

Новая безопасная компьютерная технология обрабатывает ИИ, видео и данные без утечки секретов
13 июня 2025 г.Авторы:
(1) Матиас Броссард, Системная группа, исследование ARM;
(2) Гилхем Брайант, Системная группа, исследование ARM;
(3) Basma el Gaabouri, System Group, Arm Research;
(4) Фансин вентилятор, iotex.io;
(5) Александр Феррейра, Системная группа, исследование ARM;
(6) Эдмунд Гримли-Эванс, Системная группа, исследование ARM;
(7) Кристофер Хастер, Системная группа, исследование рук;
(8) Эван Джонсон, Калифорнийский университет, Сан -Диего;
(9) Дерек Миллер, Системная группа, исследование ARM;
(10) Фан Мо, Имперский колледж Лондон;
(11) Доминик П. Маллиган, Системная группа, исследование ARM;
(12) Ник Спинал, системная группа, исследование ARM;
(13) Эрик Ван Хенсберген, Системная группа, Arm Research;
(14) Хьюго Дж. М. Винсент, System Group, Arm Research;
(15) Сланец Xiong, Systems Group, Arm Research.
Примечание редактора: это часть 5 из 6 исследований, в котором подробно описывается разработка структуры, чтобы помочь людям совместно сотрудничать. Прочитайте остальное ниже.
Таблица ссылок
- Аннотация и 1 введение
- 2 конфиденциальные вычисления, поддерживаемые оборудованием
- 3 Icecap
- 4 Веракруз
- 4.1 Аттестация
- 4.2 Модель программирования
- 4.3 Специальное ускорение
- 4.4 Модель угрозы
- 5 Оценка и 5.1 КАССОВАНИЕ: глубокое обучение
5.2 Кейс-исследования: обнаружение видеообъекта
5.3 Дальнейшие сравнения
- 6 Заключительные замечания и ссылки
5 Оценка
В этом разделе используются следующие тестовые платформы: Intel Core I7-8700, 16GIB RAM, 1 ТБ SSD (Core i7, отныне); c5.xlarge aws vm, 8gib ram, ebs (EC2, отныне); Raspberry Pi 4, 4GIB RAM, 32 ГБ мксд (RPI4, отныне). Мы используем GCC 9.30 для X86-64, GCC 7.5.0 для Aarch64 и Wasi SDK-140 с LLVM 13.0 для WASM.
5.1 Кейс-исследования: глубокое обучение
Обучающие наборы данных, алгоритмы и изученные модели могут быть чувствительными IP, а процессы обучения и вывода уязвимы к вредоносным изменениям в параметрах модели, которые могут оказать негативное влияние на поведение модели, которое трудно обнаружить [10, 62]. Мы представляем два приложения для тематического исследования Veracruz в защите глубокого обучения (DL отныне): конфиденциальное обучение и вывод, а также служба агрегации моделей, сохраняющую конфиденциальность, шаг к федеративному DL. Мы используем Darknet [63,78] в обоих случаях, а также обмен открытыми нейронными сетью [11, 26] (Onnx, отныне) в качестве формата агрегации. Мы сосредоточены на времени выполнения обучения, вывода и агрегации модели на тестовой платформе Core i7.
В учебном исследовании обучения и вывода программа получает входные наборы данных от соответствующих поставщиков данных и модель предварительного обучения от поставщика моделей. После этого предварительная программа начинает обучение или вывод, защищенную внутри Веракруза. Результаты, то есть обученная модель или прогноз, доступны для получателя результата. В темно-изучении модельной агрегации клиенты проводят локальное обучение со своими любимыми каркасами DL, конвертируют модели в формат ONNX и предоставляют эти производные модели в Веракрус. Затем программа собирает модели, предоставляя результат всем клиентам. Преобразовавшись в ONNX локально, мы поддерживаем широкий спектр локальных учебных рамок - т. Е., Pytorch [74], Tensorflow [1], Darknet или аналогично.
