Привет! Меня зовут Николай Хечумов, и я являюсь участником Avito. Группа безопасности приложений. Мы создаем и поддерживаем нашу платформу AppSec — набор общекорпоративных инструментов и процессов, в том числе:
* Система сканирования кода с предварительным/послеполученным получением и проверкой PR с автоматическим отслеживанием уязвимостей и управлением ими; * Гибкие шаблоны моделирования угроз для специализированных групп; * Полноценная программа для защитников безопасности
Обо всем этом мы расскажем в наших следующих статьях. Оставайтесь с нами!
Сегодня я хочу поделиться некоторыми новыми подходами к секретному поиску на уровне сканера.
Что такое секреты и зачем их искать?
Секрет — это общее название любой конфиденциальной информации, которая может понадобиться вашему приложению для внутреннего использования. Например, это могут быть учетные данные для баз данных, внешних систем, приватные ключи, пароли для учетных записей служб и т. д. Эти данные не должны храниться внутри исходного кода, даже если у вас есть собственная VCS.
Вместо этого правильный способ обращения с секретами — хранить их в специальной системе, такой как Hashicorp Vault. Затем секреты вашего приложения должны быть доставлены в контейнер приложения.
Также должны быть программы повышения осведомленности о безопасности и программы обучения для разработчиков. Тем не менее, всегда есть вероятность ошибки: люди склонны делиться секретами (намеренно или нет), независимо от того, насколько хорошо вы их учите. Таким образом, любой AppSec< /a> команда должна сканировать старый и новый код на наличие секретов внутри него.
Существующие инструменты и корень их проблем
Безусловно, специалисты по безопасности знакомы с такими инструментами, как trufflehog или gitsecrets. Они хорошо находят «типизированные секреты» — те, которые имеют узнаваемый формат. и могут быть найдены с помощью основных регулярных выражений. Например, секреты Slack начинаются с xoxb.., криптографические ключи имеют такие последовательности заголовков, как ===== BEGIN PRIVATE ===== и т. д.
У нас на Авито много внутренних и внешних секретов без какого-либо узнаваемого формата.
Как их найти? Клод Шеннон шепчет нам на ухо сладкое слово «энтропия». Да, мы можем вычислить значение для любой строки, и существующие инструменты также имеют эту функцию. Но энтропия очень хитрая: нужно быть дворником и играть с пороговыми значениями. Этот шумный метод поиска довольно бесполезен в больших и старых кодовых базах, таких как наша. У него также есть несколько забавных побочных эффектов.
Давайте рассмотрим несколько сценариев и поймем основную причину проблемы.
Случай 1

Предполагая, что у нас есть строка, которая определенно имеет «большую» энтропию, давайте поместим эту строку в другой контекст:

Ой. И теперь у нас есть явное ложное срабатывание. Конечно, мы можем начать анализ контекста с добавления новых проверок и регулярных выражений, но эти меры не всегда будут работать: вы будете постоянно натыкаться на новые непокрытые ситуации.
Случай 2

В этом примере у нас просто недостаточно данных для достижения пороговых значений энтропии. И снова у нас есть явный намек из контекста — «pwd».
Случай 3
Самый яркий пример.

Забавно, но трюфель нашел здесь 2 секрета (отмечено красным)

