

Предсказание с несколькими точками: более высокая эффективность выборки для крупных языковых моделей
4 июня 2025 г.Таблица ссылок
Аннотация и 1. Введение
2. Метод
3. Эксперименты по реальным данным
3.1. Шкала преимуществ с размером модели и 3,2. Более быстрый вывод
3.3. Изучение глобальных моделей с помощью мульти-байтового прогноза и 3.4. Поиск оптимальногоне
3.5. Обучение для нескольких эпох и 3.6. Создание нескольких предикторов
3.7 Многократный прогноз на естественном языке
4. Абляции на синтетических данных и 4.1. Индукционная способность
4.2. Алгоритмические рассуждения
5. Почему это работает? Некоторые спекуляции и 5.1. Lookahead Укрепляет очки выбора
5.2. Информация теоретичный аргумент
6. Связанная работа
7. Заключение, Заявление о воздействии, воздействие на окружающую среду, подтверждения и ссылки
A. Дополнительные результаты по самопрокативному декодированию
Б. Альтернативные архитектуры
C. Скорость тренировок
D. МАГАЗИН
E. Дополнительные результаты по поведению масштабирования модели
F. Подробности о CodeContests Manetuning
G. Дополнительные результаты по сравнению с естественным языком
H. Дополнительные результаты по абстрактному текстовому суммированию
I. Дополнительные результаты по математическим рассуждениям на естественном языке
J. Дополнительные результаты по индукционному обучению
K. Дополнительные результаты по алгоритмическим рассуждениям
L. Дополнительные интуиции по многоцелевым прогнозам
М. Обучение гиперпараметры
Абстрактный
Крупные языковые модели, такие как GPT и Llama, обучаются с потерей предсказания следующей точки. В этой работе мы предполагаем, что модели обучения языку для прогнозирования нескольких будущих токенов одновременно приводят к более высокой эффективности выборки. Более конкретно, на каждой позиции в учебном корпусе мы просим модель предсказать следующие N -токены с использованием N независимых выходных головок, работающих поверх общей стволы модели. Принимая во внимание многократное прогнозирование как задачу вспомогательного обучения, мы измеряем улучшенные возможности вниз по течению без накладных расходов во время обучения как для моделей кода, так и для естественного языка. Метод становится все более полезным для больших размеров модели и поддерживает его привлекательность при обучении для нескольких эпох. Прибыль особенно выражена на генеративных критериях, таких как кодирование, где наши модели последовательно превосходят сильные базовые показатели на несколько процентных точек. Наши модели параметров 13B решают на 12 % больше проблем на Humaneval и на 17 % больше на MBPP, чем сопоставимые модели следующего тока. Эксперименты по небольшим алгоритмическим задачам демонстрируют, что многократный прогноз является благоприятным для разработки индукционных руководителей и алгоритмических возможностей рассуждений. В качестве дополнительного преимущества, модели, обученные 4-то-токшн-прогнозированию, на 3 раза быстрее при выводе, даже с большими размерами партии.
1. Введение
Человечество сжало свои самые гениальные начинания, удивительные результаты и красивые постановки в текст. Большие языковые модели (LLMS), обученные всем этим корпусам, способны извлекать впечатляющие объемы мировых знаний, а также базовые возможности рассуждений, внедряя простую, но и мощную-несущественную учебную задачу: предсказание следующего token. Несмотря на недавнюю волну впечатляющих достижений (Openai, 2023), следующий докененный предварительный вклад +Последние авторы 1 ярмарка в Meta 2cermics Ecole des Ponts Paristech 3lisn Université Paris-Saclay. Переписка: Фабиан Глокл, Бадр Юби Идрисси. Дикция остается неэффективным способом приобретения языка, мировых знаний и рассуждений. Точнее, учитель, навязывающий следующим ток-прогнозированию, зафиксирует локальные модели и упускает из виду «жесткие» решения. Следовательно, остается фактом, что современные предикторы следующего ток призывают к порядкам большего количества данных, чем человеческие дети, чтобы достичь того же уровня беглости (Frank, 2023).
