
shutdown := make(chan os.Signal, 1)
signal.Notify(shutdown, os.Interrupt, syscall.SIGTERM)
// Make a channel to listen for errors coming from the listener. Use a
// buffered channel so the goroutine can exit if we don't collect this error.
serverErrors := make(chan error, 1)
maxGoRoutines := runtime.GOMAXPROCS(0)
pool := task.New(ctx, maxGoRoutines)
stats := &stats.KafkaConsumerStats{}
screen, err := screen.NewKafkaConsumerScreen(stats)
if err != nil {
return errors.New("starting screen")
}
start := time.Now()
go func() {
defer close(shutdown)
defer close(serverErrors)
for {
select {
case <-shutdown:
log.Printf("run: Start shutdown")
if err := consumer.Close(); err != nil {
serverErrors <- errors.Wrap(err, "closing Kafka consumer")
}
return
default:
msg, err := consumer.ReadMessage(-1)
if err != nil {
serverErrors <- err
} else {
kw := &kafkaWorker.Worker{Msg: msg, Stats: stats, Db: db, Log: log}
pool.Do(kw)
}
}
}
}()
go func() {
for {
time.Sleep(time.Second * time.Duration(1))
stats.UpdateElapsedTime(time.Since(start))
screen.UpdateContent(false)
}
}()
// Wait for any error or interrupt signal.
select {
case err := <-serverErrors:
return err
case sig := <-shutdown:
screen.UpdateContent(true)
log.Printf("run: %v: Start shutdown", sig)
// Asking listener to shutdown and shed load.
if err := consumer.Close(); err != nil {
return errors.Wrap(err, "closing Kafka consumer")
}
return nil
}
}
func main() {
const logFileName = "logs/consumer.txt"
logFile, err := os.OpenFile(logFileName, os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
if err != nil {
fmt.Printf(`opening log file "%s": %v`, logFileName, err)
}
log := log.New(logFile, "KAFKA CONSUMER : ", log.LstdFlags|log.Lmicroseconds|log.Lshortfile)
if err := run(log); err != nil {
fmt.Println(err)
os.Exit(1)
}
}
Основные выводы:
* Мы используем рабочий пул для обработки сообщений.
* github.com/pterm/pterm также используется для украшения вывода консоли.
Для обработки данных финансовых транзакций у нас есть transaction/transaction.go:
// Copyright (c) 2023 Tiago Melo. All rights reserved.
// Use of this source code is governed by the MIT License that can be found in
// the LICENSE file.
package transaction
import (
"encoding/json"
"time"
"github.com/pkg/errors"
)
// Transaction represents a transaction message.
type Transaction struct {
TransactionID int `json:"transaction_id"`
AccountNumber int `json:"account_number"`
TransactionType string `json:"transaction_type"`
TransactionAmount float32 `json:"transaction_amount"`
TransactionTime time.Time `json:"transaction_time"`
Location string `json:"location"`
}
// New creates a new Transaction from the raw JSON transaction data.
func New(rawTransaction string) (*Transaction, error) {
t := new(Transaction)
if err := json.Unmarshal([]byte(rawTransaction), &t); err != nil {
return nil, errors.Wrap(err, "unmarshalling transaction")
}
return t, nil
}
// IsSuspicious checks if the transaction amount is suspicious.
func (t *Transaction) IsSuspicious() bool {
const suspiciousAmount = float32(10_000)
return t.TransactionAmount > suspiciousAmount
}
А вот рабочий процесс, который мы используем для обработки полученных данных о финансовых транзакциях:
task/worker/kafka/kafka.go
// Copyright (c) 2023 Tiago Melo. All rights reserved.
// Use of this source code is governed by the MIT License that can be found in
// the LICENSE file.
package kafka
import (
"context"
"fmt"
"log"
"github.com/confluentinc/confluent-kafka-go/kafka"
"github.com/tiagomelo/realtime-data-kafka/mongodb"
"github.com/tiagomelo/realtime-data-kafka/mongodb/suspicioustransaction"
"github.com/tiagomelo/realtime-data-kafka/mongodb/suspicioustransaction/models"
"github.com/tiagomelo/realtime-data-kafka/stats"
"github.com/tiagomelo/realtime-data-kafka/transaction"
)
// For ease of unit testing.
var (
printToLog = func(log *log.Logger, v ...any) {
log.Println(v...)
