

Учебник по оптимизации вывода большой языковой модели (LLM): 1. Предыстория и формулировка проблемы
5 ноября 2024 г.Обзор вывода Большой языковой модели (LLM), ее значимость, проблемы и формулировки ключевых проблем.
Большие языковые модели (LLM) произвели революцию в области обработки естественного языка (NLP), обеспечив широкий спектр приложений: от чат-ботов и агентов ИИ до генерации кода и контента. Однако развертывание LLM в реальных сценариях часто сталкивается с проблемами, связанными с задержкой, потреблением ресурсов и масштабируемостью.
В этой серии постов в блоге мы рассмотрим различные методы оптимизации для вывода LLM. Мы погрузимся в стратегии сокращения задержек, объема памяти и вычислительных затрат, от механизмов кэширования до аппаратных ускорений и квантования моделей.
В этой статье мы дадим краткий обзор вывода LLM, его важности и связанных с ним проблем. Мы также обрисуем ключевые формулировки проблем, которые будут направлять наше исследование методов оптимизации.
Вывод модели: обзор
Вывод модели относится к процессу использования обученной модели машинного обучения для составления прогнозов или генерации выходных данных на основе новых входных данных. В контексте LLM вывод включает обработку текстового ввода и генерацию связного и контекстно-релевантного текстового вывода.
Модель обучается только один раз или периодически, в то время как вывод происходит гораздо чаще, вероятно, тысячи раз в секунду в производственных средах.
Оптимизация вывода имеет важное значение для обеспечения эффективного развертывания LLM в реальных приложениях. Цель состоит в том, чтобы минимизировать задержку (время, необходимое для генерации ответа), сократить потребление ресурсов (ЦП, ГП, память) и улучшить масштабируемость (способность справляться с растущими нагрузками).
Например, GPT-3 (с 175 миллиардами параметров) требует значительных вычислительных ресурсов для вывода. Оптимизации могут сократить время отклика с 1–2 секунд до миллисекунд, делая LLM более практичными для интерактивных приложений.
Обзор архитектуры трансформатора
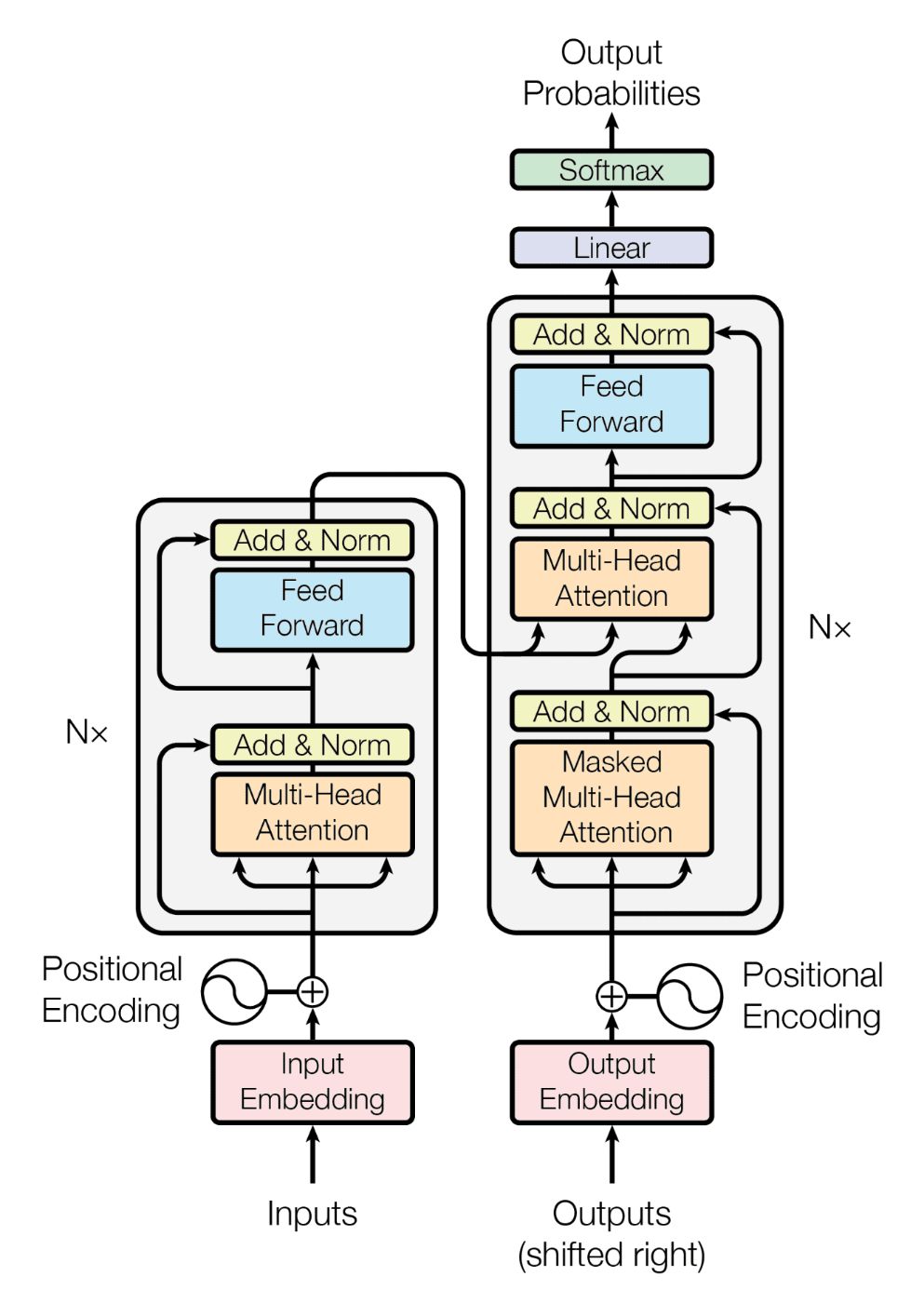
