
Новая модель искусственного интеллекта показывает устойчивость на фоне разреженных облачных данных точек
17 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
Связанная работа
Метод
3.1 Обзор нашего метода
3.2 грубое извлечение текстовых клеток
3.3 Оценка прекрасной позиции
3.4 Цели обучения
Эксперименты
4.1 Описание набора данных и 4.2 Подробная информация
4.3 Критерии оценки и 4.4 результаты
Анализ производительности
5.1 Исследование абляции
5.2 Качественный анализ
5.3 Анализ встраивания текста
Заключение и ссылки
Дополнительный материал
- Подробная информация о наборе данных Kitti360
- Больше экспериментов по экстрактору запроса экземпляра
- Анализ космического пространства текстовых клеток
- Больше результатов визуализации
- Анализ устойчивости точек
Анонимные авторы
- Подробная информация о наборе данных Kitti360
- Больше экспериментов по экстрактору запроса экземпляра
- Анализ космического пространства текстовых клеток
- Больше результатов визуализации
- Анализ устойчивости точек
Еще 4 результаты визуализации
На рис. 3 показано больше результатов визуализации, включая как результаты поиска, так и результаты оценки тонкой позиции. Результаты показывают, что грубый поиск текстовых клеток служит основополагающим шагом в общем процессе локализации. Последующая оценка тонкой позиции обычно улучшает производительность локализации. Тем не менее, есть случаи, когда точность этой прекрасной оценки подвергается нарушению, особенно когда входные описания расплывчаты. Этот вредный эффект на точность иллюстрируется в 4-я ряд и 6-й строке, если рис. 3.

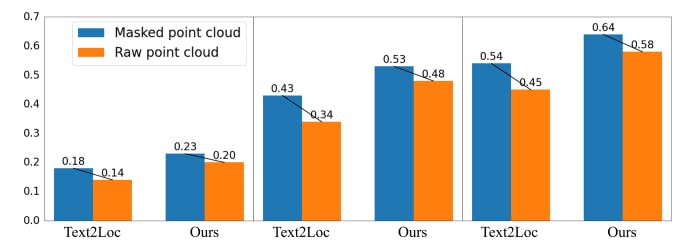
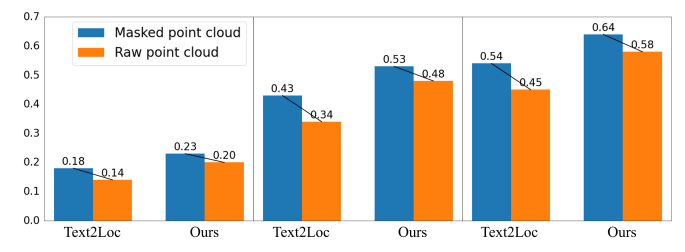
Анализ устойчивости облака 5 очков
Предыдущие работы [? ? ? ] сосредоточен исключительно на изучении влияния текстовых модификаций на точность локализации, игнорируя влияние модификации точечных облаков. В этом исследовании мы также рассмотрим влияние деградации облака точек, что имеет решающее значение для полного анализа нашей модели IFRP-T2P. В отличие от накопленных точечных облаков, представленных в наборе данных Kitti360, датчики LIDAR обычно отражают только редкие облака точек в реальных настройках. Чтобы оценить надежность нашей модели в условиях редкости в облаке точечных, мы проводим эксперименты, случайно маскируя одну треть точек и сравниваем эти результаты с результатами с результатами, полученными с использованием необработанных облаков точек. Как показано на рис. 4, при приеме облака точек маскированных точек в качестве входного ввода наша модель IFRP-T2P достигает отзывов локализации 0,20 в TOP-1 с границей ошибки 𝜖 <5𝑚 в наборе валидации. По сравнению с Text2loc, который показывает деградацию 22,2%, наша модель демонстрирует более низкий уровень деградации в 15%. Этот результат указывает на то, что наша модель более устойчива к вариации облака точек.
Авторы:
(1) Lichao Wang, FNII, Cuhksz (wanglichao1999@outlook.com);
(2) Zhihao Yuan, FNII и SSE, Cuhksz (zhihaoyuan@link.cuhk.edu.cn);
(3) Jinke Ren, FNII и SSE, Cuhksz (jinkeren@cuhk.edu.cn);
(4) Shuguang Cui, SSE и FNII, Cuhksz (shuguangcui@cuhk.edu.cn);
(5) Чжэнь Ли, автор -соответствующий автор из SSE и FNII, Cuhksz (lizhen@cuhk.edu.cn).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)