Распознавание действий человека стало активной областью исследований в сообществе глубокого обучения. Основная цель заключается в идентификации и классификации действий человека в видео с использованием нескольких входных потоков, таких как видео- и аудиоданные.
Одно конкретное применение этой технологии связано с областью порнографии, где возникают уникальные технические проблемы, усложняющие процесс распознавания действий человека. Такие факторы, как вариации освещения, окклюзии и существенные различия в ракурсах камеры и методах съемки, затрудняют распознавание действия.
Даже когда два действия идентичны, различные перспективы камеры могут привести к путанице в прогнозах модели. Чтобы решить эти проблемы в области порнографии, мы использовали глубокое обучение методы, которые обучаются на различных входных потоках, включая RGB, Skeleton (Pose) и аудиоданные. Наиболее эффективные модели с точки зрения производительности и времени выполнения включают архитектуры на основе преобразователя для потока RGB, PoseC3D для скелетного потока и ResNet101 для аудиопотока.
Результаты этих моделей объединяются с использованием позднего слияния, при этом значимость каждой модели в окончательной схеме оценки различается. Альтернативная стратегия может включать обучение модели с двумя входными потоками одновременно, например, RGB+скелет или RGB+аудио, и последующее объединение их результатов. Однако этот подход не подходит из-за свойств, присущих данным.
Входные аудиопотоки полезны только для определенных действий, в то время как другим действиям не хватает определенных звуковых характеристик. Точно так же модель на основе скелета применима только тогда, когда оценка позы превышает определенный доверительный порог, который сложно достичь для некоторых действий.
Используя метод позднего слияния, подробно описанный в последующих разделах, мы достигаем впечатляющей точности в 90% для двух лучших прогнозов среди 20 различных категорий. Эти категории охватывают широкий спектр сексуальных действий и поз.
Модели
Входной поток RGB
Основным и наиболее надежным входным потоком для модели являются кадры RGB. Двумя наиболее эффективными архитектурами в этом контексте являются трехмерные сверточные нейронные сети (3D CNN) и модели, основанные на внимании. Модели, основанные на внимании, особенно те, которые используют архитектуру трансформатора, в настоящее время считаются самыми современными в этой области. Следовательно, мы используем архитектуру на основе трансформатора для достижения оптимальной производительности. Кроме того, модель демонстрирует возможности быстрого логического вывода: для обработки 7-секундных видеоклипов требуется примерно 0,53 секунды.
Поток ввода скелета
Изначально скелет человека извлекается с использованием модели обнаружения человека и оценки позы в 2D. Извлеченная информация о скелете затем передается в PoseC3D, трехмерную сверточную нейронную сеть (3D CNN), специально разработанную для распознавания действий человека на основе скелета. Эта модель также считается самой современной в этой области. В дополнение к своей производительности, модель PoseC3D демонстрирует эффективные возможности логического вывода: для обработки 7-секундных видеоклипов требуется примерно 3 секунды.
Из-за сложной перспективы, с которой сталкиваются во многих действиях (например, невозможно извлечь надежные позы, которые помогут модели идентифицировать действие пальцевого большую часть времени), распознавание действий человека на основе скелета используется выборочно, специально для подмножества действий, которое включает сексуальные позы
Входной аудиопоток
Для входного аудиопотока используется архитектура на основе ResNet, основанная на модели Audiovisual SlowFast. Этот подход применяется к меньшему набору действий по сравнению с методом на основе скелета, в первую очередь из-за ограниченной информации, доступной с точки зрения звука для надежной идентификации действий в этой конкретной области.
Набор данных
Собранный набор данных является обширным и разнородным, включая широкий спектр типов записи, в том числе запись с точки зрения (POV), профессиональную, любительскую, с выделенным оператором или без него, а также различные фоновые условия, людей и камеру. перспективы. Набор данных содержит примерно 100 часов обучающих данных, охватывающих 20 различных категорий. Однако в наборе данных наблюдались некоторые несбалансированности категорий. Усилия по устранению этих дисбалансов рассматриваются для будущих итераций набора данных.