Архитектура трансформатора, использующая механизмы внимания, стала основой для большинства современных LLM. Эта архитектура включает позиционные кодировки, многоголовое самовнимание, нейронные сети прямого распространения и нормализацию слоев. Трансформаторы обычно подразделяются на три основных типа:
- Модели только с энкодером(например, BERT) предназначены для таких задач, как классификация текста и распознавание именованных сущностей. Они преобразуют входную последовательность в представление фиксированной длины — встраивание. Эти модели являются двунаправленными, то есть они рассматривают контекст как слева, так и справа от токена, что может привести к лучшему пониманию входного текста.
- Модели только с декодером(например, GPT-3) используются для задач генерации текста. Из входной последовательности они генерируют текст по одному токену за раз, обуславливая ранее сгенерированные токены. Эти модели являются однонаправленными, то есть они рассматривают только контекст слева от токена, что подходит для таких задач, как моделирование языка. Это наиболее распространенная архитектура LLM.
Модели кодера-декодера(например, T5) были оригинальной архитектурой, представленной в статье «Внимание — это все, что вам нужно». Эти модели предназначены для задач, требующих как понимания, так и генерации, таких как перевод и резюмирование. Они обрабатывают входную последовательность с помощью кодера, а затем генерируют выходную последовательность с помощью декодера.
Поскольку модели, содержащие только декодер, являются наиболее распространенной архитектурой LLM для задач авторегрессии, в этой серии статей основное внимание будет уделено методам оптимизации, предназначенным специально для этого типа моделей.
Обзор механизма внимания
Механизм внимания является ключевым компонентом архитектуры преобразователя, который позволяет модели фокусироваться на различных частях входной последовательности при генерации выходных данных. Он вычисляет взвешенную сумму входных представлений, где веса определяются релевантностью каждого входного токена для текущего генерируемого выходного токена. Этот механизм позволяет модели фиксировать зависимости между токенами, независимо от их расстояния во входной последовательности.
