В первой части этой серии из двух частей мы рассмотрим, как неоптимальные модели внедрения, неэффективные стратегии фрагментирования и отсутствие фильтрации метаданных могут затруднить получение релевантных ответов от вашего LLM. Вот как можно преодолеть эти проблемы.
Создание генеративных приложений искусственного интеллекта, использующих дополненную генерацию извлечения (RAG ) может создать множество проблем. Давайте рассмотрим устранение неполадок в реализациях RAG, которые используют векторные базы данных для извлечения соответствующего контекста, который затем включается в приглашение к большой языковой модели для получения более релевантных результатов.
Мы разобьем этот процесс на две основные части. Первое, о чем мы поговорим в этой первой статье серии, — это конвейер внедрения, который заполняет база данных векторов с встраиваниями:
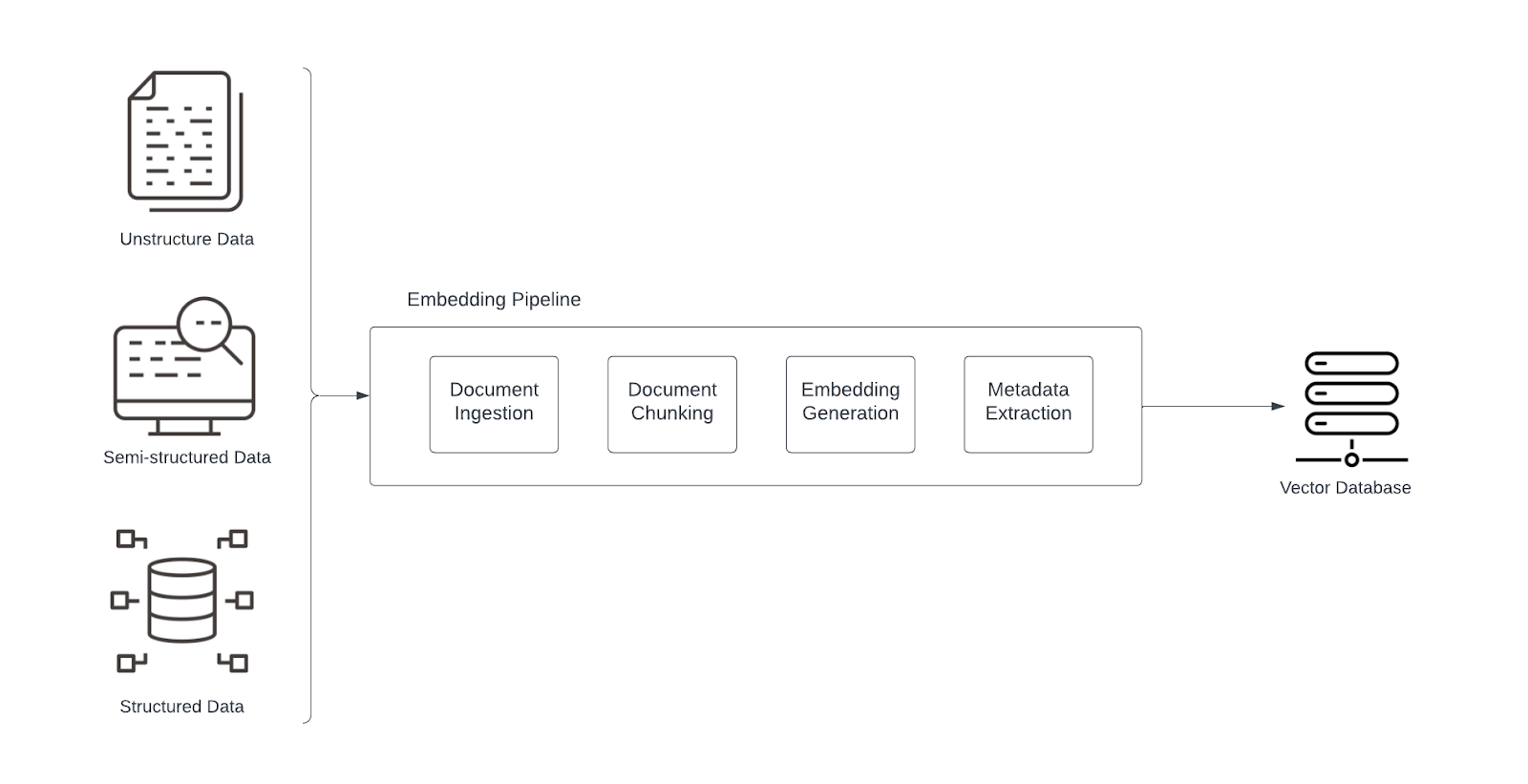
Здесь мы рассмотрим три основные области, которые могут привести к плохим результатам: неоптимальные модели внедрения, неэффективные стратегии фрагментации и отсутствие фильтрации метаданных. (В следующей статье мы рассмотрим фактическое взаимодействие с LLM и рассмотрим некоторые распространенные проблемы, которые возникают там и могут привести к плохим результатам.)
