
PolyThrottle: энергоэффективный анализ нейронных сетей на периферийных устройствах: возможности
3 апреля 2024 г.:::информация Этот документ доступен на arxiv под лицензией CC BY-NC-ND 4.0 DEED.
Авторы:
(1) Минхао Ян, Университет Висконсин-Мэдисон;
(2) Хонги Ван, Университет Карнеги-Меллон;
(3) Шиварам Венкатараман, myan@cs.wisc.edu.
:::
Таблица ссылок
- Абстрактное и amp; Введение
- Мотивация
- Возможности
- Обзор архитектуры
- Формулировка задачи: двухфазная настройка
- Моделирование помех в рабочей нагрузке
- Эксперименты
- Выводы и amp; Ссылки
- А. Подробности об оборудовании
- Б. Результаты экспериментов
- C. Арифметическая интенсивность
- Д. Анализ предикторов
3 ВОЗМОЖНОСТИ
В этом разделе мы проводим эмпирические эксперименты, чтобы раскрыть новые возможности оптимизации использования энергии в NN-выводах. Как обсуждалось в разделе 2, в предыдущей работе не изучалось влияние частоты памяти, минимальной частоты графического процессора и частоты процессора на энергопотребление. Это
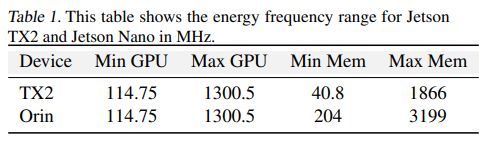
частично ограничено аппаратными ограничениями. Во время производства в устройство необходимо встроить специализированные шины питания, чтобы обеспечить точное измерение энергопотребления, связанного с каждым компонентом. Мы используем два комплекта разработчика Jetson: TX2 и Orin, которые предлагают встроенную поддержку
для покомпонентного измерения энергопотребления и настройки частоты, чтобы изучить, как эти частоты влияют на задержку вывода и энергопотребление в современных рабочих нагрузках глубокого обучения. Мы обнаружили, что частоты по умолчанию намного превышают оптимальные, и регулирование всех этих регуляторов частоты обеспечивает снижение энергопотребления с минимальным влиянием на задержку вывода.
Рисунок 3 иллюстрирует картину оптимизации энергопотребления при изменении частот графического процессора и памяти без каких-либо ограничений на задержку SLO. График показывает, что без каких-либо других ограничений ландшафт оптимизации энергопотребления обычно имеет форму чаши. Однако эта форма варьируется в зависимости от моделей, устройств и других гиперпараметров, таких как размеры партии (дополнительные результаты см. в Приложении B). Далее мы углубимся в то, как влияет каждый аппаратный компонент
вывод энергопотребления.
Настройка. Эксперименты в этом разделе выполняются с 16-битной точностью чисел с плавающей запятой, поскольку на практике было показано, что это оказывает минимальное влияние на точность модели. Мы используем модели Bert и EfficientNet и варьируем размер модели EfficientNet между B0, B4, B7 (таблица 4).
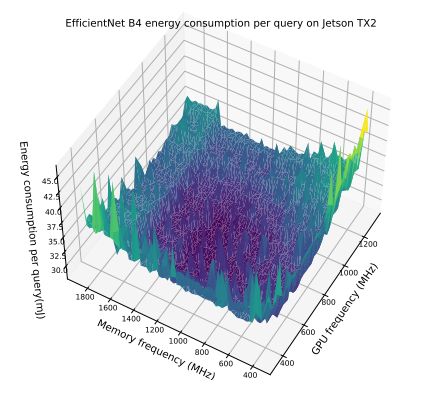
Эксперимент с частотой памяти. Для каждой модели мы фиксируем оптимальную частоту графического процессора, определенную путем поиска по сетке всех возможных конфигураций частоты. Затем мы исследуем компромисс между задержкой вывода и потреблением энергии по мере постепенного регулирования частоты памяти. Диапазон доступных частот памяти можно посмотреть в Таблице 1.