Мы обучили Lenet [57] на MNIST [57], набор данных рукописных цифр, состоящих из 60 000 тренингов и 10 000 изображений проверки. Каждое изображение составляет 28 × 28 пикселей и менее 1 киб; Мы использовали размеры партии 100 в тренировке, получив обученную модель 186 килограммов. Мы проводим в среднем 20 испытаний для обучения на 100 партии (отсюда 10 000 изображений), а затем выполнили вывод на одном изображении. Для агрегации мы используем три копии этой модели Darknet (186Kib), получая три модели ONNX (26 киб), выполняя 200 испытаний для агрегации, поскольку время агрегации значительно меньше. Результаты представлены на рис. 3.
Для всех задач DL мы наблюдаем одно и то же время выполнения между WasMtime и Veracruz, как и ожидалось, примерно примерно на 2,1–4,1 × медленнее, чем нативное выполнение только CPU, вероятно, из-за более агрессивной оптимизации кода, доступной в родных компиляторах. Тем не менее, сходство между WasMtime и Veracruz расходится на операции с файлами, такие как загрузка и сохранение данных модели. Загрузка данных с диска составляет 1,2–3,1 × медленнее при использовании WASMTime по сравнению с национальным выполнением. Тем не менее, ввод/вывод в Веракрузе обычно быстрее, чем wasmtime, а иногда и быстрее, чем нативное выполнение, например, при сохранении изображений в выводе. Вероятно, это связано с тем, что файловая система Veracruz в памяти, демонстрирующая более быстрое чтение и передачу скорости, по сравнению с SSD тестовой машины.
5.2 Кейс-исследования: обнаружение видеообъекта
Мы использовали Veracruz для прототипа конфиденциальных FAA, работающих на анклавах AWS и используя Kubernetes [53]. В этой модели облачная инфраструктура или другой делегат инициализируют изолят, содержащий только среду выполнения Veracruz, и предоставляет соответствующий файл глобальной политики. Конфиденциальные функции зарегистрированы в конфиденциальных вычислениях в качестве компонента Сервиса (CCFAAS, опадающего), который выступает в качестве реестра для клиентов, желающих использовать эту услугу и который сотрудничает от имени клиентов, с Veracruz в качестве услуг (VAAS, дальше), который управляет жизнью в течение всего срока службы. Вместе, компоненты CCFAAS и VAAS проектируют политики и инициализируют экземпляры Veracruz, в то время как аттестация обрабатывается клиентами, используя услугу аттестации по доверенности.
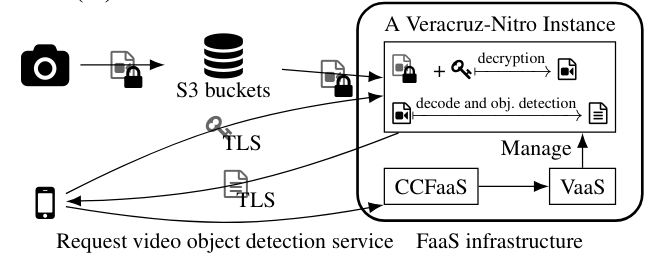
Строившись на этой конфиденциальной инфраструктуре FAAS, мы применили Veracruz в полном сквозном потоке обнаружения видео объекта (см. Рис. 5). Наше намерение состоит в том, чтобы продемонстрировать, что Veracruz может быть применен к религированным промышленным вариантам использования: здесь производитель видеокамеры хочет предложить услугу обнаружения объектов своим клиентам, предоставляя правдоподобные гарантии, что они не могут получить доступ к видео клиента.
Зашифрованные видеоклипы, происходящие из видеокамеры IOTEX UCAM [47], хранятся в ведре AWS S3. Ключ шифрования принадлежит оператору камеры и, возможно, генерируется клиентским программным обеспечением на своем мобильном телефоне или планшете. Независимо от функции обработки видео и обнаружения объектов, скомпилированной для WASM, зарегистрирована в компоненте CCFAAS, который берет на себя роль поставщика программ в вычислении Veracruz. Эта функция использует библиотеку Cisco OpenH264, а также фреймворк Darknet Neural Network и предварительно построенную модель Yolov3, как ранее обсуждалось в §5.1, для обнаружения объекта (наша поддержка в этом портировании).