Выбор подходящей модели внедрения
Выбор модели внедрения окажет существенное влияние на общую актуальность и удобство использования вашего приложения RAG. Таким образом, требуется детальное понимание возможностей каждой модели и анализ того, насколько эти возможности соответствуют требованиям вашего приложения.
Если вы новичок в RAG и встраиваниях в целом, вам следует знать один из лучших ресурсов — MTEB ( Massive Text Embedding Benchmark) встраивание таблицы лидеров. В этой статье мы сосредоточимся на вариантах использования извлечения, но встраивания, конечно, можно использовать для многих других приложений, включая классификацию, кластеризацию и суммирование.
Таблица лидеров поможет вам определить модели, которые лучше всего подходят для вашего конкретного случая использования.
Одна из наиболее распространенных причин плохой производительности RAG заключается в том, что разработчики, впервые работающие в этой области, выполняют поиск в Google, чтобы найти примеры встроенной генерации. Они часто обнаруживают образцы, в которых используются модели внедрения, такие как Word2Vec, sBERT и RoBERTa, которые являются плохим выбором для случаев использования поиска.
Если вы нашли эту статью, потому что занимаетесь отладкой плохих результатов релевантности и использовали что-то вроде sBERT для создания вложений, то мы, вероятно, определили причину ваших проблем с релевантностью.
Если да, то следующий вопрос, который у вас, скорее всего, возникнет, — какие модели внедрения вы можете использовать для улучшения результатов поиска по сходству. Не зная особенностей вашего варианта использования, мы бы порекомендовали следующие три:
text-embedding-ada-002 (Ada v2)
Ada v2 от OpenAI, вероятно, является наиболее распространенным вариантом запуска. для большинства приложений RAG просто потому, что многие разработчики начинают с API Open AI. Ada v2 превосходно работает при поиске данных и была создана для обработки различных типов контента, включая текст и код.
Благодаря максимальной длине входной последовательности до 8192 токенов он также позволяет создавать вложения для гораздо более длинных фрагментов текста, чем альтернативные модели. Это одновременно благословение и проклятие.
Большой размер последовательности упрощает процесс создания вложений для большей части вашего текстового контента, а также позволяет модели внедрения выявлять связи между словами и предложениями в большем объеме текста.
Однако это также приводит к поиску по сходству, который может стать более нечетким при сравнении сходства двух длинных документов, когда вы ищете релевантные фрагменты контекста для облегчения процесса генерации.
У Ada v2 есть два больших недостатка. Во-первых, его нельзя запустить локально. Для создания встраивания необходимо использовать API OpenAI. Это может не только создать узкие места в случаях, когда вы хотите создать встраивания для многих фрагментов контента, но также добавить стоимость в размере 0,0001 доллара США за 1000 токенов.
Во-вторых, каждое из внедрений, созданных на основе модели Open AI, имеет 1536 измерений. Если вы используете облачную базу данных векторов, это может значительно увеличить затраты на хранение векторов.
Когда выбирать. Вам нужно простое решение, требующее только вызова API, вам потенциально потребуется векторизовать большие документы, и стоимость не является проблемой.
jina-embeddings-v2 (Jina v2)
Jina v2 – это новая модель внедрения с открытым исходным кодом, которая обеспечивает ту же поддержку 8 000 входных последовательностей, что и Ada v2, и на самом деле показывает немного лучшие результаты при извлечении данных.
Jina v2 предоставляет противоядие от проблем Ada v2. Это с открытым исходным кодом под лицензией Apache 2.0 и может запускаться локально, что, конечно, также является недостатком, если вы не хотите запускать для этого собственный код. Он также создает вектор внедрения с половиной размеров Ada v2.
Таким образом, вы не только получаете немного лучшую производительность поиска в тестовых сценариях использования, но также получаете улучшенные результаты при меньших требованиях к памяти и вычислениям с точки зрения векторной базы данных.
