

Предсказание с несколькими точками: масштабы производительности с размером LLM
7 июня 2025 г.Таблица ссылок
Аннотация и 1. Введение
2. Метод
3. Эксперименты по реальным данным
3.1. Шкала преимуществ с размером модели и 3,2. Более быстрый вывод
3.3. Изучение глобальных моделей с помощью мульти-байтового прогноза и 3.4. Поиск оптимальногоне
3.5. Обучение для нескольких эпох и 3.6. Создание нескольких предикторов
3.7 Многократный прогноз на естественном языке
4. Абляции на синтетических данных и 4.1. Индукционная способность
4.2. Алгоритмические рассуждения
5. Почему это работает? Некоторые спекуляции и 5.1. Lookahead Укрепляет очки выбора
5.2. Информация теоретичный аргумент
6. Связанная работа
7. Заключение, Заявление о воздействии, воздействие на окружающую среду, подтверждения и ссылки
A. Дополнительные результаты по самопрокативному декодированию
Б. Альтернативные архитектуры
C. Скорость тренировок
D. МАГАЗИН
E. Дополнительные результаты по поведению масштабирования модели
F. Подробности о CodeContests Manetuning
G. Дополнительные результаты по сравнению с естественным языком
H. Дополнительные результаты по абстрактному текстовому суммированию
I. Дополнительные результаты по математическим рассуждениям на естественном языке
J. Дополнительные результаты по индукционному обучению
K. Дополнительные результаты по алгоритмическим рассуждениям
L. Дополнительные интуиции по многоцелевым прогнозам
М. Обучение гиперпараметры
3.1. Шкала преимуществ с размером модели
Чтобы изучить это явление, мы обучаем модели из шести размеров в параметрах диапазона от 300 до 13B с нуля на по меньшей мере 91B токенах кода. Оценка приводит на рисунке 3 для MBPP (Austin et al., 2021) и Humaneval (Chen et al., 2021), показывают, что возможно, с точно таким же вычислительным бюджетом, чтобы выжать гораздо большую производительность из крупных языковых моделей, полученных с фиксированным набором данных с использованием многоканутного прогнозирования.
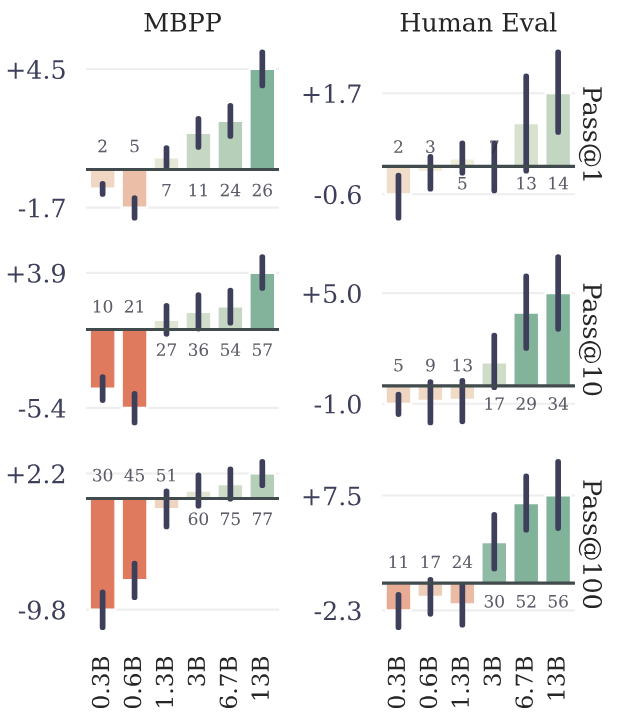
Мы считаем, что эта полезность только в масштабе является вероятной причиной, по которой предсказание с несколькими точками до сих пор в значительной степени упускается из виду как многообещающую потерю обучения для больших языковых модели.
3.2. Более быстрый вывод
Мы внедряем жадное самопрокативное декодирование (Stern et al., 2018) с гетерогенными размерами партий с использованием Xformers (Lefaudeux et al., 2022) и измеряем скорости декодирования нашей лучшей модели 4-х покновение с параметрами 7B при завершении промота Мы наблюдаем ускорение 3,0 × код в среднем 2,5 принятых токена из 3 предложений по коду и 2,7 × на текст. На 8-байтовой модели прогнозирования ускорение вывода составляет 6,4 × (таблица S3). Предварительная подготовка с помощью многократного прогноза позволяет дополнительным головкам быть гораздо более точными, чем простое создание модели предсказания следующей точки, что позволяет нашим моделям разблокировать полный потенциал самопроизвольного декодирования.
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
Авторы:
(1) Фабиан Глокл, ярмарка в Meta, Cermics Ecole des Ponts Paristech и внес свой вклад;
(2) Badr Youbi Idrissifair в Meta, Lisn Université Paris-Saclay и внес свой вклад;
(3) Baptiste Rozière, ярмарка в Meta;
(4) Дэвид Лопес-Паз, ярмарка в Мете и его последний автор;
(5) Габриэль Синнев, ярмарка в Meta и последний автор.
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27360)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)