}
stInsert = func(ctx context.Context, db *mongodb.MongoDb, sp *models.SuspiciousTransaction) error {
return suspicioustransaction.Insert(ctx, db, sp)
}
)
// Worker represents a Kafka consumer worker.
type Worker struct {
Msg *kafka.Message
Stats *stats.KafkaConsumerStats
Db *mongodb.MongoDb
Log *log.Logger
}
// insertSuspiciousTransaction inserts a suspicious transaction into MongoDB.
func (c *Worker) insertSuspiciousTransaction(ctx context.Context, sp *transaction.Transaction) error {
spDb := &models.SuspiciousTransaction{
TransactionId: sp.TransactionID,
AccountNumber: sp.AccountNumber,
TransactionType: sp.TransactionType,
TransactionAmount: sp.TransactionAmount,
TransactionTime: sp.TransactionTime,
Location: sp.Location,
}
return stInsert(ctx, c.Db, spDb)
}
// Work processes the Kafka message and performs the necessary operations.
func (c *Worker) Work(ctx context.Context) {
c.Stats.IncrTotalTransactions()
transaction, err := transaction.New(string(c.Msg.Value))
if err != nil {
c.Stats.IncrTotalUnmarshallingMsgErrors()
printToLog(c.Log, fmt.Errorf("checking if transaction is suspicious: %v", err))
return
}
if transaction.IsSuspicious() {
c.Stats.IncrTotalSuspiciousTransactions()
printToLog(c.Log, "suspicious transaction: %+vn", transaction)
if err := c.insertSuspiciousTransaction(ctx, transaction); err != nil {
c.Stats.IncrTotalInsertSuspiciousTransactionErrors()
printToLog(c.Log, "error when inserting suspicious transaction in mongodb %+v: %vn", transaction, err)
}
}
}
Ошибки просто регистрируются, так как мы не хотим, чтобы наш рабочий процесс останавливался в этом случае. Кроме того, данные финансовых транзакций сохраняются в MongoDB, если они вызывают подозрения. Убедитесь, что вы проверили папку Mongodb, чтобы понять это.
Создание образцов финансовых транзакций
Вот генератор случайных данных:
randomdata/random_data.go
// Copyright (c) 2023 Tiago Melo. All rights reserved.
// Use of this source code is governed by the MIT License that can be found in
// the LICENSE file.
package randomdata
import (
"fmt"
"math/rand"
"strconv"
"time"
)
// locations is a slice of pre-defined locations for generating random transaction locations.
var locations = []string{
"New York, NY",
"Los Angeles, CA",
"Chicago, IL",
"Houston, TX",
"Phoenix, AZ",
"Philadelphia, PA",
"San Antonio, TX",
"San Diego, CA",
"Dallas, TX",
"San Jose, CA",
"Austin, TX",
"Jacksonville, FL",
"Fort Worth, TX",
"Columbus, OH",
"Charlotte, NC",
"San Francisco, CA",
"Indianapolis, IN",
"Seattle, WA",
"Denver, CO",
"Washington, DC",
}
// TransactionID generates a random transaction ID.
func TransactionID() int {
seed := time.Now().UnixNano()
r := rand.New(rand.NewSource(seed))
r.Seed(time.Now().UnixNano())
return r.Intn(9999999999-1111111111+1) + 1111111111
}
// AccountNumber generates a random account number.
func AccountNumber() int {
seed := time.Now().UnixNano()
r := rand.New(rand.NewSource(seed))
r.Seed(time.Now().UnixNano())
return r.Intn(999999999-111111111+1) + 111111111
}
// TransactionAmount generates a random transaction amount between the specified minimum and maximum amounts.
func TransactionAmount(minAmount, maxAmount float32) float32 {
seed := time.Now().UnixNano()
r := rand.New(rand.NewSource(seed))
randomAmount := r.Float32()*(maxAmount-minAmount) + minAmount
formattedAmount, _ := strconv.ParseFloat(fmt.Sprintf("%.2f", randomAmount), 32)
return float32(formattedAmount)
}
// TransactionTime generates a random transaction time within the last 24 hours.
func TransactionTime() time.Time {
seed := time.Now().UnixNano()
r := rand.New(rand.NewSource(seed))
randomDuration := time.Duration(r.Intn(86400)) * time.Second
randomTime := time.Now().Add(-randomDuration)
return randomTime
}
// Location generates a random transaction location from the pre-defined locations.
func Location() string {
seed := time.Now().UnixNano()
r := rand.New(rand.NewSource(seed))
return locations[r.Intn(len(locations))]
}
Теперь предположим, что мы хотим сгенерировать файл с 1000 строками. У нас есть воркер для ускорения:
task/worker/randomtransaction/randomtransaction.go
// Copyright (c) 2023 Tiago Melo. All rights reserved.