Давайте углубимся в это.
Все секретные инструменты сканирования пытаются разбить файл на мелкие части, а затем проанализировать их. Как они это делают? Желтые метки на картинке выше показывают, как именно они разбивают файл: в основном по пробелам и разрывам строк. И в этом основная проблема.
Нынешние искатели секретов понимают файлы только как поток байтов. Они ничего не знают о семантике содержимого внутри, поэтому не могут найти языковые конструкции до анализа. Но эту возможность довольно сложно реализовать, так есть ли другие случаи, когда эти знания также могут быть полезны?
Случай 4
Еще один способ найти секреты – взять уже известные секреты из Vault/AD и т. д. и попробуйте найти что-то похожее в исходном коде.
:::предупреждение Этот подход может показаться опасным, и он действительно опасен, поэтому я призываю вас быть очень осторожными, если вы решите попробовать этот метод.
:::
Поэтому мы не будем рассматривать сравнение открытого текста с открытым текстом (никогда не делайте этого!) — это очевидно. Но как мы можем использовать хешированный секрет в качестве ссылки? Что мы должны хешировать внутри нашего кода для сравнения с эталонным хэшем?
Original Secret: ?
Hashed Secret: a515942cd6d0004f33ad8f327be4343fde8e81ce8e64420cd465d075289cd268
Должны ли мы использовать скользящее хеш-окно? Если да, то какой ширины она должна быть? Или мы должны продолжать делить пробелами и разрывами строк? Тогда кавычки останутся частью строк, а хэши не будут совпадать. Хорошо, давайте тоже начнем разбивать по кавычкам. Но некоторые пароли могут содержать кавычки на законных основаниях. Так что это не совсем верное направление.
Итак, у нас есть ряд вопросов, на которые нужно ответить:
- Как мы можем уменьшить количество анализируемых строк (исключить ключевые слова языка, знаки пунктуации, синтаксис и т. д.)?
- Как мы обнаруживаем конструкции, которые могут содержать секрет на любом данном языке? Например. строковые переменные, строки в словарях, комментарии и т. д.
Похоже, нам следует пойти глубже и научиться представлять текст в виде кода на заданном языке.
Понимание языка
Очевидный вопрос заключается в том, как инструменты понимают языки и форматы. Компиляторы и инструменты, называемые SAST (статическое тестирование безопасности приложений), часто создают древовидное представление кода, называемое абстрактным синтаксическим деревом. В нем есть весь необходимый контекст о коде: переменные, их имена и значения. Мы поговорим об этом чуть позже; на данный момент достаточно просто осознавать его таким, какой он есть. Поэтому мы намерены создать нечто подобное, которое будет работать быстро и с максимальным охватом доступных языков.
Должны ли мы взломать внутренний механизм SAST?
Нет. Это не расширяемый; он охватывает только один язык и является просто излишним. Кроме того, инструменты SAST плохо работают с отдельными файлами без зависимостей.
Есть ли компоновщики AST?
Да, но нет. Мы пишем наши внутренние инструменты на Python и не смогли найти достаточно надежных библиотек для создания AST для других языков. Кроме того, библиотеки, которые мы нашли, в основном заброшены и не имеют поддержки даже для своего языка.
Можем ли мы каким-то образом повторно использовать собственный синтаксический анализатор языка X?
Теоретически да, но представьте себе службу сканирования кода, которая одновременно использует десятки сред выполнения и снова пытается взломать их внутренний механизм, чтобы извлечь AST. Звучит как ерунда.
А как насчет языковых серверов?
Мы используем редакторы кода, такие как VSCode или VIM, и они понимают языки благодаря языковым серверам. Идея Language Server состоит в том, чтобы иметь автономный процесс, с которым другие инструменты могут взаимодействовать, используя языковой протокол (LSP). На первый взгляд, это выглядит как беспроигрышная ситуация: просто установите все языковые серверы, которые вы можете найти, и используйте дружественный стандартизированный протокол для запроса интеллекта для каждого языка. Более того, «семантические токены» теперь также являются частью стандарта.