По просьбе владельца камеры инфраструктура CCFAAS и VAAS порождает новый анклав AWS Nitro, загруженный во время выполнения Veracruz, и настроен с использованием соответствующей глобальной политики, которая перечисляет владельца камеры в качестве роли поставщика данных и получателя результатов. Конфиденциальная инфраструктура FAAS направляет глобальную политику владельцу камеры, где она автоматически анализируется их клиентским программным обеспечением, а владелец камеры подтверждает экземпляр AWS Nitro Anclave. Если глобальная политика является приемлемой, а аттестация добивается успеха, владелец камеры надежно подключается к порожденному изоляту, содержащему время выполнения Верран, и надежно предоставляет их ключ расшифровки, используя TLS в их роли поставщика данных. Зашифрованный видеоклип также предоставляется в изоляте, посредством выделенного приложения AWS S3, которое также указано в глобальной политике в качестве поставщика данных, а затем вычисление может продолжаться. После завершения метаданные, содержащие ограничивающие ящики любого объекта, обнаруженные в рамках видеоклипов, могут быть надежно извлечены владельцем камеры через TLS, в роли их получателя для интерпретации их клиентским программным обеспечением.
Обратите внимание, что в этой инфраструктуре FAAS сохраняются желательная характеристики облачных приложений: вычисление является по требованию и масштабируемой, а наша инфраструктура позволяет выполнять несколько экземпляров Veracruz, выполнять различные функции, выполнять одновременно. Только приложение AWS S3, клиентское приложение владельца камеры и функция декодирования видео и функция обнаружения объектов, специфичны для этого варианта использования. Все остальные модули являются общими, что позволяет реализовать другие приложения. Более того, обратите внимание, что никакие учетные данные или пароли пользователей не передаются непосредственно с инфраструктурой FAAS в реализации этого потока, помимо названия видеоклипа, чтобы получить из ведра AWS S3 и единовременного учетного данных для приложения AWS S3. Ключи дешифрования разделяются только со временем выполнения Веракруза внутри подтвержденного изолята.
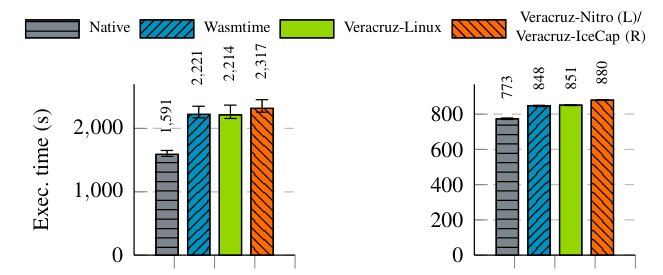
Мы сравниваем, передавая видео 1920 × 1080 в программу обнаружения объектов, которая декодирует рамку по кадру, преобразует, снижается и передает кадры в модель ML. Мы сравниваем четыре конфигурации на двух разных платформах:
• на EC2, родной x86-64 бинар на Amazon Linux; двоичный файл WASM под Wasmtime-0.27; двоичный двоичный веран в VASM как процесс Linux; Бинарный двоичный веран в Веракрузе на ахровых анклавах AWS. Видео имеет длину 240 кадров и подается на модель Yolov3-608 [79].
• на RPI4: нативный бинар Aarch64 на Ubuntu 18.04 Linux; двоичный файл WASM под Wasmtime-0.27; двоичный двоичный веран в VASM как процесс Linux; двоичный двоичный веран в wasm на icecap. Из-за ограничений памяти видео длиной 240 кадров и подается на модель Yolov3-Tiny [79].
Мы принимаем нативную конфигурацию X86-64 в качестве базовой линии и представляем среднее время выполнения для каждой конфигурации, а также наблюдаемые крайности, на рис. 4.

Результаты EC2WASM (с экспериментальной поддержкой SIMD в Wasmtime) имеет накладные расходы на 39% по сравнению с нативным кодом; Большинство циклов процессора потрачены на умножение матрицы, которое нативный компилятор может лучше аутографизировать, чем компилятор WASM. Подавляющее большинство времени выполнения проводится в выводе нейронной сети, а не на видео декодирования или уменьшении изображения. Поскольку во времени исполнения преобладает исполнение WASM, накладные расходы Veracruz незначительны. Между Nitro и Wasmtime существует расхождение на 5% производительности, которое может возникнуть из нашего наблюдения, что NITRO медленнее при загрузке данных в анклав, но быстрее при написании, хотя Nitro запускает другое ядро с другой конфигурацией на отдельном процессоре, что делает это сложно. Накладные расходы на развертывание NITRO представлены в таблице 2, показывающие разбивку накладных расходов для обеспечения нового экземпляра Veracruz.