// Use of this source code is governed by the MIT License that can be found in
// the LICENSE file.
package randomtransaction
import (
"context"
"encoding/json"
"log"
"os"
"github.com/tiagomelo/realtime-data-kafka/randomdata"
"github.com/tiagomelo/realtime-data-kafka/transaction"
)
// For ease of unit testing.
var (
openFile = os.OpenFile
jsonMarshal = json.Marshal
fileWriteString = func(file *os.File, s string) (n int, err error) {
return file.WriteString(s)
}
printToLog = func(log *log.Logger, v ...any) {
log.Println(v...)
}
)
// Worker generates random transaction data.
type Worker struct {
FilePath string
MinAmount float32
MaxAmount float32
Log *log.Logger
}
// Work generates a random transaction and writes it to a file.
func (w *Worker) Work(ctx context.Context) {
t := generateRandomTransaction(w.MinAmount, w.MaxAmount)
file, err := openFile(w.FilePath, os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
if err != nil {
printToLog(w.Log, "error opening file:", err)
return
}
defer file.Close()
jsonData, err := jsonMarshal(t)
if err != nil {
printToLog(w.Log, "error marshalling json:", err)
return
}
_, err = fileWriteString(file, string(jsonData)+"n")
if err != nil {
printToLog(w.Log, "error writing to file:", err)
}
}
// generateRandomTransaction generates a random transaction with the given minimum and maximum amounts.
func generateRandomTransaction(minAmount, maxAmount float32) *transaction.Transaction {
const withdrawal = "withdrawal"
t := &transaction.Transaction{
TransactionID: randomdata.TransactionID(),
AccountNumber: randomdata.AccountNumber(),
TransactionType: withdrawal,
TransactionAmount: randomdata.TransactionAmount(minAmount, maxAmount),
TransactionTime: randomdata.TransactionTime(),
Location: randomdata.Location(),
}
return t
}
А вот CLI, который нам нужен, чтобы сгенерировать файл:
jsongenerator/jsongenerator.go
// Copyright (c) 2023 Tiago Melo. All rights reserved.
// Use of this source code is governed by the MIT License that can be found in
// the LICENSE file.
package main
import (
"context"
"math/rand"
"os"
"runtime"
"github.com/jessevdk/go-flags"
"github.com/tiagomelo/realtime-data-kafka/task"
"github.com/tiagomelo/realtime-data-kafka/task/worker/randomtransaction"
)
// opts holds the command-line options.
var opts struct {
LowerLimitMinValue float32 `long:"llmin" description:"Lower limit min value" required:"true"`
LowerLimitMaxValue float32 `long:"llmax" description:"Lower limit max value" required:"true"`
UpperLimitMinValue float32 `long:"ulmin" description:"Upper limit min value" required:"true"`
UpperLimitMaxValue float32 `long:"ulmax" description:"Upper limit max value" required:"true"`
Percentage float32 `short:"p" long:"percentage" description:"Percentage for lower limit" required:"true"`
TotalLines int `short:"t" long:"totallines" description:"Total lines" required:"true"`
File string `short:"f" long:"file" description:"Output file" required:"true"`
}
func run(args []string) error {
flags.ParseArgs(&opts, args)
ctx := context.Background()
maxGoRoutines := runtime.GOMAXPROCS(0)
pool := task.New(ctx, maxGoRoutines)
lowerLimit := float32(opts.TotalLines) * opts.Percentage
remaining := float32(opts.TotalLines) - lowerLimit
workers := make([]task.Worker, opts.TotalLines)
for i := 0; i < int(lowerLimit); i++ {
workers[i] = &randomtransaction.Worker{FilePath: opts.File, MinAmount: opts.LowerLimitMinValue, MaxAmount: opts.LowerLimitMaxValue}
}
for i := int(remaining); i < opts.TotalLines; i++ {
workers[i] = &randomtransaction.Worker{FilePath: opts.File, MinAmount: opts.UpperLimitMinValue, MaxAmount: opts.UpperLimitMaxValue}
}
rand.Shuffle(len(workers), func(i, j int) { workers[i], workers[j] = workers[j], workers[i] })
for _, w := range workers {
pool.Do(w)
}
pool.Shutdown()
return nil
}
func main() {
run(os.Args)
}
Стоит отметить, что я использую github.com/jessevdk/go-flags вместо ядра < пакет href="https://pkg.go.dev/flag">flag. Это упрощает анализ всех предоставленных флагов в структуру, а также предлагает гораздо больше дополнительных функций.
