

Задачи машинного обучения на Swift без Python, нейронных сетей и библиотек
4 января 2024 г.Нейронные сети сегодня находятся на переднем крае машинного обучения (ML), и Python, несомненно, является подходящим языком программирования для любой задачи ML, независимо от того, собирается ли кто-то использовать нейронные сети для ее решения или нет. Существует обширный набор библиотек Python, которые охватывают весь спектр задач машинного обучения, например NumPy, Pandas, Keras, TensorFlow, PyTorch и т. д. Эти библиотеки обычно полагаются на реализации алгоритмов и подходов машинного обучения на C или C++, поскольку Python для них слишком медленный. Однако Python — не единственный существующий язык программирования, и я не использую его в повседневной работе.
Эта статья не является руководством по написанию чего-либо на Swift; скорее, это скорее размышление о нынешнем мышлении многих разработчиков, которые рассматривают Python как мост к окончательному решению для библиотек ML, которое решит любую проблему или задачу, с которой они сталкиваются, независимо от используемого ими языка. Я готов поспорить, что большинство разработчиков предпочитают тратить свое время на поиск способов интеграции библиотек Python в свой язык/среду, а не на рассмотрение альтернативных решений без них. Хотя это само по себе не так уж и плохо — повторное использование было важным фактором прогресса в ИТ за последние несколько десятилетий — я начал чувствовать, что многие разработчики больше даже не рассматривают альтернативные решения. Такое мышление становится еще более укоренившимся в связи с текущим состоянием и достижениями в области моделей больших языков.
Баланс отсутствует; мы спешим обратиться к LLM с просьбой решить наши проблемы, получить некоторый код Python, скопировать его и наслаждаться продуктивностью с потенциально значительными накладными расходами из-за ненужных зависимостей.