RPI4 РезультатыМеньшая модель ML значительно улучшает производительность вывода за счет точности. WASM имеет накладные расходы на ~ 10% по сравнению с нативным кодом, меньше, чем разрыв на EC2, и может быть связана с снижением поддержки векторизации в бэкэнде AARCH64 GCC. Накладные расходы Веракруза снова незначительны, хотя ICECAP индуцирует накладные расходы на 3% над Veracruz-Linux. Это наблюдение приблизительно соответствует накладным расходам в размере ~ 2% для рабочих нагрузок, связанных с процессорами, измеренными на рис. 1, объясняется дополнительным переключением контекста через доверенные услуги управления ресурсами во время операций планирования.
Используя «нативные модули», введенные в §4.3, явная поддержка вывода нейронной сети может быть добавлена во время выполнения Veracruz, хотя наши результаты выше предполагают максимум на 38% повышения эффективности эффективности, продолжив это, вероятно, меньше из -за затрат на Marshalling Data между файловой системой Native Module и Veracruz. Для более крупных повышений производительности можно использовать выделенное ускорение ML, требующую поддержки со времен выполнения Veracruz, хотя установление доверия к ускорителям за пределами изолята является сложной, а PCIe Attestation все еще является прогнозом работы.
5.3 Дальнейшие сравнения
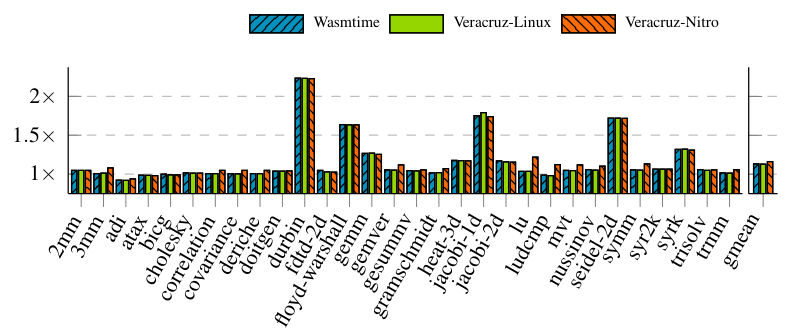
Polybench/C MicrobenchmarksДалее мы оцениваем производительность Veracruz на программах вычислительных переписей с использованием набора Polybench/C (версия 4.2.1-бета) [75], набора небольших, простых вычислительно интенсивных ядер. Мы сравниваем время выполнения четырех различных конфигураций в экземпляре EC2, использующего Amazon Linux 2: Нативный двоичный файл X86-64; двоичный файл WASM под Wasmtime-0.27; двоичный файл WASM при Veracruz как процесс Linux; и бинарный исполнение WASM под руководством Веракруза в анклаве AWS. Мы принимаем x86-64 в качестве базовой линии и представляем результаты на рис. 6. Накладные расходы Wasmtime против нативного выполнения ЦП относительно невелики со средним геометрическим средством ~ 13%, хотя мы наблюдаем, что некоторые программы тестирования выполняются еще быстрее под WasMtime, чем при национальном составлении. Опять же, мы составляем наши тестовые программы с экспериментальной поддержкой Wasmtime для предложения SIMD, хотя это повышает производительность только для нескольких программ. Veracruz-Linux не демонстрирует видимые накладные расходы по сравнению с Wasmtime, который ожидается, так как большинство времени исполнения тратится в Wasmtime, а наличие VFS Veracruz в значительной степени не имеет отношения к программам, связанным с процессорами. Веракруцнитро демонстрирует небольшие, но заметные накладные расходы (~ 3%) по сравнению с Veracruz-Linux, вероятно, по причинам, упомянутым в §5.2.
