
PolyThrottle: Энергоэффективный анализ нейронных сетей на периферийных устройствах: экспериментальные результаты
3 апреля 2024 г.:::информация Этот документ доступен на arxiv под лицензией CC BY-NC-ND 4.0 DEED.
Авторы:
(1) Минхао Ян, Университет Висконсин-Мэдисон;
(2) Хонги Ван, Университет Карнеги-Меллон;
(3) Шиварам Венкатараман, myan@cs.wisc.edu.
:::
Таблица ссылок
- Абстрактное и amp; Введение
- Мотивация
- Возможности
- Обзор архитектуры
- Формулировка задачи: двухфазная настройка
- Моделирование помех в рабочей нагрузке
- Эксперименты
- Выводы и amp; Ссылки
- А. Подробности об оборудовании
- Б. Результаты экспериментов
- C. Арифметическая интенсивность
- Д. Анализ предикторов
B РЕЗУЛЬТАТЫ ЭКСПЕРИМЕНТА
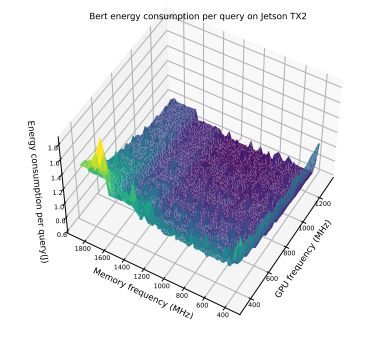
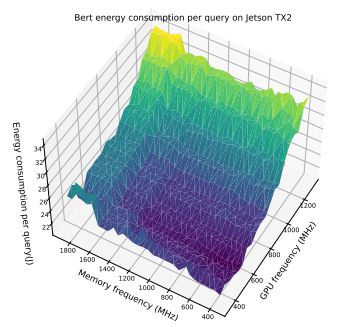
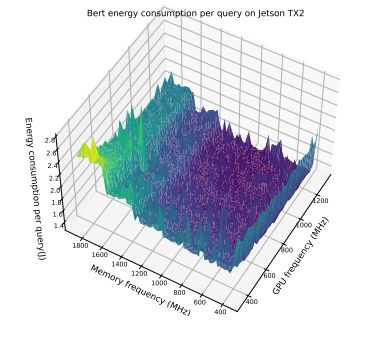
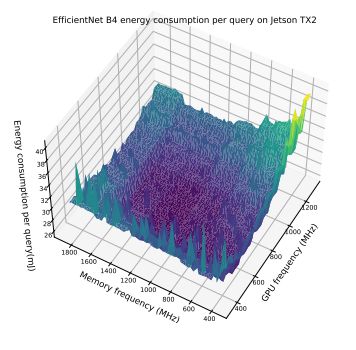
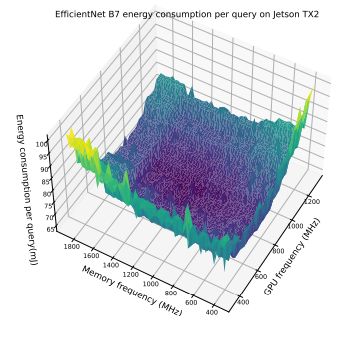
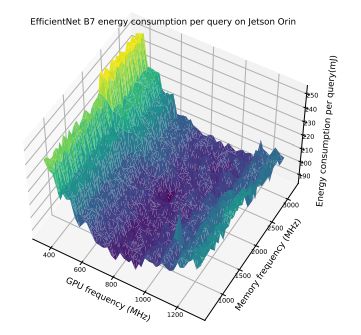
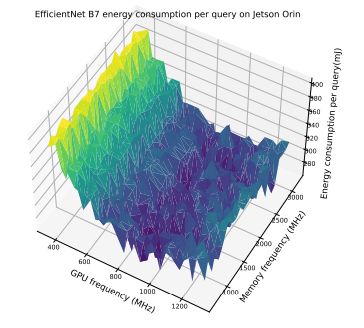
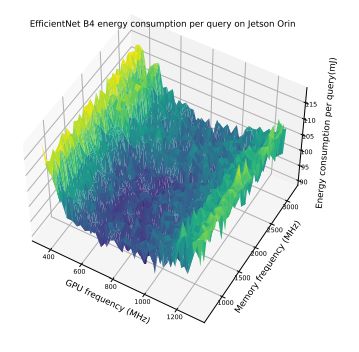
В этом разделе мы дополнительно продемонстрируем компромисс между частотой памяти и максимальной частотой графического процессора, представив массив результатов. Эти результаты подчеркивают интересное наблюдение о том, что модели энергопотребления различаются для одной и той же модели, работающей на разных устройствах. Более того, даже для пары устройств одной модели на картину оптимизации может существенно влиять размер партии. Это подчеркивает сложность оптимизации энергопотребления и необходимость адаптивной структуры, которая могла бы принять во внимание эти факторы. На рисунках 6–12 показаны модели энергопотребления EfficientNet и Bert на Jetson TX2 и Orin при различных размерах партий. В таблице 7 показаны оптимальная частота процессора и соответствующее снижение энергопотребления при предварительной обработке изображений.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)