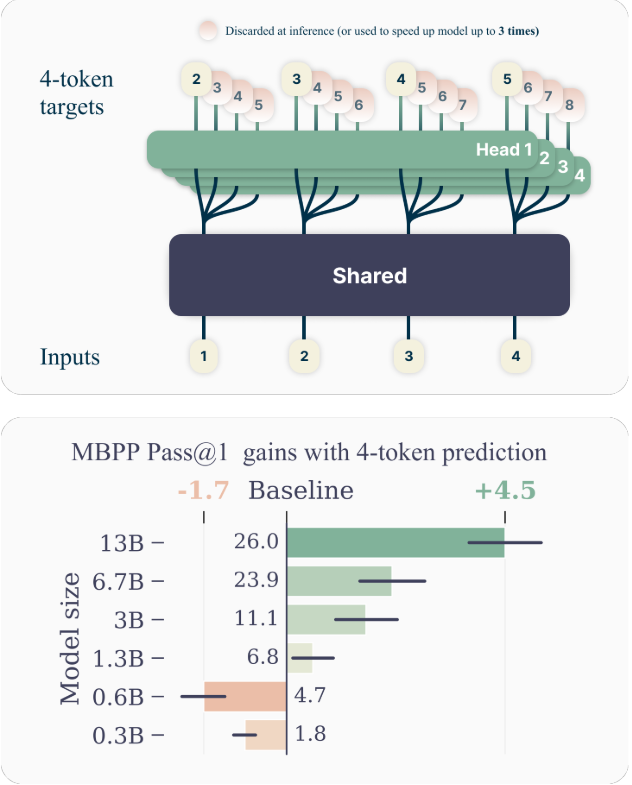
В этом исследовании мы утверждаем, что обучение LLM для прогнозирования нескольких токенов одновременно приведет эти модели к повышению эффективности выборки. Как и предполагалось на рисунке 1, многоцветный прогноз инструктирует LLM предсказать N N Future токены с каждой позиции в учебной корпорации, все сразу и параллельно (Qi et al., 2020).
ВкладХотя предсказание мульти-токного было изучено в предыдущей литературе (Qi et al., 2020), настоящая работа предлагает следующий вклад:
Мы предлагаем простую архитектуру предсказания с несколькими точками без времени поезда или накладных расходов на память (раздел 2).
Мы предоставляем экспериментальные доказательства того, что эта тренировочная парадигма полезна в масштабе, с моделями до 13b параметры решают в среднем на 15% больше проблем с кодом (раздел 3).
Предсказание с несколькими точками позволяет самопрокативному декодированию, создавая модели в 3 раза быстрее при времени вывода в широком диапазоне размеров партии (раздел 3.2).
Несмотря на то, что предсказание Multi-Token-это эффективная модификация для обучения более сильных и более быстрых моделей трансформаторов. Мы надеемся, что наша работа ставит интерес к новым вспомогательным потерям для LLMS далеко за пределы следующего прогноза, чтобы улучшить способность, когерентность и способности этих увлекательных моделей.
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
Авторы:
(1) Фабиан Глокл, ярмарка в Meta, Cermics Ecole des Ponts Paristech и внес свой вклад;
(2) Badr Youbi Idrissifair в Meta, Lisn Université Paris-Saclay и внес свой вклад;
(3) Baptiste Rozière, ярмарка в Meta;
(4) Дэвид Лопес-Паз, ярмарка в Мете и его последний автор;
(5) Габриэль Синнев, ярмарка в Meta и последний автор.
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
4 признака того, что ваш Instagram взломали (и что делать)
16 ноября 2022 г. -
Предстоящие эксклюзивы для PS5 — график выхода подтвержденных игр
24 октября 2023 г. -
Как подключить беспроводную клавиатуру Apple к Windows 10
18 апреля 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
Categories
- Технологии и IT (25564)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (271)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)
