

PySpark важнее Pandas: одержимость каждого специалиста по данным
21 ноября 2022 г.В последние годы мы наблюдаем увеличение объема данных, в результате чего увеличивается время вычислений и объем памяти. Поэтому такие инструменты, как Pandas, которые работают последовательно, не достигают результата за требуемое время в больших наборах данных.
Некоторые пакеты, такие как Dask, Swift, Ray и т. д., могут распараллеливать работу панды. Распараллеливание процессов панды приводит к значительному ускорению. Тем не менее, существуют определенные ограничения памяти, вызванные вашей системой, поскольку Pandas загружает ваш фрейм данных в память, даже если это не требуется в этом конкретном случае. Это может стать серьезной проблемой для настольных систем, поскольку нам необходимо поддерживать работоспособность пользовательского интерфейса.
Нам нужен фреймворк для решения вышеуказанных проблем и достижения распараллеливания при данных ограничениях памяти. Spark решает некоторые из этих проблем при определенных пороговых значениях. Кроме того, он может выполнять более высокие скорости обработки. Он использует концепцию, называемую ленивой оценкой (как следует из названия, она оценивает данные при необходимости), которая устраняет некоторые ограничения, связанные с памятью.
Преимущества PySpark перед Pandas
- Pandas выполняет операции на одном компьютере, тогда как PySpark выполняет функции на нескольких устройствах, что делает его в 100 раз быстрее, чем Pandas для больших наборов данных.
- Pandas придерживаются принципа Eager Execution, то есть задачи выполняются как можно быстрее. Напротив, Pyspark придерживается отложенного выполнения, что означает, что задание не выполняется до тех пор, пока не будет выполнено действие.
- Pandas DataFrames не может создать масштабируемое приложение, но PySpark DataFrames идеально подходит для разработки масштабируемых приложений.
- Pandas DataFrame не гарантирует отказоустойчивость, но PySpark DataFrame гарантирует отказоустойчивость.
Когда использовать PySpark или Pandas?
Как я упоминал ранее, PySpark в 100 раз быстрее, чем Pandas; это всего лишь полуправда. Pandas и Pyspark имеют одинаковое время выполнения для начального ГБ данных, как показано в контрольном тесте ниже.
На начальном этапе, до 20 ГБ, они имеют одинаковую крутизну, но по мере увеличения размера файла у Pandas заканчивается память, и PySpark успешно выполняет задание.
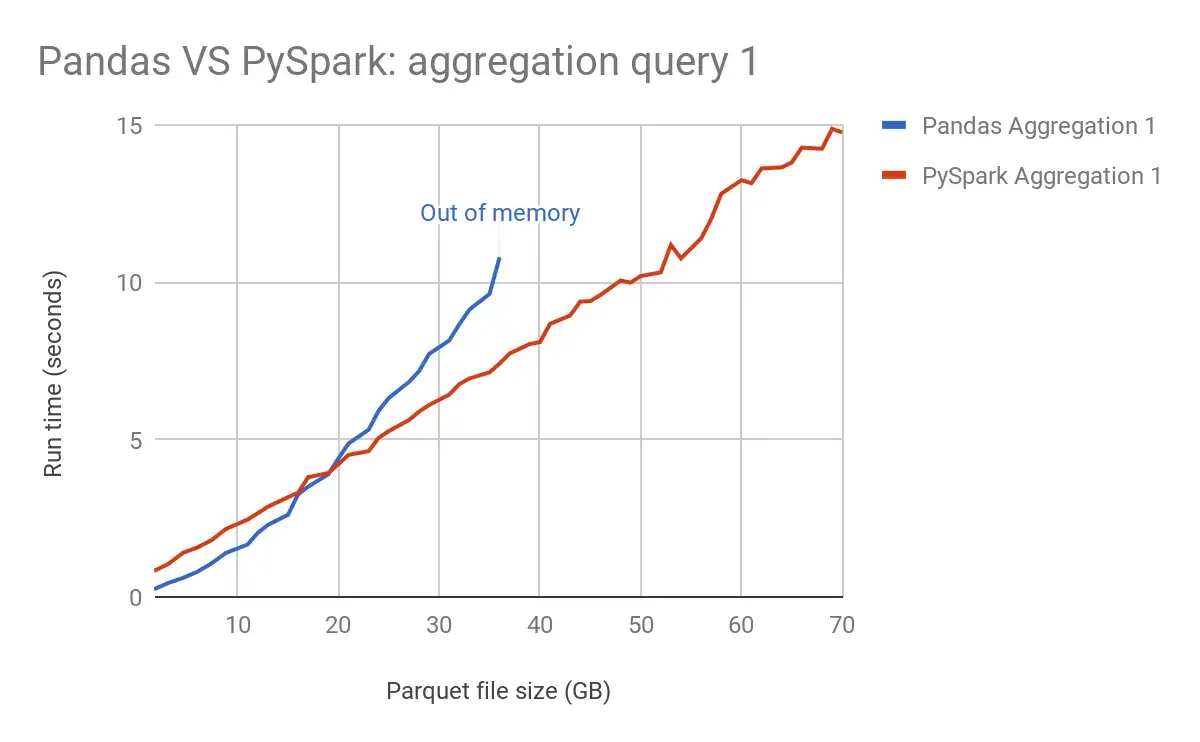
Benchmark Pandas and PySpark - [Source](https://hirazone.medium.com/benchmarking-pandas-vs-spark-7f7166984de2)
Поэтому для небольших наборов данных в 10–12 ГБ вы можете предпочесть Pandas PySpark из-за того же времени выполнения и меньшей сложности, а кроме того, вам придется работать с PySpark.
Ограничения PySpark
Все, что хорошо в чем-то, чего не хватает в других областях. Это также относится к PySpark. Вот некоторые из ограничений Pyspark:
- PySpark имеет более высокую задержку, что приводит к снижению пропускной способности.
- Потребление памяти очень велико.
- Для работы с PySpark разработано меньше алгоритмов и библиотек.
Из приведенного выше обсуждения мы можем сделать вывод, что по мере увеличения объема данных растет потребность в большем количестве фреймворков, таких как PySpark, которые могут легко обрабатывать такие процессы. Поэтому, если вы начинающий специалист по данным, вам следует начать изучать PySpark.
Первоначально опубликовано -87c708307c62">здесь.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
15 наборов данных Excel для начинающих аналитиков данных
20 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27164)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)