Когда выбирать. Вы хотите использовать решение с открытым исходным кодом и потенциально нуждаетесь в векторизации больших документов, а также вам удобно запускать конвейеры внедрения локально. Вы хотите снизить затраты на векторную базу данных за счет встраивания меньшей размерности.
bge-large-en-v1.5
bge-large-en-v1.5 находится в открытом доступе под лицензией MIT. и в настоящее время является лидирующей моделью встраивания в таблице лидеров MTEB для сценариев использования поиска. Благодаря меньшей входной последовательности вам потребуется больше внимания уделять стратегии разбиения на фрагменты, но в конечном итоге это обеспечит наилучшую общую производительность для вариантов использования извлечения данных.
Когда выбирать: вы хотите использовать решение с открытым исходным кодом и готовы тратить больше времени на стратегии фрагментирования, чтобы не выходить за пределы ограничений размера входных данных. Вам удобно запускать встраиваемые конвейеры локально. Вам нужна наиболее эффективная модель внедрения для вариантов использования поиска.
Хотя это выходит за рамки этой статьи, вы, возможно, захотите углубиться в 15 тестов в таблице лидеров MTEB, чтобы определить тот, который наиболее близко соответствует вашей конкретной ситуации.
Хотя определенно существуют закономерности в том, насколько хорошо различные модели внедрения работают в разных тестах, часто в каждом из них есть конкретные модели, которые выделяются. Если вам необходимо уточнить выбор встраивания, это возможная область дальнейшего изучения.
Оптимизация стратегии разделения
Сегментация или «разбивка» входного текста является ключевым фактором, который существенно влияет на релевантность и точность создаваемых результатов. Различные стратегии фрагментации предлагают уникальные преимущества и подходят для конкретных типов задач. Здесь мы углубимся в эти методологии и дадим рекомендации по их применению, учитывая некоторые ключевые моменты:
В качестве общего подхода, прежде чем пытаться разбить большой корпус и векторизовать его, вам следует подумать о проведении некоторых специальных экспериментов с вашими данными.
Вручную проверьте документы, которые вы хотели бы получить по заданному запросу, определите фрагменты, которые представляют идеальный контекст, который вы хотели бы предоставить LLM, а затем поэкспериментируйте со стратегиями фрагментирования, чтобы увидеть, какой из них дает вам фрагменты, которые, по вашему мнению, будут наиболее релевантными. для LLM.
Рассмотрение контекстного окна
Доступное контекстное окно LLM является важным фактором при выборе стратегии разбиения на фрагменты. Если контекстное окно маленькое, вам придется более избирательно подходить к фрагментам, которые вы вводите в модель, чтобы обеспечить включение наиболее актуальной информации.
И наоборот, большее контекстное окно обеспечивает большую гибкость, позволяя включать дополнительный контекст, который может улучшить результаты модели, даже если не все из них строго необходимы.
Экспериментируя с этими стратегиями разбиения на блоки и принимая во внимание эти соображения, вы можете оценить их влияние на релевантность сгенерированных результатов. Ключевым моментом является согласование выбранной стратегии с конкретными требованиями вашего приложения RAG, сохранение семантической целостности входных данных и обеспечение всестороннего понимания контекста.
Это позволит вам найти правильный процесс разбиения на блоки для достижения оптимальной производительности.
Фильтрация метаданных
Поскольку количество вложений в ваш поисковый индекс растет, приблизительные ближайшие соседи (ANN) становятся менее полезными при поиске соответствующего контекста для включения в ваши подсказки. Допустим, вы проиндексировали встраивания для 200 статей в своей базе знаний.
Если вы сможете определить верхнего ближайшего соседа с точностью 1 %, вы, скорее всего, получите весьма релевантные результаты, поскольку 1 % соответствует двум лучшим статьям из этих 200, и вы получите одну из этих двух.
Теперь рассмотрим поисковый индекс, содержащий все статьи в Википедии. Это составит примерно 6,7 миллиона статей. Если ваш ближайший сосед входит в топ-1% большинства похожих статей, это означает, что вы получаете одну из 67 000 наиболее похожих статей.
С таким корпусом, как Википедия, это означает, что вы все равно можете оказаться очень далекими от цели.
Фильтрация метаданных дает вам возможность сузить фрагменты контента, сначала фильтруя документы, а затем применяя алгоритм ближайшего соседа. В случаях, когда вы имеете дело с большим количеством возможных совпадений, эта первоначальная предварительная фильтрация может помочь вам сузить возможные варианты перед получением ближайших соседей.
Далее мы углубимся во взаимодействие с LLM и рассмотрим некоторые распространенные проблемы, которые могут привести к плохим результатам.
Попробуйте DataStax Astra DB, единственную векторную базу данных для построения производственного уровня. Приложения искусственного интеллекта для обработки данных в реальном времени.
Крис Латимер, DataStax
Также опубликовано здесь