Давайте рассмотрим альтернативный подход к решению поставленной задачи, используя только Swift, математику и никакие другие инструменты.
Когда люди начинают изучать нейронные сети, есть два классических примера Hello World, которые вы можете найти в большинстве руководств и вводных материалов по ним. Первый из них — распознавание рукописных цифр. Во-вторых, это классификация данных. В этой статье я сосредоточусь на втором варианте, но решение, которое я рассмотрю, подойдет и для первого.
Очень хороший наглядный пример можно найти в TensorFlow Playground, где вы можете поиграть с различными структурами нейронной сети и визуально наблюдать, насколько хорошо полученная модель решает задачу.
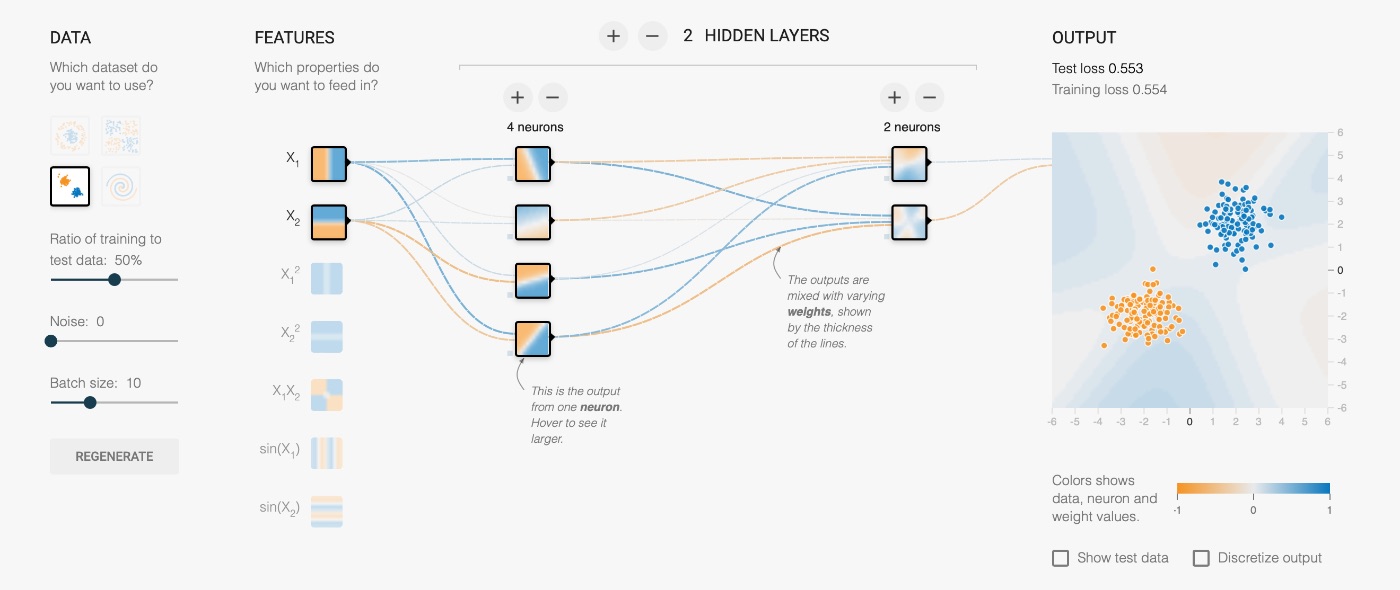
Вы можете спросить, в чем практическое значение этих точек на изображении разных цветов? Дело в том, что это визуальное представление некоторых наборов данных. Вы можете представить множество различных типов данных совершенно одинаково или похожим образом, например, социальные группы людей, которые покупают определенные продукты или музыкальные предпочтения. Поскольку я в первую очередь занимаюсь мобильной iOS-разработкой, я также приведу пример решаемой мной реальной задачи, которую визуально можно представить аналогичным образом: поиск электрических проводов внутри стен с помощью гироскопа и магнитометра на мобильном телефоне. В этом конкретном примере у нас есть набор параметров, связанных с найденным проводом, и другой набор параметров, ни для чего не находящихся внутри стены.
Давайте посмотрим на данные, которые мы будем использовать.
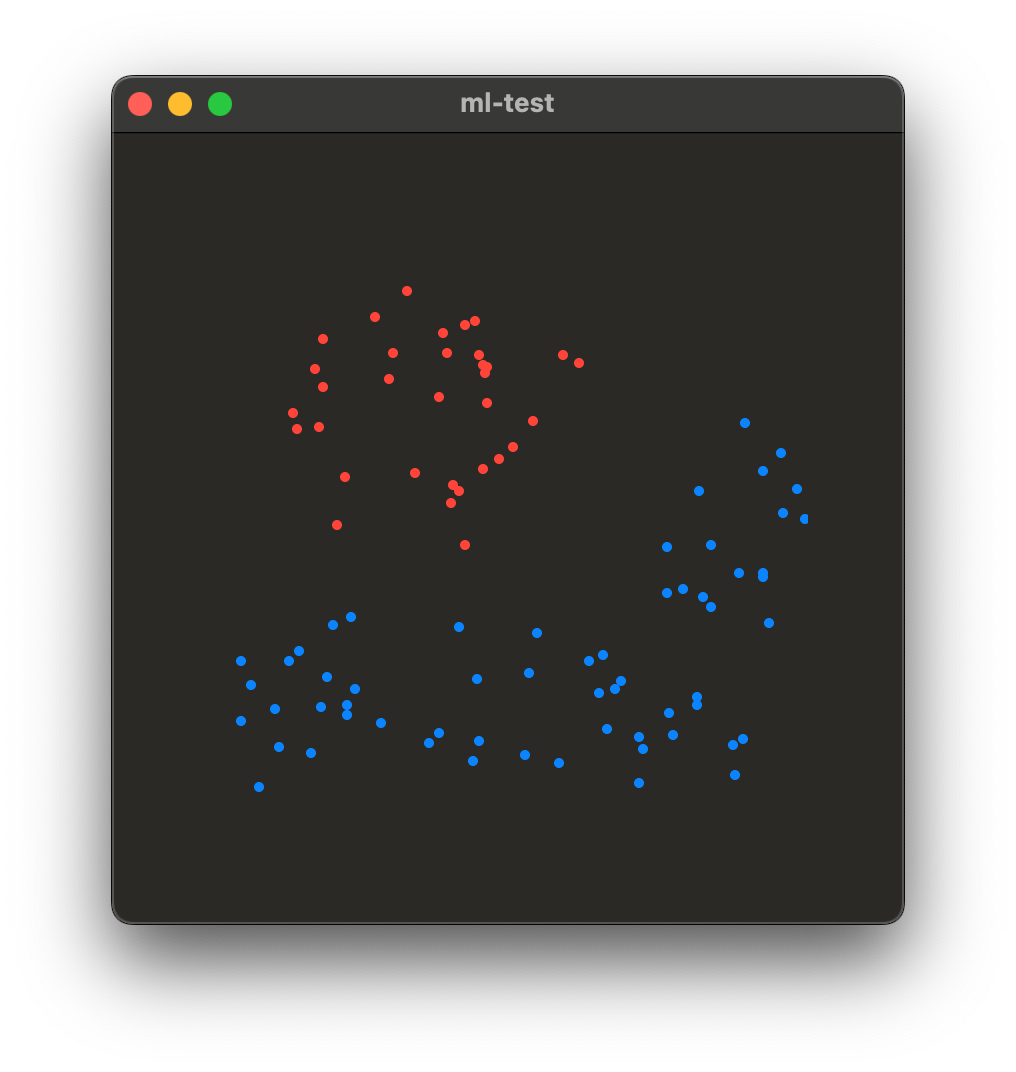
Здесь у нас есть два типа данных: красные точки и синие точки. Как я описал выше, это может быть визуальное представление любых секретных данных. Например, давайте возьмем красную область как ту, где у нас есть сигнал от магнитометра и гироскопа в случае, если у нас есть электрический провод в стене, и синюю область, если его нет.