Кроме того, как вы, возможно, заметили, логика здесь заключается в том, чтобы иметь возможность определить заданный процент от общего числа строк для определенной суммы транзакции.
Вот цель в нашем Makefile для создания файла:
# ==============================================================================
# Sample data generation
.PHONY: sample-data
## sample-data: generates sample data
sample-data:
@ if [ -z "$(TOTAL)" ]; then echo >&2 please set total via the variable TOTAL; exit 2; fi
@ if [ -z "$(FILE_NAME)" ]; then echo >&2 please set file name via the variable FILE_NAME; exit 2; fi
@ rm -f "${SAMPLE_DATA_FOLDER}/${FILE_NAME}"
@ echo "generating file ${SAMPLE_DATA_FOLDER}/${FILE_NAME}..."
@ go run jsongenerator/jsongenerator.go --llmin 10000 --llmax 30000 --ulmin 100 --ulmax 3000 -t=$(TOTAL) -p=0.7 -f="${SAMPLE_DATA_FOLDER}/${FILE_NAME}"
@ echo "file ${SAMPLE_DATA_FOLDER}/${FILE_NAME} was generated."
Флаги:
* llmin: минимальное значение нижнего предела
* llmax: максимальное значение нижнего предела
* ulmin: минимальное значение верхнего предела
* ulmax: максимальное значение верхнего предела
* t: общее количество строк
* p: желаемый процент
* f: выходной файл
Давайте вызовем его:
$ make sample-data TOTAL=1000 FILE_NAME=onethousand.txt
generating file sampledata/onethousand.txt..file
sampledata/onethousand.txt was generated..
Затем файл сохраняется в папке `sampledata`.
Запускаем все
Чтобы запустить сервер Kafka, нам нужно запустить ZooKeeper в первую очередь, так как Kafka зависит от него для распределенной координации и управления конфигурацией.
Откройте вкладку терминала и запустите ZooKeeper:
$ make zookeeper
n Затем на другой вкладке запустите сервер Kafka:
$ make kafka
На другой вкладке запустите производителя Kafka:
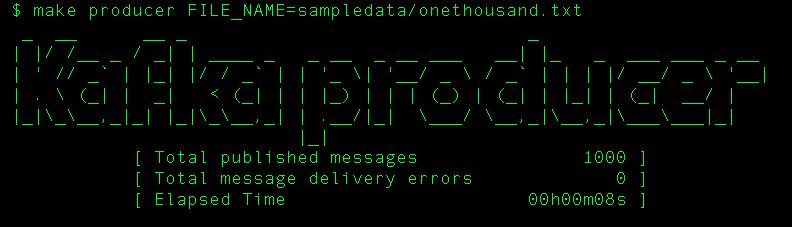
$ make producer FILE_NAME=sampledata/onethousand.txt
n Вот результат:
Теперь запустим потребителя на другой вкладке:
$ make consumer
Вывод:
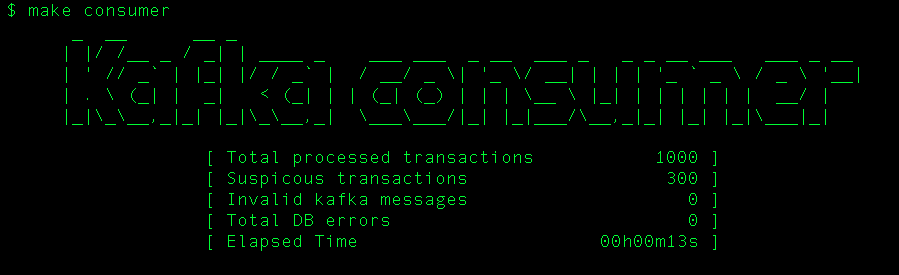
Как мы видим, мы сгенерировали файл с 1000 случайных финансовых транзакций, 30% из которых на сумму более 10 000 (1000 * 0,3 = 300), и эти 300 подозрительных транзакций были вставлены в MongoDB. Давайте проверим:
$ mongosh
Current Mongosh Log ID: 64871a56356a0638d1869007
Connecting to: mongodb://127.0.0.1:27017/?directConnection=true&serverSelectionTimeoutMS=2000&appName=mongosh+1.9.0
Using MongoDB: 6.0.6
Using Mongosh: 1.9.0
For mongosh info see: https://docs.mongodb.com/mongodb-shell/
------
The server generated these startup warnings when booting
2023-06-07T08:45:03.255-03:00: Access control is not enabled for the database. Read and write access to data and configuration is unrestricted
------
test> use fraud;
switched to db fraud
fraud> db.suspicious_transactions.countDocuments();
300
Отличный. Как насчет отправки 10 миллионов сообщений в эту тему? Насколько хорошо работает потребитель?