VFS PerformanceМы оцениваем эффективность ввода/вывода Veracruz VFS, ранее обсуждавшейся в §4.2. Производительность измеряется путем времени общих гранулированных операций с файловой системой и деления на входные размеры, чтобы найти ожидаемую пропускную способность.
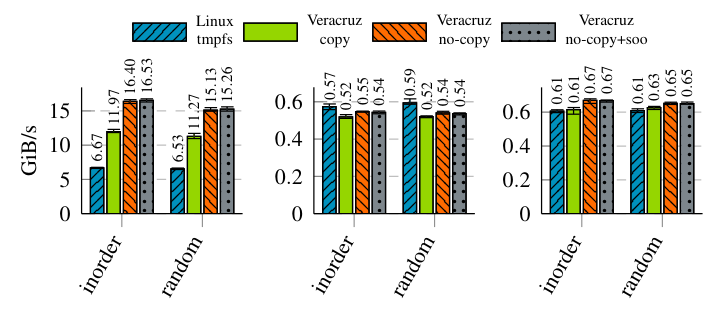
Результаты, собранные на тестовой платформе Core i7 с нулевым размером, так что измерения не будут признаны недействительными путем доступа к физическому диску, представлены на рис. 7. Здесь чтение обозначает полосу пропускания операций с чтением файла, записи обозначает полосу пропускной способности операций записи файла без первоначального файла и обновление обозначает пропускную сторону операций файла с существующим файлом. Мы используем два шаблона доступа, по порядку и случайные, чтобы избежать измерения только схемы доступа, удобных для файлов. Все случайные входы, как для данных, так и для шаблонов доступа, использовались воспроизводимые, псевдорандомические данные, сгенерированные Xorshift64 для обеспечения согласованности между прогонами. Все операции манипулируют файлом 64 мБИБ с размером буфера 16 киб. На практике мы ожидаем, что большинство файлов будет в порядке такого размера.
Мы сравниваем вариации наших VFS с TMPFS Linux, стандартной файловой системы в памяти для Linux. Копия Veracruz перемещает данные между песочницей WASM и VFS через две копии, одна на слое API WASI, а одна на внутреннем слое API VFS. Veracruz No-Copy улучшилась на этом, выполнив одну копию непосредственно из песочной памяти WASM в пункт назначения в VFS. Это стало возможным благодаря проверке заемных займов Руста, которая может выразить временно общее владение песочницей памяти WASM, не жертвуя памятью или безопасностью жизни. Теоретически эти накладные расходы могут быть уменьшены до нуля копий через MEMMAP, однако этот API не доступен в стандартном WASI. Veracruz no-Copy+SOO-это наша последняя конструкция, расширяющая реализацию No-Copy с помощью малой оптимизации (SOO) IOVEC-структура WASI, описывающая набор буферов, содержащих данные, которые для большинства операций содержат ссылку на один буфер. Благодаря этому мы внедряем два или меньше буферов в саму структуру IOVEC, полностью удаляя распределения памяти из пути чтения и записи для всех программ, с которыми мы протестировали. Однако воздействие на производительность незначительна.
Находясь в файловой системе памяти, внутреннее представление относительно просто: каталоги и глобальная таблица INODE реализованы с использованием хэш-таблиц, причем каждый файл представлен как вектор байтов. Хотя это, по-видимому, наивное, эти данные Datastructurs наблюдают десятилетия оптимизации для производительности в памяти, и даже разреженные файлы работают эффективно из-за переполнения оперативной памяти The Trunttime. Тем не менее, мы все еще были удивлены, увидев очень близкую производительность между Veracruz и TMPFS, причем Veracruz почти удвоил производительность TMPFS для чтения, вероятно, из -за накладных расходов ядра, необходимых для связи с TMPF в Linux. (К сожалению, TMPFS глубоко интегрируется в слой Linux VFS, поэтому невозможно сравнивать с TMPFS в изоляции.)
