

PCIC модель дизайна: прогноз выкупа на уровне категории и ранжирование элементов частоты
13 августа 2025 г.Таблица ссылок
Аннотация и 1 введение
- Литературный обзор
- Модель
- Эксперименты
- Путешествие по развертыванию
- Будущие направления и ссылки
3 модель
3.1 Моделирование выкупа на уровне категории
Мы используем функции уровня категории, чтобы предсказать вероятность выкупа клиентов. У каждого клиента есть свои собственные функции, созданные историей их покупки, а последние дни данных о покупке клиента используются для создания метки для обучения модели на уровне категории. Вся история покупок до этого M Days используется для создания функций. Любая категория, в которой клиенты выкупили элемент в этот период времени, считается меткой 1, в то время как другие категории назначают метку 0. Основные функции, рассматриваемые для обучения модели, перечислены в последующих подразделах. История покупки клиента до этого периода времени используется для получения функций.
3.1.1 Анализ выживанияПолем Анализ выживания фокусируется на ожидаемой продолжительности времени до появления интересующего события. Он отличается от традиционной регрессии тем фактом, что части учебных данных могут быть только частично наблюдать, что указывается как цензура. Для этих цензурных наблюдений мы только знаем, что время события больше, чем время в точке цензуры. В сценарии розничной торговли мы рассматриваем покупку товара в категории в качестве события. Для каждой категории могут затем использоваться данные о повторении покупки для построения жизненной таблицы по клиентам для каждой категории, что позволит нам прогнозировать риск повторения покупки в зависимости от времени. Жизненная таблица суммирует события и цензуры по времени. В момент времени 0 все наблюдения (справочные покупки) все еще находятся в опасности, что означает, что они еще не повторили покупку (событие) и не подвергались цензуре. По мере того, как происходят события и цензуры, наблюдения выпадают из набора риска.
Данные повторения покупки могут быть использованы для вычисления нескольких полезных функций:
1. Опасность (уравнение 1) является вероятностью события, возникающего в KTH, условной на событии, не происходящем до дня K. Это обозначает приблизительную вероятность того, что событие (выкупа) происходит в данном интервале времени, при условии, что пользователь останется без событий до этого времени (без покупки).

2. Cum_hazard (уравнение 2) - это кумулятивная сумма опасности с течением времени.
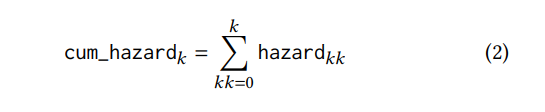
3. Выживание (уравнение 3) является вероятностью события, произошедшего после дня k или, эквивалентно, доля, которая еще не испытала события по времени t.

