
PolyThrottle: Энергоэффективный анализ нейронных сетей на периферийных устройствах: мотивация
3 апреля 2024 г.:::информация Этот документ доступен на arxiv под лицензией CC BY-NC-ND 4.0 DEED.
Авторы:
(1) Минхао Ян, Университет Висконсин-Мэдисон;
(2) Хонги Ван, Университет Карнеги-Меллон;
(3) Шиварам Венкатараман, myan@cs.wisc.edu.
:::
Таблица ссылок
- Абстрактное и amp; Введение
- Мотивация
- Возможности
- Обзор архитектуры
- Формулировка задачи: двухфазная настройка
- Моделирование помех в рабочей нагрузке
- Эксперименты
- Выводы и amp; Ссылки
- А. Подробности об оборудовании
- Б. Результаты экспериментов
- C. Арифметическая интенсивность
- Д. Анализ предикторов
2 МОТИВАЦИЯ
Многие глубокие нейронные сети были развернуты на периферийных устройствах для выполнения таких задач, как классификация изображений, обнаружение объектов и диалоговые системы. Сценарии, включающие умных домашних помощников (He et al., 2020), мониторинг запасов и цепочек поставок (jet) и автопилот (Gog et al., 2022), часто используют устройства на батарейном питании, которые содержат графические процессоры для выполнения вышеупомянутых задач. В этих сценариях предварительно обученные модели устанавливаются на устройства, на которых выполняется рабочая нагрузка вывода
развернуто.
Предыдущие работы были сосредоточены на оптимизации энергопотребления графических процессоров (Wang et al., 2020b; 2021; Tang et al., 2019; Strubell et al., 2019; Mei et al., 2017) в облачных сценариях (Qiao et al. , 2021; Wan et al., 2020; Hodak et al., 2019) и условия обучения (Wang et al., 2020a; Peng et al., 2019;
Канг и др., 2022). Рабочие нагрузки вывода на устройстве имеют разные характеристики и требуют отдельного внимания. В этом разделе мы описываем предыдущие усилия по оптимизации вывода нейронных сетей на устройствах и обсуждаем наш подход к комплексной оптимизации энергопотребления.
2.1. Развертывание нейронной сети на устройстве
Предыдущие работы по оптимизации вывода нейронных сетей на устройстве фокусировались на квантовании (Ким и др., 2021; Баннер и др., 2018; Курбарио и др., 2015; 2014; Голами и др., 2021), разработке аппаратного обеспечения. дружественные сетевые архитектуры (Xu et al., 2019; Lee et al., 2019; Sanh et al., 2019; Touvron et al., 2021; Howard et al., 2019) и использование аппаратных компонентов, специфичных для мобильных настроек, такие как DSP (Lane & Georgiev, 2015). Наша работа исследует ортогональное измерение и направлена на ответ на другой вопрос: Если нейронную сеть нужно развернуть на конкретном устройстве, как мы можем настроить это устройство для снижения энергопотребления?
В нашей работе мы ориентируемся на периферийные устройства, которые содержат процессоры, память и графические процессоры. Эти устройства, как правило, более мощные, чем DSP, которые часто встречаются на мобильных устройствах. Одним из таких примеров является серия Nvidia Jetson, которая способна обрабатывать широкий спектр приложений, от искусственного интеллекта до робототехники и встроенных решений IoT (jet). Устройства также оснащены возможностями динамического масштабирования напряжения и частоты (DVFS), которые позволяют оптимизировать энергопотребление и управление температурой при выполнении сложных вычислительных задач. Серия Jetson имеет унифицированную память, совместно используемую как центральным, так и графическим процессором. В этой статье мы называем рабочую частоту процессора, графического процессора и общей памяти частотой процессора, частотой графического процессора и частотой памяти.