Пришло время качать: тестирование с 10 миллионами сообщений
Этот тест проводился на 16-дюймовом Macbook Pro с чипом M1 и 16 ГБ оперативной памяти.
Самый быстрый способ опубликовать 10 миллионов сообщений в теме Kafka — это использовать файл производитель консоли (kafka-console-producer), который поставляется вместе с установкой Kafka. Это невероятно быстро!
Цель в нашем Makefile для его вызова:
.PHONY: kafka-consumer-publish
## kafka-consumer-publish: Kafka's tool to read data from standard input and publish it to Kafka
kafka-consumer-publish:
@ if [ -z "$(FILE_NAME)" ]; then echo >&2 please set file name via the variable FILE_NAME; exit 2; fi
@ cat $(FILE_NAME) | kafka-console-producer --topic $(KAFKA_TOPIC) --bootstrap-server $(KAFKA_BROKER_HOST)
Теперь, предположим, что мы уже сгенерировали файл с 10 миллионами строк, из которых 30 % подозрительны, давайте вызовем его:
$ time make kafka-consumer-publish FILE_NAME=sampledata/tenmillion.txt
real 0m12.833s
user 0m14.339s
sys 0m4.473s
Ух ты. 13 секунд для публикации 10 миллионов сообщений.
Теперь давайте запустим потребителя... будет ли он достаточно быстрым для обработки всех этих данных?
$ make consumer
Вывод:
n  Это было быстро. 1 мин. 38 сек. до:
Это было быстро. 1 мин. 38 сек. до:
* проанализируйте сообщение.
* упорядочить его в структуру транзакции.
* проверьте, если это подозрительно, то есть проверьте, превышает ли сумма 10 000.
* сохранить его в базе данных, если он подозрительный.
Теперь давайте проверим MongoDB:
$ mongosh
Current Mongosh Log ID: 64871e25658763d4f7c01349
Connecting to: mongodb://127.0.0.1:27017/?directConnection=true&serverSelectionTimeoutMS=2000&appName=mongosh+1.9.0
Using MongoDB: 6.0.6
Using Mongosh: 1.9.0
For mongosh info see: https://docs.mongodb.com/mongodb-shell/
------
The server generated these startup warnings when booting
2023-06-07T08:45:03.255-03:00: Access control is not enabled for the database. Read and write access to data and configuration is unrestricted
------
test> use fraud;
switched to db fraud
fraud> db.suspicious_transactions.countDocuments();
3000000
Отлично. 30% от 10 млн — это 3 млн, поэтому в базе данных сохранено 3 млн подозрительных транзакций.
Дополнительные доступные цели Makefile
$ make help
Usage: make [target]
help shows this help message
zookeeper starts zookeeper
kafka starts kafka
kafka-consumer-publish Kafka's tool to read data from standard input and publish it to Kafka
clear-kafka-messages cleans all pending messages from Kafka
producer starts producer
consumer starts consumer
test runs tests
coverage run unit tests and generate coverage report in html format
sample-data generates sample data
Заключение
Анализ данных в режиме реального времени играет ключевую роль в некоторых областях, например в финансовой. В этом сценарии мы исследовали наивный подход к рассмотрению транзакции как подозрительной, просто проверив значение суммы.
В реальном сценарии, возможно, вы захотите добавить дополнительные проверки и даже использовать какое-то решение с искусственным интеллектом.
Мы увидели, как можно использовать горутины для параллельной обработки и насколько MongoDB работает быстрее, чем транзакционная БД в этом сценарии, где у нас высокая скорость приема.
В качестве бонусов мы рассмотрели:
* Абстракция пула исполнителей Goroutine.
* Как украсить вывод консоли CLI.
* Как более гибко читать флаги команд CLI.
Загрузить исходный код
Здесь: https://github.com/tiagomelo/realtime-data-kafka
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27409)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)