Как Veracruz, так и TMPFS используют хэш-таблицы для хранения информации о каталоге, при этом структура данных файла и распределитель памяти представляют существенные различия. В Veracruz мы используем байтовые векторы, подкрепленные выдвижением общего назначения среды выполнения, тогда как TMPFS использует дерево страниц, поддерживаемое Linux
Кэш страниц VFS, который действует как распределитель с фиксированным размером с ограниченным размером. Мы ожидаем, что этот кэш страницы будет иметь гораздо более дешевую стоимость распределения, в недостатке хранения данных файлов в нелинейных блоках памяти-подлежит подлежащему разницу между измерениями записи и обновлений. Для записи TMPFS превосходит Veracruz из -за более быстрого распределения памяти и без ненужных копий, в то время как обновление не требует распределения памяти и имеет более сопоставимую производительность.
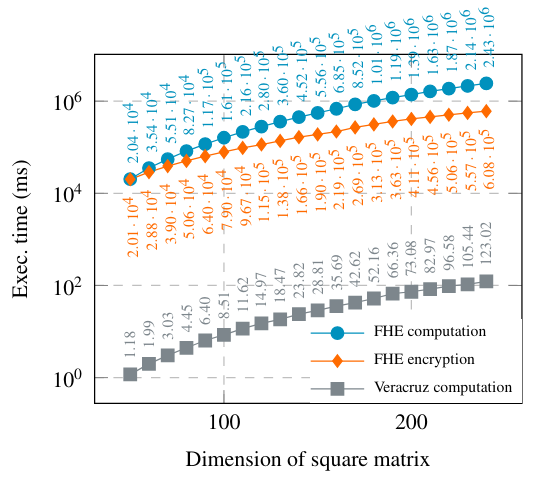
Полностью гомоморфное шифрованиеЧасто упомянутая в использовании для полностью гомоморфного шифрования (FHE, SENCEFOTH) защищает делегированные вычисления. Мы кратко сравниваем Veracruz с Seal [61], ведущей библиотеки Fhe, в расчете ряд умножения матрицы по квадратным матрицам различных измерений. Алгоритмы в обоих случаях записаны в C, хотя арифметика с плавающей запятой заменяется функцией умножения уплотнения для использования с Fhe. Результаты представлены на рис. 8. Наши результаты показывают, что накладные расходы за Fhe нецелесообразны даже для простых вычислений.
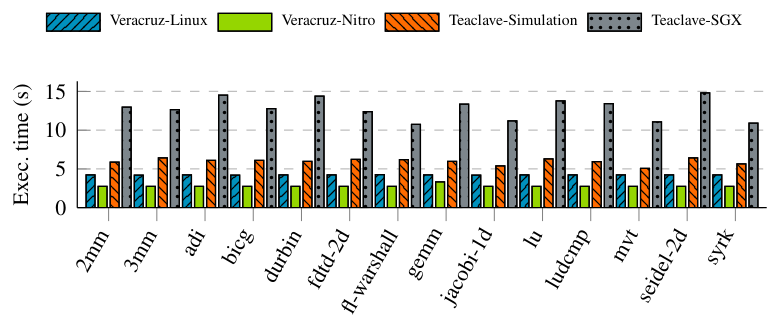
ЧайклавApache Teaclave [33]-это инфраструктура FAAS, сохраняющую конфиденциальность, построенную на Intel SGX, поддерживающую Python и WASM с пользовательской моделью программирования с использованием интерпретатора WAMR [3]. Мы сравниваем производительность чайкала, работающего в разделе Intel SGX с Veracruz как процесс Linux, как на Core i7, так и на VeraRuz на анклавах AWS на EC2 - выдвинуто несовершенное сравнение из -за значительных различий в дизайне, технологии выделения, WASM Runting и Herpware между двумя. Мы запускаем набор Polybench/C с его мини-набором данных-ошибки конфигурации TeaClave по умолчанию для более крупных наборов данных-и измеряйте сквозное время выполнения, которое включает в себя инициализацию, обеспечение, выполнение и получение результатов, которые мы представляем на рис. В режиме симуляции, и быстрее, чем теалав в SGX - фиксированные начальные накладные расходы Veracruz, ∼4s в Linux и ∼2,7s в AWS Nitro, доминирует в общем накладном расходе в любом случае.
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27399)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Социальные медиа и интернет-культура (107)
- Экономика и финансы (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)