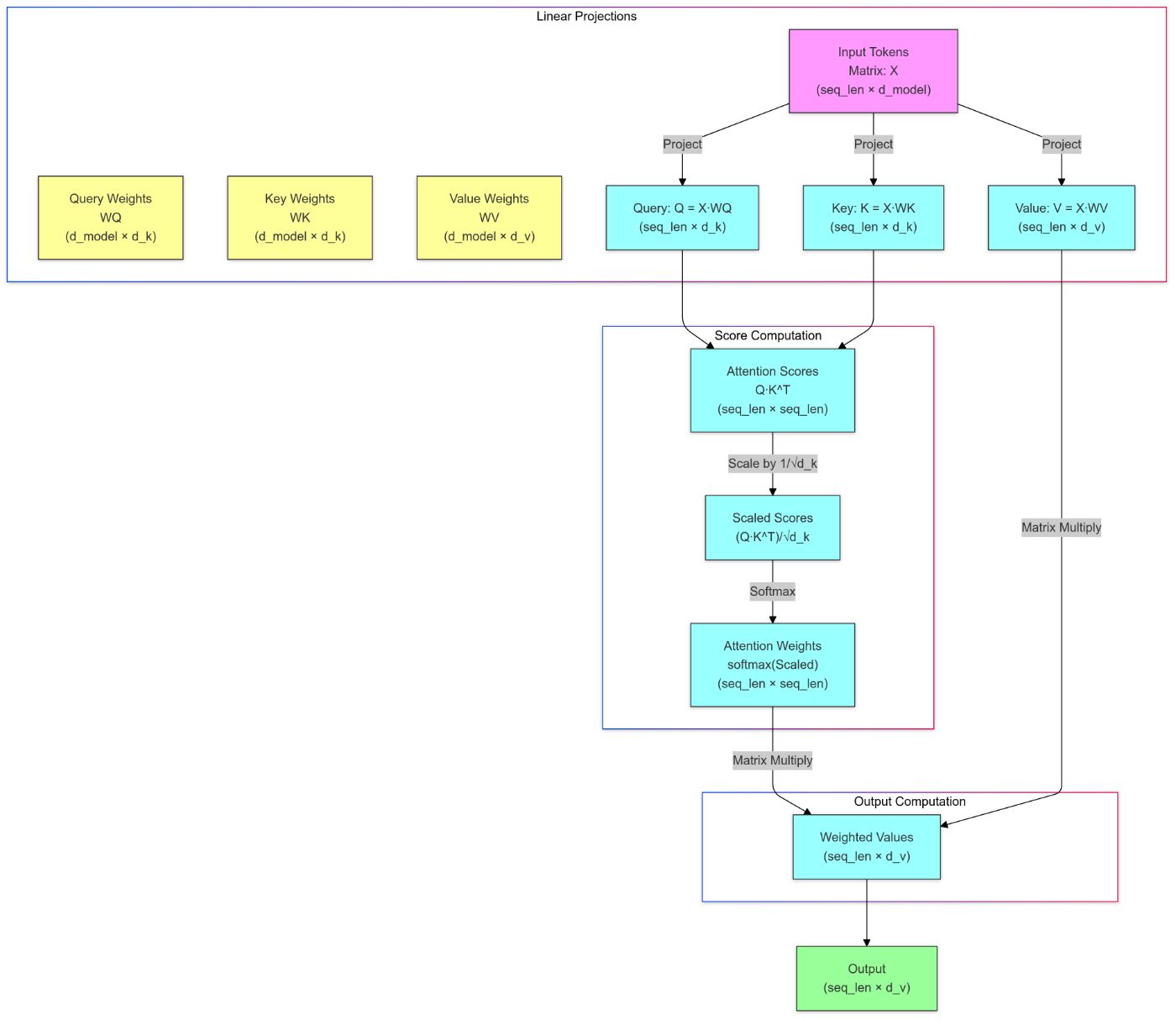
Механизм внимания может быть вычислительно затратным, особенно для длинных входных последовательностей, поскольку он требует расчета попарных взаимодействий между всеми токенами (O(n^2)сложность). Давайте рассмотрим это более подробно:
Представление входных данных: Каждый токен во входной последовательности представлен в виде вектора, обычно с использованием вложений.
Векторы запроса, ключа, значения: Для каждого токена вычисляются три вектора: вектор запроса (
Q_i), ключевой вектор (K_i) и вектор значений (V_i). Эти векторы выводятся из входных представлений с использованием изученных линейных преобразований.Оценки внимания: Оценки внимания вычисляются путем взятия скалярного произведения вектора запроса текущего токена с ключевыми векторами всех предыдущих токенов во входной последовательности. Это приводит к оценке, которая указывает, насколько много внимания следует уделять каждому токену.
Нормализация Softmax: Затем оценки внимания нормализуются с помощью функции softmax для получения весов внимания, которые в сумме дают 1.
Взвешенная сумма: Наконец, выходное представление для текущего токена вычисляется как взвешенная сумма векторов значений с использованием весов внимания.