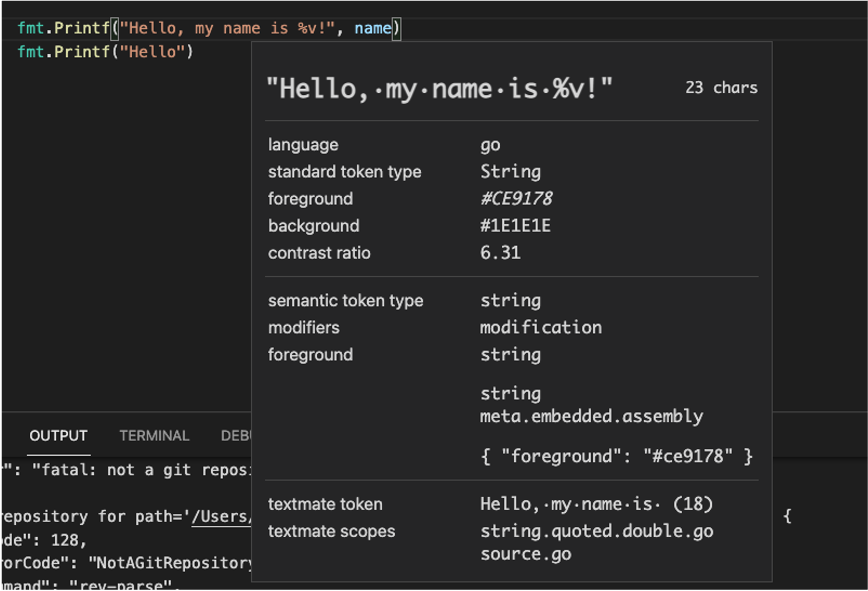
Но опять же, нет. По крайней мере на данный момент. На данный момент эта вещь не доработана, а языковые серверы с открытым исходным кодом в основном не поддерживают семантические токены.
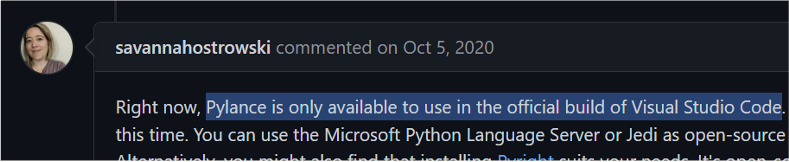
Хорошие, но проприетарные серверы, такие как Pylance, не могут работать автономно из-за лицензионных ограничений.
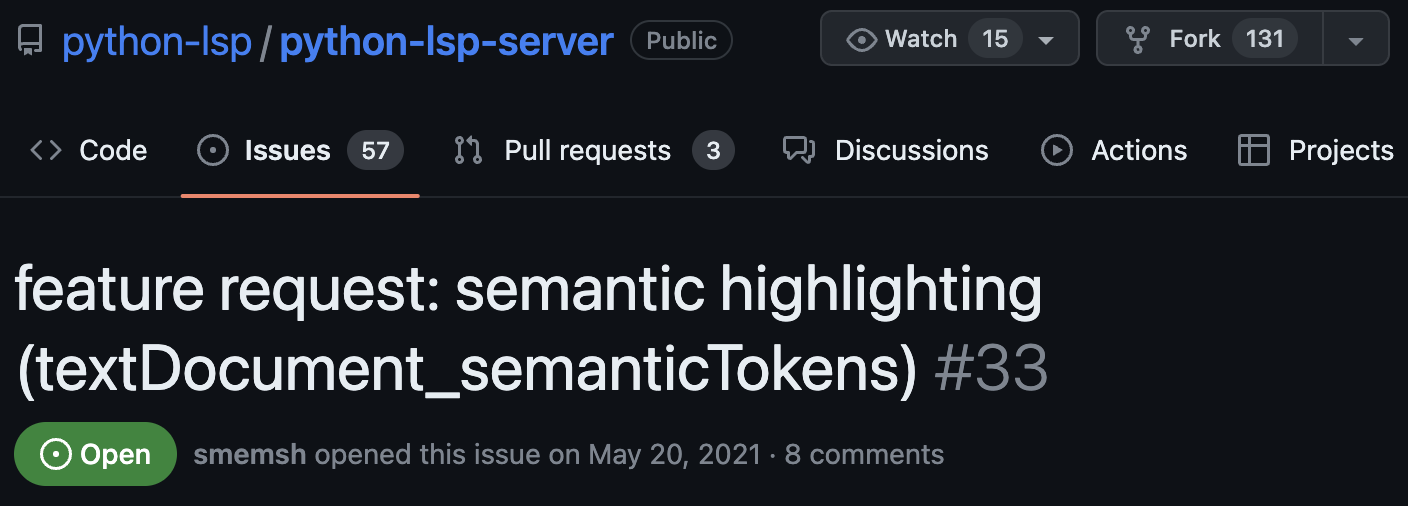
Другие серверы с открытым исходным кодом годами не получали поддержки
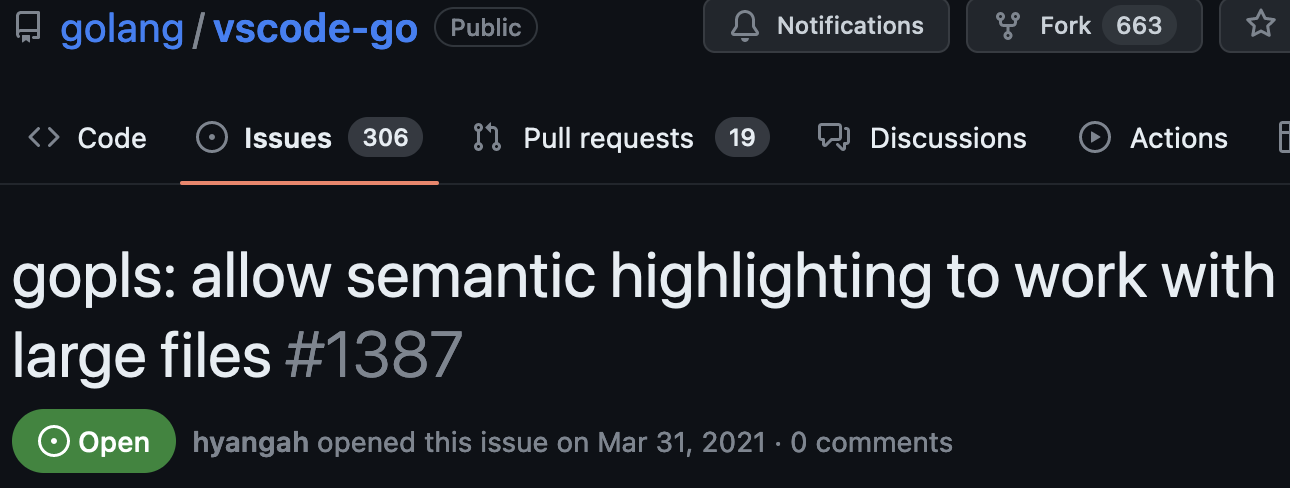
У некоторых есть проблемы с производительностью.
И все же нам нужно запустить N серверов для достойной языковой поддержки.
Сейчас нам кажется, что ничего не помогает.
Но в следующей части мы найдем элегантное решение, которое все это время было у нас под носом.
:::информация Рекомендуемое изображение для этой части было создано с помощью стабильной диффузии версии 2.1
Подсказка: проиллюстрируйте экран компьютера символом предупреждения.
:::