Проектирование бессерверной системы может оказаться сложной задачей, и, не зная внутренней работы сервисов, вы можете легко потерять данные.
Крутая кривая обучения — главный недостаток создания бессерверных приложений на AWS. AWS могла бы лучше создать идеальные условия для разработчиков. Мы увидели некоторые небольшие улучшения, но до идеальной платформы еще далеко. Мало того, опыт разработки мог бы быть лучше. Во многих случаях фактическое поведение противоречит первоначальным ожиданиям разработчика, и вы можете легко потерять данные или получить неожиданные результаты без глубокого понимания Сервисы AWS. Хорошая платформа должна абстрагировать детали от разработчика. Но в случае с AWS это не так.
Начнем с общего. В более традиционных, не управляемых событиями системах вы записываете данные непосредственно в базу данных, и потеря данных означает, что в базе данных возникла проблема. Но бессерверные системы в значительной степени являются системами, управляемыми событиями, и данные в конечном итоге являются согласованными. Помещение данных/событий в такую систему не обязательно означает, что они сразу же записываются в базу данных. Его можно передавать между несколькими шинами событий, pub-sub и системами потоковой передачи событий… и в большинстве случаев он заканчивается в NoSQL база данных, такая как DynamoDB, которая по своей природе является согласованной. Если вы помещаете данные/событие в такую систему и в конечном итоге они не попадают в пункт назначения или вы не получаете их при извлечении из базы данных, у вас возникает проблема. Данные также могут быть потеряны, продублированы, вы получите более старые записи, чем ожидалось, и т. д.
В названии этой статьи упоминается потеря данных, но на самом деле мы рассмотрим все эти случаи.
Обзор содержания: девять способов потерять данные при использовании бессерверных технологий, даже не подозревая об этом
- Дубликаты и неупорядоченные события
- Массовые операции
- В конечном итоге согласовано
- Фильтр DynamoDB
- Сообщения очереди недоставленных писем теряются по истечении периода хранения.
- Сообщение о ядовитой таблетке также может привести к потере следующих сообщений.
- Отставание при обработке данных
- Регулирование
- Отсутствует/неправильно настроено DLQ и превышено максимальное количество повторов
1. Дублирующиеся и неупорядоченные события
Это наиболее распространенный способ деформации данных. Большинство сервисов не гарантируют заказ и единовременную доставку. SQS FIFO и SNS FIFO обеспечивают это, а системы на основе потоков, такие как DynamoDB Streams и Kinesis Streams, обеспечивают гарантии порядка. SQS FIFO и SNS FIFO менее масштабируемы и более дороги, чем их обычные аналоги, поэтому их следует использовать только в том случае, если у вас есть веские причины.
В большинстве случаев следует ожидать, что события будут запускаться неупорядоченно и их можно будет дублировать. Обработка неупорядоченных сообщений означает, что вам не следует заменять новую запись более старой записью, полученной позже. Обработка повторяющихся событий означает, что система должна быть идемпотентной. Например, если вы получили списание на свой банковский счет, вам следует убедиться, что та же транзакция еще не была обработана.
<блок-цитата>Большинство сервисов AWS не гарантируют заказ и единовременную доставку. Вы должны убедиться, что ваша система идемпотентна.
Хотя большинству разработчиков это известно, это противоречит базовой интуиции, и мы довольно легко забываем, что Lambda, подписанная на SQS, SNS и EventBridge, может запускаться несколько раз с одной и той же полезной нагрузкой. Но то же самое и с другими, менее используемыми сервисами. Если вы сохраните данные в S3 через Kinesis Firehose и запросите их у Athena, может возникнуть та же проблема. Kinesis Firehose может дублировать записи. Athena ведет себя как база данных SQL, но это не означает, что она имеет все ограничения, присущие базам данных SQL. Записи с одинаковым идентификатором можно довольно легко дублировать, а запросы, которые этого не ожидают, будут возвращать неверные результаты.
<блок-цитата>Athena ведет себя как база данных SQL, но не имеет ограничений. Записи с одинаковым идентификатором можно дублировать.