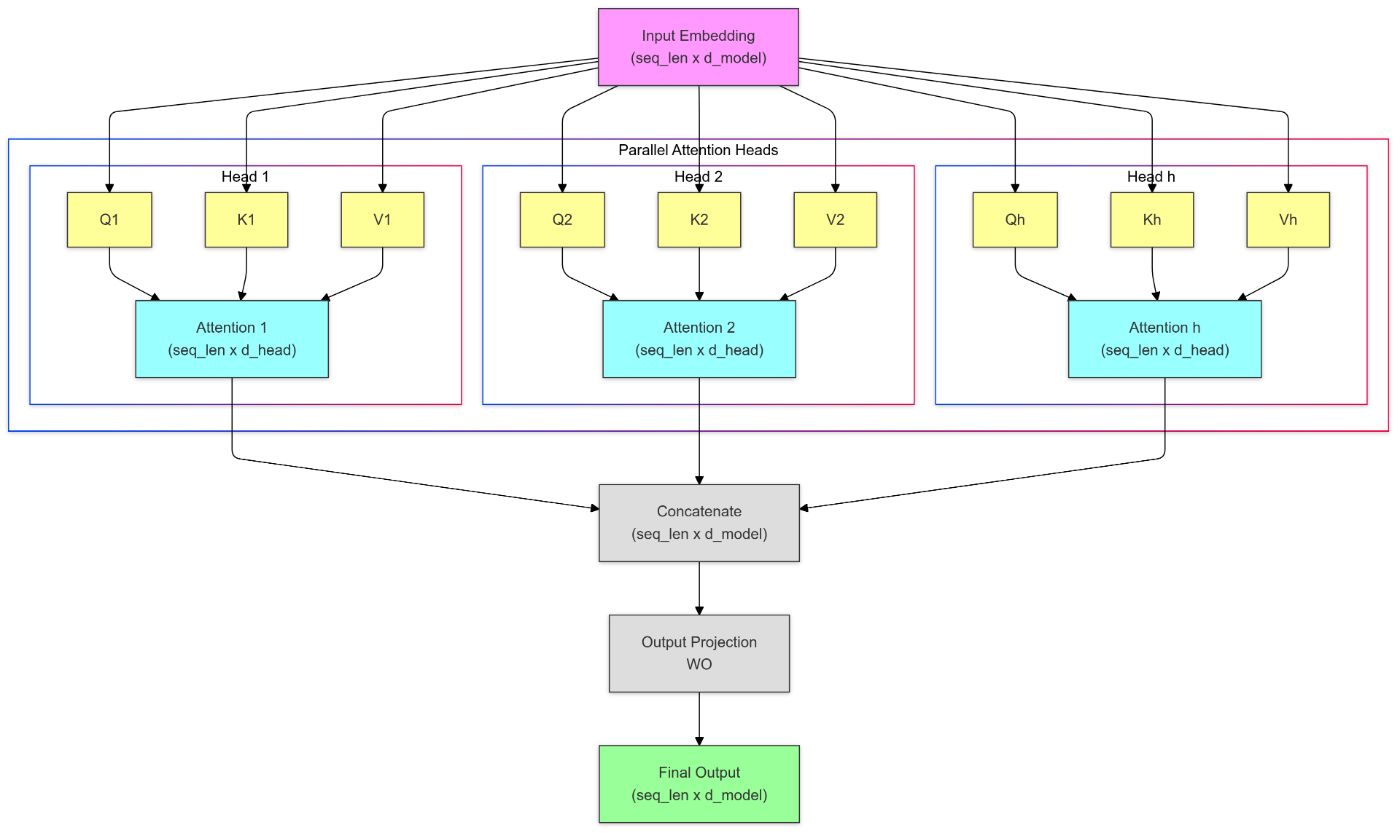
Многоголовое внимание
Многоголовое внимание — это расширение механизма внимания, которое позволяет модели совместно уделять внимание информации из разных подпространств представления в разных позициях. Вместо того, чтобы иметь один набор весов внимания, многоголовое внимание вычисляет несколько наборов оценок внимания параллельно, каждый со своими собственными выученными линейными преобразованиями.
Выходные данные этих головок внимания затем объединяются и линейно преобразуются для получения окончательного выходного представления.
Этот механизм расширяет возможности модели по учету разнообразных взаимосвязей и зависимостей во входных данных, что приводит к повышению производительности при выполнении различных задач обработки естественного языка.