Пример управления запасами. Чтобы понять системные требования при выводе граничной NN, мы далее опишем практический пример того, как NN развертываются в компании, занимающейся управлением запасами. Судя по нашим разговорам, компания А работает с клиентом Б над развертыванием нейронных сетей на периферийных устройствах для оптимизации управления запасами. В целях соблюдения правил и защиты конфиденциальности данные с каждого сайта инвентаризации должны храниться локально. Огромная разница в структуре запасов делает невозможным предварительное обучение модели на данных с каждого склада. Таким образом, эти устройства поставляются с предварительно обученной моделью, основанной на данных из небольшой выборки инвентарных ресурсов, которые могут иметь существенно отличающуюся планировку и внешнюю среду по сравнению с фактическим местом развертывания. Следовательно, требуется ежедневная точная настройка для повышения производительности развернутых сайтов, поскольку среда постоянно развивается. Аналогичные аргументы применимы и к устройствам «умного дома», где модель предварительно обучается на выбранных свойствах, но развернутые домохозяйства могут быть гораздо более разнообразными. Чтобы решить проблемы конфиденциальности, на устройстве
Точная настройка нейронных сетей предпочтительна, поскольку конфиденциальные данные хранятся локально. Поэтому периферийным устройствам часто необходимо выполнять как логический вывод, так и периодическую точную настройку. Объединение нескольких рабочих нагрузок на периферийных устройствах может привести к нарушениям SLO из-за помех и повышенного энергопотребления.
2.2 Комплексная оптимизация энергопотребления
В некоторых недавних работах изучалось снижение энергопотребления за счет оптимизации размера пакета и максимальной частоты графического процессора (You et al., 2022; Nabavinejad et al., 2021; Komoda et al., 2013; Gu et al., 2023) и разработка моделей мощности для современных графических процессоров (Kandiah et al., 2021; Hong & Kim, 2010;
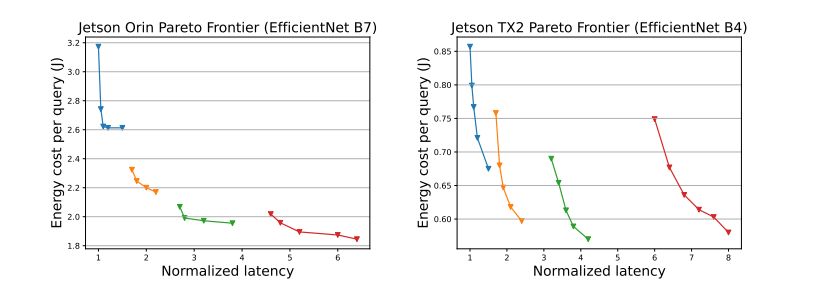
Арафа и др., 2020; Лоу-Пауэр и др., 2020). В этой работе мы утверждаем, что другие аппаратные компоненты также вызывают энергетическую неэффективность и требуют отдельной оптимизации. Мы выполняем поиск по сетке по частотам графического процессора, памяти и процессора и различным размерам пакетов, чтобы изучить границу Парето по задержке вывода и энергопотреблению. На рис. 2 показан компромисс между потреблением энергии на каждый запрос и задержкой вывода (нормированной на оптимальную задержку) на Jetson TX2 и Jetson Orin. Каждая точка на рисунке представляет собой оптимальную конфигурацию, которую мы находим с помощью поиска по сетке при заданном бюджете задержки вывода и размере пакета. Как показано на рисунке 2, граница Парето не является гладкой в глобальном масштабе, и ее трудно охватить с помощью простой модели, что требует более сложных методов оптимизации для быстрой сходимости к конфигурации оборудования, лежащей на границе Парето (Censor, 1977).
Zeus (You et al., 2022) пытается снизить энергопотребление при обучении нейронной сети, изменяя предел мощности графического процессора и настраивая размер обучающего пакета. PolyThrottle также учитывает эти два фактора. В Zeus (You et al., 2022) основное внимание уделяется учебным нагрузкам в центрах обработки данных.
где настройка размера пакета помогает достичь порога точности энергоэффективным способом. Мы включаем размер пакета в состав PolyThrottle, поскольку он обеспечивает компромисс между задержкой вывода и пропускной способностью. Наша эмпирическая оценка открывает новые возможности для оптимизации, которые усложняют пространство поиска, о чем мы опишем далее.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27242)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)