2. Массовые операции
Возможно, это самая опасная вещь, о которой разработчики часто забывают, поскольку она противоречит базовой интуиции. Чего ожидать, если одна или несколько записей не будут выполнены при массовой вставке в SQS, SNS, EventBridge, DynamoDB или Kinesis? Что ж, если вы ожидали, что SDK выдаст ошибку, поэтому проблема будет зарегистрирована, и, возможно, весь процесс можно будет повторить или перенести в какую-нибудь очередь писем о сделках (DLQ)… вы были бы неправы. SDK не выдает ошибку. Он просто возвращает список неудачных записей. Вы не узнаете, потеряли ли вы данные, если не проверите этот список. Проблемы идут дальше с операциями чтения. Если вы выполняете операцию массового получения в DynamoDB и не получаете некоторые записи, можно ожидать, что эти записи не существуют. Опять неправильно. SDK возвращает записи, которые ему удалось получить, а также записи, которые ему не удалось обработать (поле UnprocessedKeys), но это не означает, что записи отсутствуют в базе данных. >
Неудачные массовые операции с использованием AWS SDK не приводят к возникновению ошибки. Возможно, вы теряли данные.
Самое смешное, что в SDK для EventBridge нет даже немассовой операции. Таким образом, даже если вы вставите одну запись, вы все равно используете массовый подход и можете потерять данные, если не проверите результат (поле FailedEntryCount).
Сбой при массовых операциях может происходить чаще, чем при обычных операциях, поскольку отправка большого количества данных может перегрузить систему, что может привести к сбою или ограничению количества записей. Вам следует настроить параметры взаимодействия SDK со службой и работы механизма повтора и отсрочки. Это следует сделать для DynamoDB, где настройки по умолчанию не являются оптимальными, особенно при использовании Lambda. Подробнее об этом можно прочитать здесь.
3. В конечном итоге согласовано
Как уже упоминалось, при использовании архитектуры, управляемой событиями, и особенно базы данных NoSQL (например, DynamoDB), которые, по сути, являются согласованными, в большинстве случаев вы не будете знать, вернет ли база данных самые последние данные. Это задумано в большинстве распределенных систем. Но это противоречит нашей интуиции, особенно при использовании базы данных.
<блок-цитата>DynamoDB в конечном итоге является согласованным, поэтому вы можете не получить только что сохраненные данные.
Вы можете вставить и получить запись и вернуть предыдущую запись. Для операций с первичным индексом или вторым локальным индексом вы можете заставить DynamoDB предоставлять согласованные данные, что в два раза дороже. Но вы не можете этого сделать, когда запрашиваете глобальный второй индекс, который используется чаще. Задержка до синхронизации индекса может быть существенной, если вы вставляете много данных. Самое простое решение — не извлекать данные сразу после вставки, но это может быть неосуществимо. Например, в синхронном процессе пользователь ожидает немедленного ответа. Если вы решите подождать некоторое время, вы не будете знать, насколько долгой должна быть задержка.
4. Фильтр DynamoDB
DynamoDB — одна из наиболее опасных служб, которая может привести к потере данных или получить неожиданные результаты, если вы не знаете, как работает база данных в деталях. Я уже упомянул массовые операции и конечную согласованность. Это более общие проблемы.
Проблемы, связанные с фильтром DynamoDB, уникальны. В DynamoDB есть операция фильтра, которая, как следует из названия, удаляет нежелательные элементы из набора результатов.
<блок-цитата>При использовании фильтра DynamoDB вы можете не получить никаких данных, хотя в базе данных есть соответствующие записи. 😱😱😱
Давайте сначала вспомним, как работает DynamoDB. DynamoDB возвращает 1 МБ данных или количество записей, определенное параметром limit. Затем применяется фильтр. Затем данные отправляются потребителю. Если вы установите ограничение в 10 записей и установите фильтр, DynamoDB получит 10 записей, а затем применит фильтр. Если некоторые или все эти записи не соответствуют критериям фильтра, они не будут возвращены. Это означает, что вы получите менее 10 записей или возможно, ноль, хотя в базе данных могут быть миллионы совпадающих записей. Вы можете проверить LastEvaluatedKey, чтобы узнать, есть ли еще записи, но зачем вам это делать, если ваша интуиция подсказывает вам, что вы получили меньше запрошенных 10 записей? То же самое происходит, даже если вы не используете лимит. DynamoDB извлекает из хранилища 1 МБ данных, применяет фильтр и возвращает результаты, которые снова могут быть пустыми, хотя в базе данных есть соответствующие записи. Это четко указано в документации, но если вы новичок в DynamoDB, это весьма неожиданно.