Обзор процесса вычисления вывода
Понимая LLM и архитектуру преобразователя, давайте обрисуем процесс вычисления вывода. Вывод генерирует следующие $n$ токенов для заданной входной последовательности и может быть разбит на два этапа:
Стадия предварительного заполнения: На этом этапе выполняется прямой проход через модель для входной последовательности, и для каждого токена вычисляются представления ключей и значений. Эти представления сохраняются для последующего использования на этапе декодирования в кэше K-V. Представления всех токенов в каждом слое вычисляются параллельно.
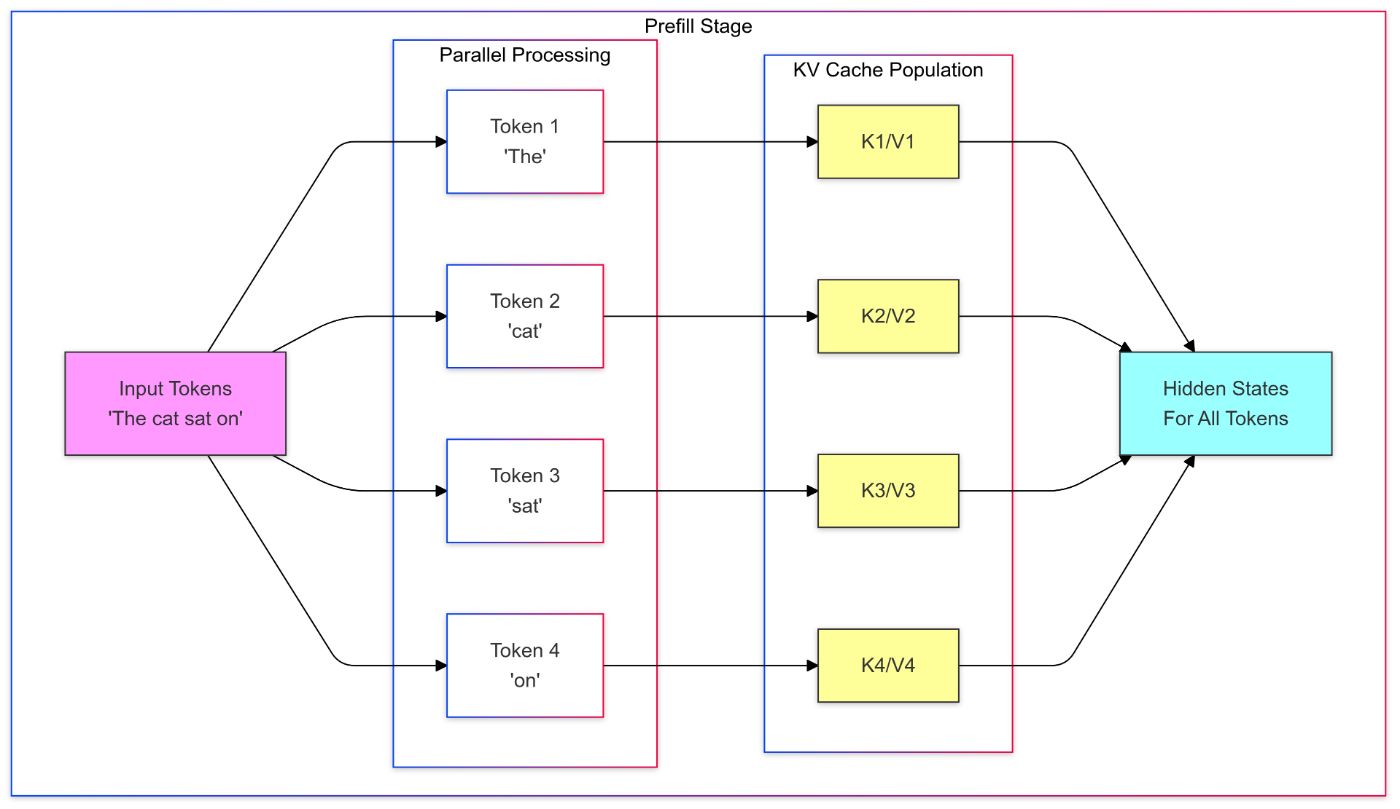
Стадия декодирования: На этом этапе модель генерирует выходные токены по одному за раз авторегрессивным способом. Для каждого токена модель извлекает представления ключей и значений из кэша K-V, сохраненного на этапе предварительного заполнения, вместе с представлением запроса текущего входного токена для вычисления следующего токена в последовательности.
