
Выбор неправильного формата файлов Spark может повредить вашей стратегии данных
2 июля 2025 г.Одним из наиболее важных решений в вашем трубопроводе Apache Spark являетсяКак вы храните свои данныеПолем Формат данных, который вы выберете, может резко повлиять на производительность, затраты на хранение и скорость запроса. Давайте рассмотрим наиболее распространенные форматы файлов, поддерживаемые Apache Spark, и в каких случаях они могут соответствовать наибольшему количеству.
Разные форматы файлов
Существуют различные типы форматов данных, обычно используемых в обработке данных, особенно с такими инструментами, какApache Spark, сломалсякатегорииНа основании их структуры и вариантов использования:
Форматы файлов на основе строк
Данные хранятсяряд по ряду, и это легко писать и обрабатывать линейно, номенее эффективноДля аналитических запросов, где необходимо всего несколько столбцов.

CSV(Запятые значения)
CSVэто простой текст, формат на основе строк, где столбцы разделены запятыми. С ним легко работать, но не эффективно для больших данных.
Плюс: CSV читается человеком, просто писать и читать, и используется во всем мире.
Минусы: CSV не хватает типов данных, требуя от Spark выводить типы столбцов из образца файла CSV, который добавляет дополнительную работу и может быть не точной. Кроме того, CSV имеет плохое сжатие и борется с кодирующими сложными данными.
Варианты использования: Legacy Systems, небольшие экспорты данных, отладка и работа с электронными таблицами.
ЧтениеCSV -файлВ примере Apache Spark:
# Pyspark example df = spark.read.options(delimiter=",", header=True).csv(path) # Scala example val df = spark.read.option("delimiter", ",").option("header", "true").csv(path)Json (javascript object obtation)
Jsonявляется легким текстовым форматом для обмена данными. Он используетЧеловеческийТекст для хранения и отправки информации, но она может быть медленной и не обеспечивать соблюдение схемы.
Плюс: Jsonчитается и широко поддерживается многими системами и может хранитьполуструктурнаяданные.
Минусы: Jsonмедленно разбирается, и каждая строка должна быть действительным JSON для Spark для анализа. Кроме того, с точки зрения хранения JSON создает большие файлы, потому что в каждом строке повторяются многие токены с шаблонами и имена ключевых, и ему не хватает применения схемы.
Вариант использования: В основном используйтеJsonдля отладки или изучения данных. Его также можно использовать для интеграции с внешними системами, которые предоставляютJson, что вы не можете контролировать, но не зависят от этого как окончательного формата данных хранения.
ЧтениеФайл jsonВ примере Apache Spark:
# Pyspark example df = spark.read.json(path) # Scala example val df = spark.read.json(path)Apache Avro
Apache AvroЯвляется ли формат на основе строк, часто используется сКафкатрубопроводы иОбмен даннымиСценарии. Он поддерживаетОписательная расширяемая схемаи является компактным для сериализации.
Плюс: Avroэффективен в хранении, поскольку он находится в бинарном формате и имеет отличную функцию эволюции схемы.
Минусы: ПокаAvroэффективно в хранилище, он не оптимизирован для столбчатых запросов, поскольку вам нужно сканировать весь файл, чтобы прочитать конкретные столбцы.
Вариант использования: Avroв основном используется с помощью потоковых систем в реальном времени, таких какКафкаПотому что это легко сериализовать и передавать. Это также позволяет легко развивать схемы через реестр схемы.
Модуль Spark-avro внешний и не включен в Spark-Submit или Spark Shell по умолчанию, но
spark-avro_VERSIONи его зависимости могут быть напрямую добавлены кspark-submitс использованием--packages./bin/spark-submit --packages org.apache.spark:spark-avro_VERSION ./bin/spark-shell --packages org.apache.spark:spark-avro_VERSIONЧтениеAVRO FILEВ примере Apache Spark:
# Pyspark example df = spark.read.format("avro").load(path) # Scala example val df = spark.read.format("avro").load(path)Форматы столбцов
Данные хранятсястолбец по столбцу, делая их идеальными дляаналитика и интерактивные панели мониторингагде запрашивается только подмножество столбцов.
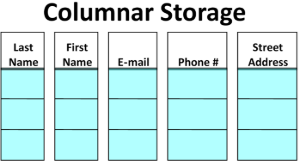
Паркет (золотой стандарт для аналитики)
Паркетявляется столбчатым двоичным форматом, оптимизированным для аналитических запросов. Это самый популярный формат для рабочих нагрузок Spark.
Плюсы:Пакет построен для эффективных считываний с сжатием и предикатом, что делает его быстрым, компактным, идеально подходит для искры, улей, Presto.
Минусы:Паркет немного медленнее, чем форматы на основе строк.
В случае использования:Parquet - это первый выбор для искры и аналитических запросов, озеров данных, облачного хранилища.
ЧтениеПаркетный файлВ примере Apache Spark:
# Pyspark example df = spark.read.parquet(path) # Scala example val df = spark.read.parquet(path)Apache Orc (оптимизированный столбец строки)
Оркявляется еще одним столбчатым форматом, оптимизированным для экосистемы Hadoop, особенно Hive.
Плюсы:Оркимеет высокий коэффициент сжатия и оптимизирован для тяжелых сканированных запросов и поддерживает предикаты отжимания, аналогичного парке.
Минусы:Оркимеет меньше поддержки вне инструментов Hadoop, что затрудняет интеграцию с другими инструментами.
В случае использования:На основе улей хранилища данных, системы HDFS.
ЧтениеФайл orcВ примере Apache Spark:
# Pyspark example df = spark.read.format("orc").load(path) # Scala example val df = spark.read.format("orc").load(path)Сводная таблица
Формат | Тип | Сжатие | ПРЕДИСКИЙ ДОПУСК | Лучший вариант использования |
|---|---|---|---|---|
Паркет | Столбец | Отличный | ✅ Да | Большие данные, аналитика, селективные запросы |
Орк | Столбец | Отличный | ✅ Да | Основа на основе улей |
Avro | На основе строк | Хороший | ❌ Нет (ограничен) | Кафка трубопроводы, эволюция схемы |
Json | На основе строк | Никто | ❌ Нет | Отладка, интеграция |
CSV | На основе строк | Никто | ❌ Нет | Наследие форматы, проглатывание, разведка |
Заключение
Выбор правильного формата файла в SparkНе просто техническое решение, но этостратегическийПолем Parquet и ORC являются твердым выбором для большинства современных рабочих нагрузок, но ваш вариант использования, инструменты и экосистема должны направлять ваш выбор.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)