5. Сообщения очереди недоставленных писем теряются по истечении периода хранения
Шаблон очереди недоставленных писем (DLQ) в управляемых событиями/асинхронных системах используется для удаления сообщений, которые не удалось обработать, чтобы они не были потеряны. Эти сообщения должны быть проверены либо вручную, либо с помощью автоматической системы и возвращены («перенаправлены») в систему, когда проблема будет решена. Но если вы создаете автоматическую систему, не повторяйте все неудачные сообщения, потому что это может вызвать бесконечный цикл, который будет очень дорогостоящим.
Если очередь SQS используется для DLQ, записи в DLQ не сохраняются навсегда. Если вы не обработаете их до истечения срока хранения, они будут потеряны.
<блок-цитата>Сохранение данных в очереди недоставленных писем может не предотвратить потерю данных, если вы забудете отреагировать на тревожное сообщение 🚨.
Первое, что вам следует сделать при настройке DLQ, — это установить для него максимальный период хранения и настроить сигнал тревоги, чтобы вы получали уведомление, если туда удаляются некоторые сообщения. Также не забудьте настроить подписку на сигнализацию, которую довольно легко можно не заметить. Наконец, вам также следует отреагировать на тревожное сообщение, что может оказаться самой проблемной частью, поскольку предполагает вмешательство человека. Невозможность обработки сообщения случается довольно редко, и как только проблема возникает, уведомленное лицо может не ответить, поскольку оно может не знать или не помнить, о чем идет речь. Существует также распространенная проблема с усталостью от оповещений из-за слишком большого количества сообщений, и люди начинают их игнорировать. Это также может случиться с опытными командами.
6. Сообщение о таблетке с ядом также может привести к потере следующих сообщений
Эта проблема возникает при использовании FIFO SQS, FIFO SNS, DynamoDB Streams и Kinesis Streams без настройки DLQ. Что произойдет, если вы столкнетесь с записью, широко известной как сообщение о ядовитой таблетке, которую вы не сможете обработать? Если используется конфигурация по умолчанию, запись будет повторяться бесконечно. Эти службы гарантируют порядок, поэтому никакие другие записи в этой группе FIFO или сегменте/разделе Kinesis/DynamoDB Streams обрабатываться не будут. Но все эти сервисы не хранят данные бесконечно. SQS хранит его по умолчанию в течение 4 дней с возможностью продления до 14 дней, DynamoDB Streams — в течение 1 дня с возможностью продления до 7 дней и Kinesis Streams — в течение 1 дня с возможностью продления до 1 года. Таким образом, если проблема с проблемным сообщением не будет решена к тому времени, вы потеряете все данные старше этого, а не только сообщение о ядовитой таблетке.
<блок-цитата>Сообщение о ядовитой таблетке 💊 может привести к потере всех старых данных в FIFO SQS, FIFO SNS, потоках DynamoDB и потоках Kinesis.
Зная это, вам следует настроить DLQ, в который сообщения будут отправляться после нескольких неудачных попыток. Но вот вторая проблема. Эти сервисы гарантируют порядок, который, конечно, теряется, если некоторые сообщения пропускаются.
7. Отставание при обработке данных
Лямбда, подключенная к SQS, Kinesis Streams и DynamoDB Streams, обрабатывает данные. Что произойдет, если Lambda не сможет справиться с этой задачей, потому что:
* обработка занимает слишком много времени * нижестоящий сервис не может справиться с нагрузкой * низкий зарезервированный параллелизм * низкий максимальный параллелизм (только SQS) * небольшие партии * данные недостаточно параллельно обрабатываются из-за горячих клавиш в DynamoDB * недостаточно или несбалансированы осколки в Kinesis Streams?
