
Со временем Лора держится лучше
17 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 фон
3 Экспериментальная настройка и 3,1 наборов данных для продолжения предварительной подготовки (CPT) и создания инструкций (IFT)
3.2 Измерение обучения с помощью кодирования и математических показателей (оценка целевой области)
3.3 Забыть метрики (оценка доменов источника)
4 Результаты
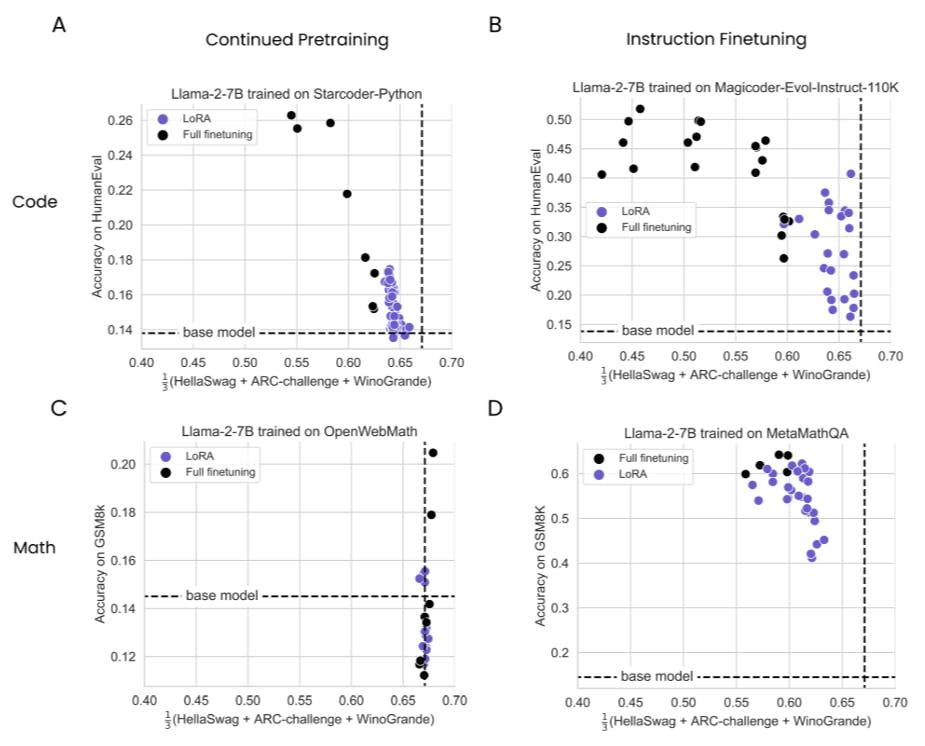
4.1 Lora Underperforms Полное создание в программировании и математических задачах
4.2 Лора забывает меньше, чем полное создание
4.3 Обмен на обучение
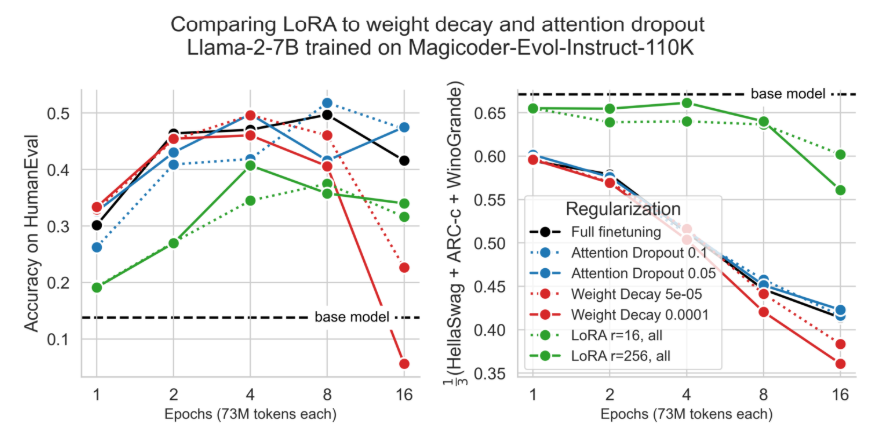
4.4 Свойства регуляризации Лоры
4.5 Полная производительность на коде и математике не изучает низкие возмущения
4.6 Практические выводы для оптимальной настройки LORA
5 Связанная работа
6 Обсуждение
7 Заключение и ссылки
Приложение
А. Экспериментальная установка
B. Поиски скорости обучения
C. Обучающие наборы данных
D. Теоретическая эффективность памяти с LORA для однократных и мульти-GPU настройки
4.2 Лора забывает меньше, чем полное создание
Мы определяем забывание как деградация в среднем со стороны Hellaswag, Arc-Schallenge и Winogrande и исследуем его степень как функцию данных на рис. 3.