Этот процесс продолжается до тех пор, пока не будет выполнен критерий остановки (например, достижение максимальной длины или генерация токена конца последовательности). Новые представления ключей и значений сохраняются в кэше K-V для последующих токенов. На этом этапе также применяется стратегия выборки токенов для определения следующего токена для генерации (например, жадный поиск, лучевой поиск, выборка top-k).
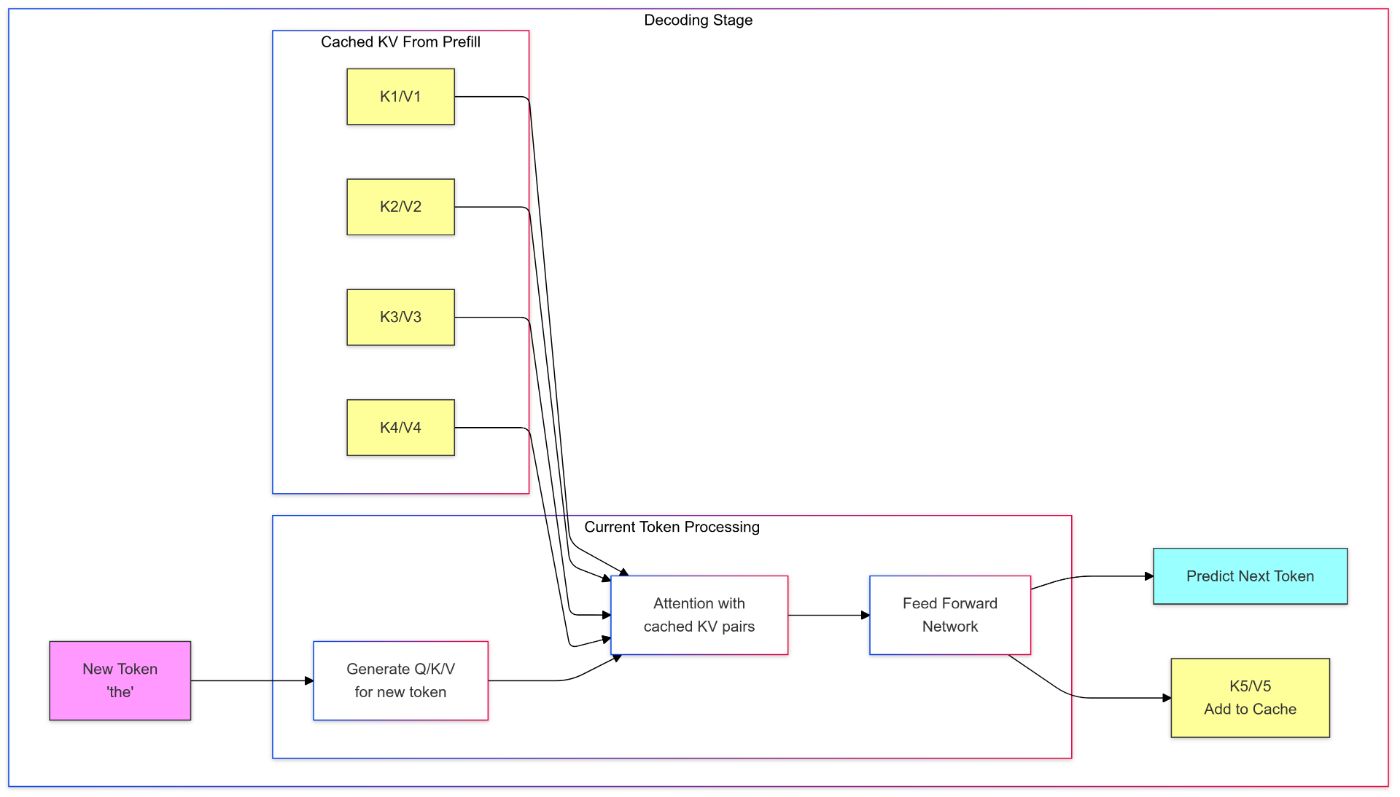
Сложность вычисления вывода
Для префикса длиныЛ, размер вложенияг, и модель счасголовы инслои, сложность вычисления вывода можно проанализировать следующим образом:
Стадия предварительного заполнения: На этапе предварительного заполнения мы вычисляем начальное представление для всех токенов на входе. Сложность здесь:
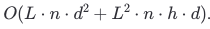 Здесь:
Здесь:- Первый срок
O(L.n .d^2): Представляет собой вычисление прямой связи, которое обрабатывает каждый токен независимо по слоям. Это масштабируется линейно с длиной последовательностиЛи количество слоевн.