В этом случае данные поступают быстрее, чем обрабатываются. Записи в системе устаревают и могут превышать срок хранения (см. раздел о ядовитой таблетке). Тогда вы начнете терять сообщения.
<блок-цитата>Если у вас медленная обработка ⌛, вы можете потерять данные в SQS, Kinesis Streams и DynamoDB Streams, если данные превысят срок хранения.
Вам следует настроить сигнализацию для показателей, которые указывают на то, что необработанные сообщения устаревают:
IteratorAgeдля Lambda присоединяется к потокам Kinesis Streams и DynamoDB Streams.ApproximateAgeOfOldestMessageдля Lambda, прикрепленного к SQSAsyncEventAgeдля Lambdas выполняется асинхронно
8. Регулирование
Когда нагрузка достигает предопределенных котировок/лимитов, система начинает отклонять запросы. Все сервисы AWS имеют множество предопределенных котировок. Некоторые из них мягкие, то есть их можно увеличить, отправив запрос в AWS. В асинхронном процессе, если вы настроите DLQ, Lambda Destination или аналогичный механизм, который система может использовать для хранения отклоненных сообщений, позже вы все равно сможете обрабатывать их, когда решите проблему, или нагрузка снизится. Но в синхронном процессе, например, HTTP-запросы, поступающие к шлюзу API, а затем непосредственно в базу данных, эти запросы теряются, поскольку клиент/пользователь ожидает немедленного ответа. Во-первых, вам следует настроить сигналы тревоги для всех котировок, которые вы, скорее всего, встретите. Невозможно перечислить их все, но первым, что вам придет на ум, должен быть ограничение параллелизма учетной записи Lambda. . В большинстве учетных записей ограничение по умолчанию составляет 1000. Это легко сбить высокой нагрузкой. Вам следует провести нагрузочное тестирование, если вы собираетесь создать службу, рассчитанную на высокую нагрузку.
<блок-цитата>Вам следует провести нагрузочное тестирование, если вы собираетесь создать службу, рассчитанную на высокую нагрузку.
9. Отсутствует/неправильно настроено DLQ и превышено максимальное количество повторов
Без DLQ, когда количество повторных попыток будет исчерпано, вы потеряете сообщение. Каждая служба имеет разные способы и разные параметры настройки повторных попыток. Другая история — правильная настройка DLQ, что само по себе является непростой задачей, и трудно найти лучший пример плохого опыта разработчиков. Давайте идти шаг за шагом. В основном это зависит от режима вызова.
<блок-цитата>Задача дня. Попробуйте правильно настроить очередь недоставленных писем в AWS. 🫣
Асинхронный вызов:
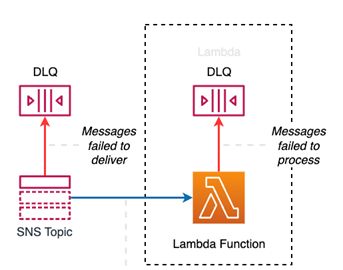
SNS, EventBridge, S3 и многие другие службы асинхронно вызывают Lambda. В этом случае вам необходимо настроить два DLQ:
- DLQ на стороне сервиса (SNS, EventBridge,…) Для SNS и EventBridge только очередь SQS можно настроить как DLQ. В DLQ сообщения удаляются, если службе не удается отправить их цели, а не если цели не удается их обработать. Если целью является Lambda, она пытается доставить во внутреннюю асинхронную очередь Lambda. Вы не увидите много сообщений в этом DLQ. Они попадают сюда только в том случае, если целевая служба не может обработать или у вас недостаточно разрешений. Помимо настройки DLQ, вы также должны обратить внимание на то, как работает механизм повтора. Это не механизм повторных попыток, определяющий, сколько раз будет повторена целевая Lambda! Это конфигурация того, сколько раз он пытается поместить сообщение во внутреннюю очередь Lambda, и почти каждый раз это удается.