Архитектура
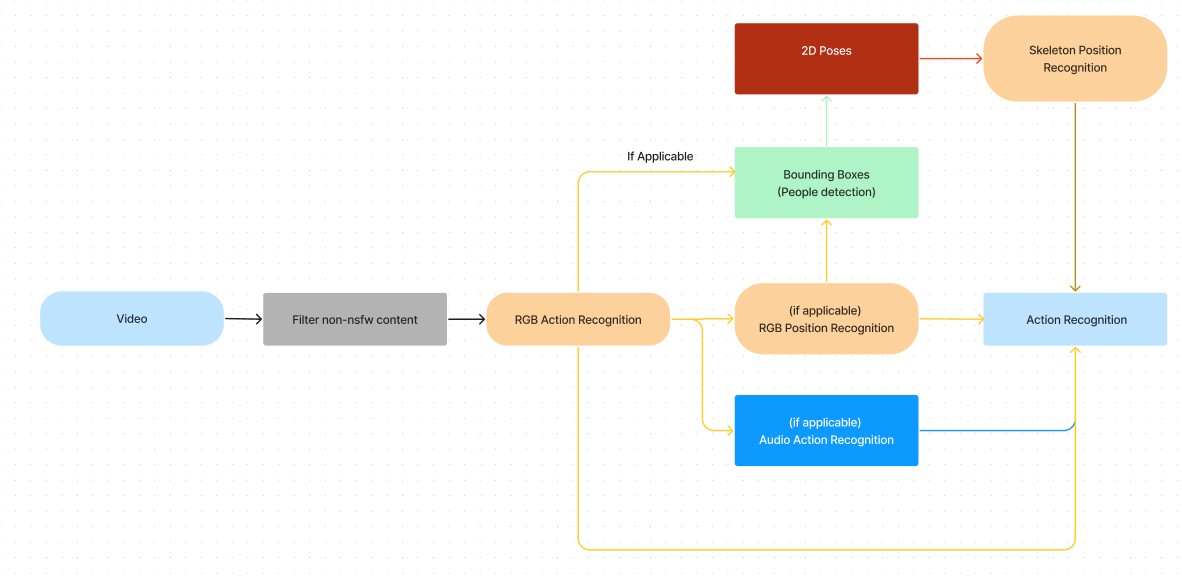
На приведенном выше рисунке представлен обзор конвейера ИИ, используемого в нашей системе.
Изначально для выявления сегментов видео, не относящихся к NSFW, используется упрощенная модель обнаружения NSFW, что позволяет нам обходить остальную часть конвейера для этих разделов. Такой подход не только ускоряет общее время вывода видео, но и сводит к минимуму ложные срабатывания. Запускать модели распознавания действий на нерелевантных кадрах, таких как дом или автомобиль, не нужно, поскольку они не предназначены для распознавания такого контента.
После этого предварительного шага мы развертываем модель быстрого распознавания действий на основе RGB. В зависимости от двух верхних результатов этой модели мы определяем, следует ли выполнять модель распознавания положения на основе RGB, модель распознавания действий на основе звука или модель распознавания действий на основе скелета. Если один из двух верхних прогнозов модели распознавания действия RGB соответствует категории позиции, мы переходим к модели распознавания позиции RGB, чтобы точно определить конкретную позицию.
Затем мы используем ограничительную рамку и 2D-модели поз для извлечения человеческого скелета, который затем вводится в модель распознавания положения на основе скелета. Результаты модели распознавания положения в RGB и модели распознавания положения скелета объединяются посредством позднего слияния.
Если аудиогруппа обнаружена в пределах двух верхних меток, выполняется модель распознавания действий на основе аудио. Его результаты объединены с результатами модели распознавания действий RGB посредством позднего слияния.
Наконец, мы анализируем результаты моделей действий и позиций, генерируя один или два окончательных прогноза. Примеры таких предсказаний включают в себя отдельные действия (например, Миссиси***), комбинации позиций и действий (например, Наездница и Поцелуй или Собачка и Ан*л) или двойные действия (например, Кунн***нгус и Ампир). Ф****нг).
:::информация Для получения дополнительной информации вы можете прочитать нашу Документацию по API P-HAR
.:::