Второй срок
O(L^2. n. h. d): Представляет стоимость механизма внимания. Здесь каждый токен взаимодействует с каждым другим токеном, что приводит кL^2Сложность расчета внимания на слой. Сложность растет квадратично с длиной последовательности, что может стать серьезным узким местом для длинных последовательностей.
- Первый срок
Стадия декодирования: Этап декодирования — авторегрессионная часть, сложность составляет:
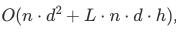
Здесь:
Расчет с прямой связью: Для каждого сгенерированного токена мы выполняем операции прямой связи в каждом слое. Поскольку это делается для одного токена за раз (не для всей последовательности), сложность на токен составляет:
O(n.d^2).Вычисление внимания с кэшированием: Каждый новый токен взаимодействует с существующей последовательностью через внимание, используя ранее вычисленные пары ключ-значение. Для каждого сгенерированного токена это вычисление внимания пропорционально длине последовательности L, что дает:
O(L.n.d .h)
Как мы видим, сложность вычисления вывода зависит от длины входной последовательности (Л), количество слоев (н), количество головок внимания (час) и размер встраивания (г). Эта сложность может стать узким местом в приложениях реального времени, особенно при работе с длинными входными последовательностями и/или большими моделями.
Важность кэширования K-V
Кэширование K-V является важнейшим методом оптимизации для вывода LLM, особенно на этапе декодирования. Сохраняя представления ключей и значений, вычисленные на этапе предварительного заполнения, модель может избежать избыточных вычислений для ранее обработанных токенов.
Это значительно снижает вычислительные затраты и задержку во время вывода, поскольку модели необходимо вычислить только оценки внимания для нового генерируемого токена, а не пересчитывать представления ключей и значений для всех токенов во входной последовательности.
Это делает стоимость линейной по отношению к количеству сгенерированных токенов, а не квадратичной по отношению к длине входных данных.
Однако кэширование K-V требует дополнительной памяти для хранения представлений ключей и значений, что может стать компромиссом в средах с ограниченными ресурсами.
Расчеты для примера модели
Давайте рассчитаем требования к памяти для модели LLaMA 7B.
Конфигурация модели
- Параметры:7миллиард
- Размер встраивания (
d_model): 4096 - Количество слоев:32
- Количество головок внимания (
d_head): 32 - Размер головы (
d_head): 128(4096/32) - Максимальная длина последовательности (L):2048
- Тип данных: float16 (2 байта на элемент)
Расчет памяти
- Размер кэша на уровне: Для каждого слоя нам необходимо хранить как ключи, так и значения.
Размер ключа на токен =
d_head × num_heads= 128 × 32 =4096элементыРазмер стоимости на токен =
d_head × num_heads= 128 × 32 = 4096элементыОбщее количество элементов на токен на слой = 4096 + 4096 =8192элементы
- Память на слой для полной последовательности: Для полной последовательности длины L =2048жетоны
Элементов на слой = L × 8192 = 2048 × 8192 =16,777,216элементы
Память на слой (в байтах) = 16 777 216 × 2 = 33 554 432 байта =33,55МБ
- Общий объем кэш-памяти KV для всех слоев: Так как у нас есть $32$ слоя
- Общая память = 33,55 × 32 МБ =1073,6 МБ
Общие требования к памяти
- Вес модели: 7 миллиардов параметров × 2 байта/параметр =14 ГБ
- Кэш-память KV:1073,6 МБ
- Другие накладные расходы памяти (например, активации, промежуточные результаты):~1-2 ГБ
Таким образом, общая потребность в памяти: 14 ГБ (вес модели) + 1-2 ГБ (издержки) + 1073,6 МБ (кэш KV) =15-16 ГБ. Этот расчет дает нам оценку требований к памяти для модели LLaMA 7B во время вывода. LLaMA 7B относительно невелика по сравнению с такими моделями, как GPT-3 (175 миллиардов параметров), которым потребовалось бы значительно больше памяти как для весов модели, так и для кэша KV.
Кроме того, при масштабировании до $m$ одновременных пользователей требования к ресурсам будут в $m$ раз выше. Таким образом, методы оптимизации имеют решающее значение для развертывания больших моделей в средах с ограниченными ресурсами.