2. DLQ на стороне Lambda В этом DLQ сообщения отправляются при сбое вызова Lambda. Это не обязательно должна быть очередь SQS. Это также может быть тема в социальных сетях. Либо его можно заменить или дополнить более новым Lambda Destination, что является лучшим решением, но принцип тот же. Lambda Destination также может отправлять сообщения в случае успеха Lambda, а не только в случае сбоя. Назначение Lambda, помимо SQS, поддерживает отправку сообщений в другие места назначения, такие как функция Lambda, SNS или EventBridge. Кроме того, он предоставляет ранее недоступные сведения об ошибке.
Лямбда вызывается асинхронно:
Назначение лямбды:
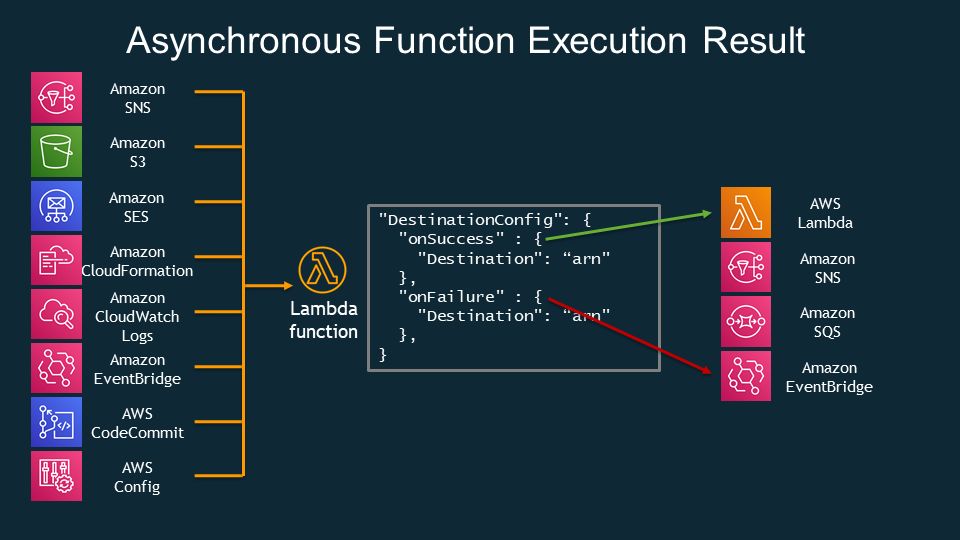
Когда вы самостоятельно выполняете функции Lambda асинхронно, вам также необходимо настроить DLQ/Lambda Destination, но только на стороне Lambda, поскольку ни одна служба не вызывает Lambda.
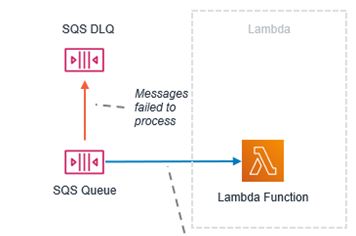
Лямбда, прикрепленная к SQS (вызов опроса):
В этом случае вам следует настроить DLQ только на стороне SQS. DLQ или Lambda Destination на стороне Lambda не будут работать, поскольку Lambda не выполняется асинхронно.
Lambda синхронно опрашивает пакеты сообщений от SQS:
Лямбда, прикрепленная к потокам DynamoDB или Kinesis Streams (вызов опроса):
Эта конфигурация, опять же, совершенно другая. При настройке триггера вы можете настроить DLQ, который может быть очередью SQS или темой SNS. Вы должны настроить только один DLQ, а не два, как в SNS или EventBridge. DLQ не получает сообщение о сбое или какие-либо сведения об ошибке. Вы получаете позицию сообщения, которую можно получить из потока (если срок хранения еще не истек). Настроенный DLQ в консоли AWS также отображается как Lambda Destination, хотя это не асинхронный Lambda Destination, упомянутый выше, а поток Lambda Destination. Назначением может быть только SQS или SNS, но не Lambda или EventBridge. Говоря о полной путанице!
Синхронный вызов
Здесь нет DLQ, поскольку это не асинхронная операция.
Подробнее о реализации шаблонов обработки ошибок AWS Lambda, механизмы повторных попыток и настройка DLQ.
:::информация Также опубликовано здесь.
:::