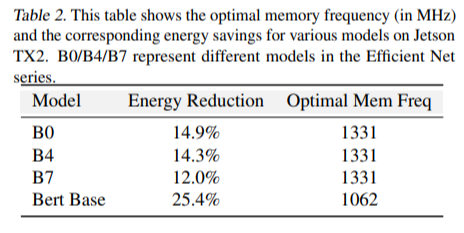
Результаты. Таблица 2 показывает, что частота памяти играет жизненно важную роль в снижении энергопотребления. Экономия, обеспечиваемая настройкой частоты памяти, одинакова и одинакова для всех моделей на обеих аппаратных платформах и составляет примерно от 12% до 25%. Это указывает на то, что
Частота памяти по умолчанию выше оптимальной для современных рабочих нагрузок глубокого обучения. Для тяжелых рабочих нагрузок, таких как Bert, основная часть снижения энергопотребления может быть достигнута за счет настройки памяти. Частично это можно объяснить тем, что приложения на основе Transformer привязаны к памяти.
модели (Иванов и др., 2021). Наш результат показывает, что системы, целью которых является оптимизация использования энергии при выводе нейронных сетей, должны учитывать частоту памяти.
Эксперимент с частотой процессора. Процессоры используются только для предварительной обработки данных. Таким образом, мы сначала измеряем время, затрачиваемое на обработку данных в конвейере вывода. Далее мы измеряем энергию, сэкономленную за счет регулирования частоты процессора, и оцениваем замедление задержки вывода, вызванное снижением частоты процессора. Предварительная обработка данных, которую мы выполняем, является стандартной почти для всех конвейеров обработки изображений и обнаружения объектов: мы читаем файл необработанного изображения, преобразуем его в
шкалу RGB, измените ее размер и ориентацию в соответствии с желаемым входным разрешением и расположением данных.
Результаты. Время предварительной обработки в разных моделях EfficientNet остается постоянным, поскольку выполняемые операции идентичны. В результате относительное влияние настройки ЦП на общее энергопотребление зависит от соотношения времени предварительной обработки и времени вывода. По мере увеличения размера модели и увеличения продолжительности вывода влияние настройки ЦП на общее энергопотребление уменьшается. Мы видим, что на платформах Jetson TX2 и Orin настройка ЦП может снизить энергопотребление предварительной обработки примерно на 30%. В зависимости от модели, уровня квантования и размера пакета это приводит к снижению общего энергопотребления до 6 %.
Эксперимент с минимальной частотой графического процессора. Мы сохраняем конфигурацию оборудования по умолчанию и регулируем только минимальную частоту графического процессора на Jetson Orin. Увеличение минимальной частоты графического процессора заставляет механизм GPU DVFS работать в меньшем диапазоне. Масштабируем модель от
От EfficientNet B0 до EfficientNet B7, чтобы проиллюстрировать влияние минимальной частоты графического процессора на задержку вывода.
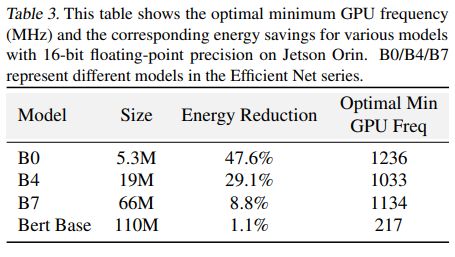
Результаты. В таблице 3 показано, что настройка минимальной частоты графического процессора может значительно снизить энергопотребление, когда рабочая нагрузка не может полностью использовать вычислительную мощность оборудования. Примечательно, что потребление энергии и задержка вывода сокращаются за счет принудительной работы графического процессора.
на более высокой частоте. Это отличается от компромисса, наблюдаемого в других экспериментах, где мы обмениваем задержку вывода на более низкое энергопотребление. Настройка минимальной частоты графического процессора может почти вдвое снизить энергопотребление небольших моделей. Поскольку вычислительная мощность становится насыщенной с увеличением размера модели, отдача от настройки минимальной частоты графического процессора уменьшается.
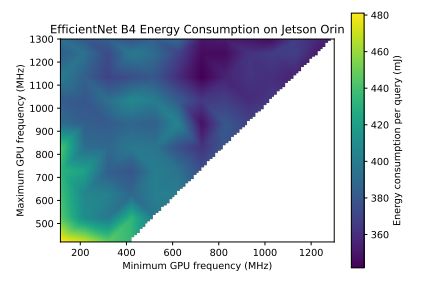
На рисунке 4 показаны затраты энергии на каждый запрос при изменении минимальной и максимальной частоты графического процессора. Он показывает, что увеличение минимальной частоты графического процессора по сравнению с минимумом по умолчанию приводит к снижению затрат энергии и задержки вывода.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27188)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)