Метрики для оценки оптимизации вывода
При оценке эффективности методов оптимизации вывода можно учитывать несколько показателей:
Задержка предварительного заполнения: Время, необходимое для выполнения этапа предварительного заполнения вывода, также называемое задержкой времени до первого токена (TTFT). Эта метрика имеет решающее значение для интерактивных приложений, где пользователи ожидают быстрых ответов. Такие факторы, как размер модели, длина ввода и возможности оборудования, могут влиять на эту метрику.
Задержка декодирования: время, необходимое для генерации каждого последующего токена после этапа предварительного заполнения, также называемое задержкой между токенами (ITL). Эта метрика важна для измерения отзывчивости модели во время генерации текста. Для таких приложений, как чат-боты, низкий ITL хорош, но быстрее не всегда лучше, так как 6-8 токенов в секунду часто достаточно для человеческого взаимодействия. Факторы, влияющие на размер кэша K-V, стратегия выборки и оборудование.
Задержка между конечными точками: Общее время, прошедшее от получения ввода до генерации конечного вывода. Эта метрика необходима для понимания общей производительности процесса вывода и зависит от предварительного заполнения, декодирования и других задержек компонентов (например, анализа JSON). К факторам, влияющим на это, относятся размер модели, длина ввода и оборудование, а также эффективность всего конвейера.
Максимальная скорость запросов, также известная как QPS (запросов в секунду): Количество запросов на вывод, которые могут быть обработаны в секунду. Эта метрика имеет решающее значение для оценки масштабируемости модели в производственных средах. Такие факторы, как размер модели, оборудование и методы оптимизации, могут влиять на QPS. Например, если 15 QPS обслуживается при задержке P90 через 1 GPU, то для обслуживания 300 QPS потребуется 20 GPU. Влияющие факторы включают аппаратные ресурсы, балансировку нагрузки и методы оптимизации.
FLOPS (операций с плавающей точкой в секунду): Количество операций с плавающей точкой, которые модель может выполнить за секунду. Эта метрика полезна для понимания вычислительной стоимости вывода и может использоваться для сравнения эффективности различных моделей и методов оптимизации. Факторы, влияющие на архитектуру модели, аппаратное обеспечение и методы оптимизации.
Типы методов оптимизации вывода
Мы рассмотрим все эти оптимизации в следующих публикациях серии.
- Оптимизация архитектуры модели: Изменение архитектуры модели для повышения эффективности вывода, например, уменьшение количества слоев или головок внимания или использование более эффективных механизмов внимания (например, разреженного внимания).
Оптимизация системы: Оптимизация базовой аппаратной и программной инфраструктуры, например, использование специализированного оборудования (например, TPU, GPU) или оптимизация программного стека (например, использование эффективных библиотек и фреймворков). Его можно разбить на:
Управление памятью: Эффективное управление использованием памяти для снижения накладных расходов и повышения производительности.
Эффективные вычисления: Использование параллелизма и оптимизация вычислений для сокращения задержек.
Дозирование: Одновременная обработка нескольких запросов для повышения пропускной способности.
Планирование: Эффективное планирование задач для максимального использования ресурсов.
Модель компрессии: Такие методы, как квантование, обрезка и дистилляция, можно использовать для уменьшения размера модели и повышения скорости вывода без существенного снижения производительности.
Оптимизация алгоритма: Улучшение алгоритмов, используемых для вывода, например, использование более эффективных стратегий выборки или оптимизация механизма внимания. Например, спекулятивное декодирование, которое позволяет модели генерировать несколько токенов параллельно, может значительно сократить задержку декодирования.

Заключение
В этом посте мы представили обзор вывода LLM, его важности и связанных с ним проблем. Мы также изложили ключевые формулировки проблем, которые будут направлять наше исследование методов оптимизации в последующих постах.
Понимая тонкости вывода LLM и факторы, влияющие на его производительность, мы можем лучше оценить значимость методов оптимизации в повышении практичности LLM для реальных приложений. В следующем посте мы более подробно рассмотрим конкретные методы оптимизации и их реализацию, сосредоточившись на сокращении задержки и потребления ресурсов при сохранении производительности модели.
Ссылки
- Все, что вам нужно — это внимание.
- Оптимизация вывода фундаментальных моделей на ускорителях ИИ
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27222)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)