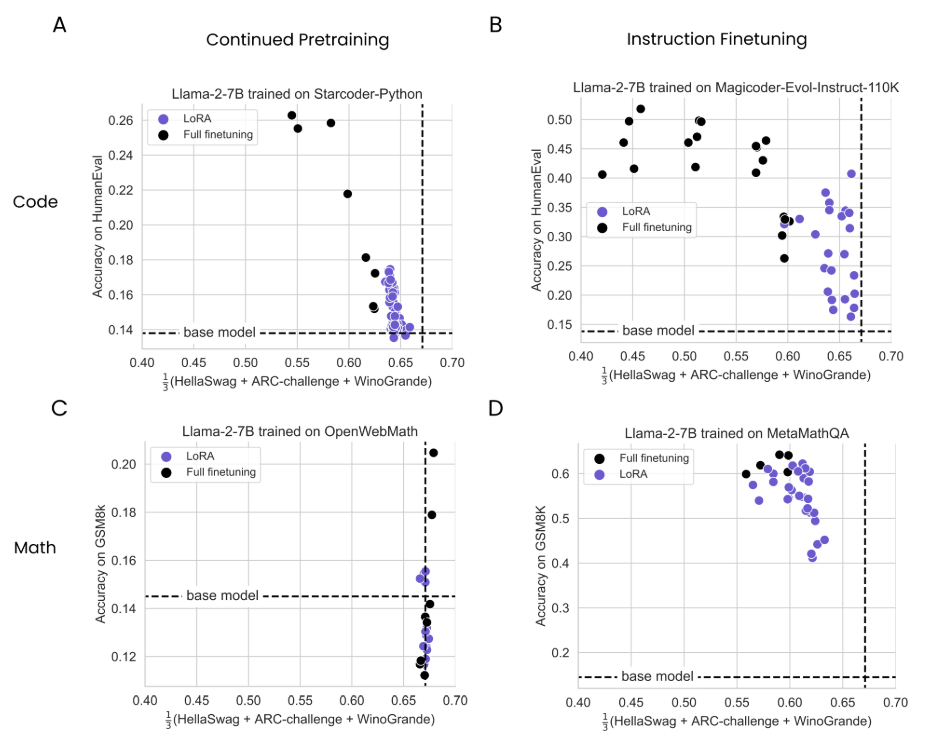
В целом, мы наблюдаем, что (1) IFT индуцирует больше забывания, чем CPT, (2) программирование вызывает больше забывания, чем математика, и (3) забывание имеет тенденцию увеличиваться с данными. Что наиболее важно, Лора забывает меньше, чем полное создание, и, как и в 4.1, эффекты более выражены для домена программирования. В коде CPT кривая забывающей, примерно постоянна, в то время как полная конфигурация ухудшается с большим количеством данных (метрика забыть о пиковом гуманевировании: полное создание = 0,54 при 20B токенах, лора = 0,64 при 16B токенах). В программировании IFT оба метода разлагаются при обучении для большего количества эпох, и при их пиковой производительности (4 и 8 эпох), Лора оценивает 0,63 и полные оценки в массовой информации 0,45. Для математики нет четких тенденций в наборе данных CPT OpenWebmath, за исключением того, что и Lora, и Full Menetuning выставлены не забывать. Вероятно, это связано с тем, что в наборе данных OpenWebMath преобладает английские предложения, в отличие от набора данных StarCoder-Python, который является большинством кода Python (подробности см. 3,1). В математике LORA снова забывает меньше, чем полное создание (0,63 против 0,57, репрезентативно, в эпоху 4).
Авторы:
(1) Дэн Бидерман, Колумбийский университет и Databricks Mosaic AI (db3236@columbia.edu);
(2) Хосе Гонсалес Ортис, DataBricks Mosaic AI (j.gonzalez@databricks.com);
(3) Джейкоб Портес, DataBricks Mosaic AI (jportes@databricks.com);
(4) Mansheej Paul, DataBricks Mosaic AI (mansheej.paul@databricks.com);
(5) Филип Грингард, Колумбийский университет (pg2118@columbia.edu);
(6) Коннор Дженнингс, DataBricks Mosaic AI (connor.jennings@databricks.com);
(7) Даниэль Кинг, DataBricks Mosaic AI (daniel.king@databricks.com);
(8) Сэм Хейвенс, DataBricks Mosaic AI (sam.havens@databricks.com);
(9) Vitaliy Chiley, DataBricks Mosaic AI (vitaliy.chiley@databricks.com);
(10) Джонатан Франкл, DataBricks Mosaic AI (jfrankle@databricks.com);
(11) Коди Блакни, DataBricks Mosaic AI (Cody.blakeney);
(12) Джон П. Каннингем, Колумбийский университет (jpc2181@columbia.edu).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)