4. cum_survival (уравнение 4) как вероятность возникновения событий через ± 3 дня до сегодняшнего дня. Мы дополнительно определяем эту функцию, поскольку многие продуктовые клиенты делают покупки один раз в неделю.
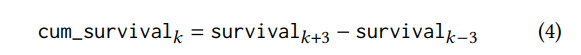
5. Нормализованный_тиск (уравнение 5) определяется как риск, связанный с категорией пользователя сегодня как часть риска в день покупки.
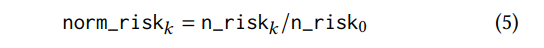
6. Normalized_event (уравнение 6) определяется как вероятность события в данный день, нормализованную с помощью события плюс цензура.
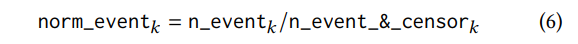
Создание этой модели дает обзор уровня населения уровня выкупа предмета. Например, мы наблюдаем, что люди в основном выкупают бананы каждые 7 дней и чистящие средства каждые 21 день, поэтому функция опасности максимизируется в то время между покупками. На основании последней даты покупки каждого элемента клиентом мы можем использовать анализ выживания, чтобы предсказать дату выкупа или вероятность выкупа через n дней.
3.1.2 Arima Models.Авторегрессивная интегрированная скользящая средняя или модели ARIMA полезны для краткосрочных прогнозов по нестационарной задаче временных рядов. Для каждого клиента и категории мы стараемся охарактеризовать их шаблон покупки с помощью ARIMA и предсказать на следующий день покупки. Модели ARIMA имеют три параметра (P, D, Q), где P-порядок авторегрессивной модели, D-степень различия, а Q-порядок средней модели движения. Мы строим одну модель ARIMA, которая соблюдает прошлые даты закупок в категории, чтобы предсказать следующую и вторую модель, чтобы рассмотреть количество приобретенного предмета, и предсказать текущую ставку потребления клиентом (скажем, X использует 2 унции шампуня ежедневно). Затем это используется для прогнозирования даты, когда клиент, скорее всего, закончится из элемента. Для каждой пары клиента-категорий мы тренируем эти модели и используем их прогнозы Arima (Date) и Arima (ставка) в качестве функций.
3.1.3 Другие функции.Мы рассмотрим еще три функции уровня поведенческой категории: numpurchases - количество раз, когда данный клиент приобрел в категории, TripsSincelastPurcharched - количество покупок в других категориях, которые клиент совершил с момента покупки в этой категории, DaysIncelastPurcharded - разница во времени между сегодня и последней датой покупателя.
3.1.4 Обучение модели.Мы проводим последние 1,5 года данных по покупкам пользователей, чтобы обучить модель, чтобы убедиться, что мы захватываем ежегодную каденцию. Последние М Дни данных проводятся для генерации меток. Например - мы можем взять набор данных января 2021-24 июля 2022 года, чтобы создать функции для всех гостей. Для тех гостей, которые делали покупки в течение 25 - 31 июля (M = 7), мы генерируем этикетки 0 и 1 для категорий, которые не покупали и не делали покупки соответственно. 6 особенностей из модели выживания, 2 прогноза из
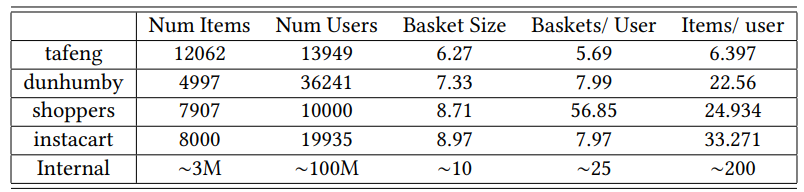
Две модели ARIMA и 3 другие функции, упомянутые ранее, генерируются для каждой пары пользователей и категорий.
Мы обучили нейронную сеть 2 уровня в наборе данных о покупке гостей на уровне категории. Мы хотели, чтобы это было легким, потому что количество входных функций мало (11), и мы хотели, чтобы он хорошо масштабировался для большого количества пользователей. Наиболее эффективная нейронная сеть состояла из 2 полностью связанных слоев (10 и 5 нейронов) с сигмоидными активациями. Выходной слой выполняется через Softmax, а функция логистических потерь используется для оптимизации.
3.2 Ранки межкатегорий продукта
В целом, мы заметили, что клиент, скорее всего, выкупит их наиболее часто или совсем недавно купленные предметы. Двумя основными функциями, используемыми для ранжирования продуктов в категории, являются частота (FREQ) и Recency (REC) покупки. Мы хотели объединить их оба, чтобы получить оптимальные ранги, однако, резиновая деятельность измеряется в дни, и частота является подсчетом. Чтобы прийти на общий язык, мы превращаемся в оба в ряды. Ранг частоты предметов (IFR) и ранг резинги (IRR) получены путем ранжирования количества частот и дней (соответственно) с момента последней покупки предмета (DaysInceChase). Ifr = 𝑅𝑘 (𝐹𝑟𝑒𝑞), irr = 𝑅𝑘 (𝐷𝑎𝑦𝑠𝑆𝑖𝑛𝑐𝑒𝑃𝑢𝑟𝑐ℎ𝑎𝑠𝑒). Мы комбинируем ряды, используя средневзвешенное, снова ранжирование, а затем делим рейтинг на количество раз, когда предмет куплен (𝑁𝐼𝐵). Это понимание было основано на отзывах пользователей и будет обсуждаться в последующих разделах. Уравнение 5.2 показывает, как рассчитывается окончательный ранг предмет (IR).
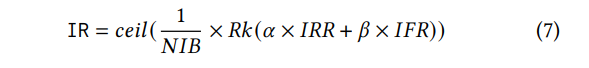
где параметры 𝛼 и 𝛽 были получены с использованием исчерпывающего поиска сетки в диапазоне [0,1].
3.3 Выход модели

Авторы:
(1) Амит Панде, Data Sciences, Target Corporation, Бруклин Парк, Миннесота, США (amit.pande@target.com);
(2) Кунал Гош, Data Sciences, Target Corporation, Бруклин Парк, Миннесота, США (kunal.ghosh@target.com);
(3) Парк Ранкинг, Data Sciences, Target Corporation, Бруклин Парк, Миннесота, США (Rancyung.park@target.com).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)