Мы видим, что эти точки каким-то образом сгруппированы вместе и образуют своего рода красные и синие фигуры. Эти точки были созданы путем взятия случайных точек из следующего изображения:

Мы будем использовать это изображение в качестве случайной модели для нашего процесса обучения, взяв случайные точки для обучения модели и другие случайные точки для тестирования нашей обученной модели.
Исходное изображение имеет размер 300 х 300 пикселей и содержит 90 000 точек (точек). В целях обучения мы будем использовать только 0,2% этих точек, что составляет менее 100 баллов. Чтобы лучше понять работу модели, мы случайным образом выберем 3000 точек и нарисуем вокруг них кружки на изображении. Такое визуальное представление даст нам более полное представление о результатах. Мы также можем измерить процент точности, чтобы проверить эффективность модели.
Как мы будем делать модель? Если мы посмотрим на эти два изображения вместе и попытаемся упростить нашу задачу, то обнаружим, что задача, по сути, состоит в том, чтобы воссоздать исходную картинку по имеющимся у нас данным (пакет красных и синих точек). И чем ближе картина, которую мы получим от нашей модели к исходной, тем точнее будет работать наша модель. Мы также можем рассматривать наши тестовые данные как своего рода чрезвычайно сжатую версию нашего исходного изображения и поставить перед собой цель распаковать их обратно.
Что мы собираемся сделать, так это преобразовать наши точки в математические функции, которые будут представлены в коде в виде массивов или векторов (здесь в тексте я буду использовать термин вектор только потому, что он находится между функцией из математического мира и массивом из разработки программного обеспечения). Затем мы будем использовать эти векторы, чтобы проверить каждую тестовую точку и определить, какому вектору она больше принадлежит.
Чтобы преобразовать наши данные, я попробую дискретное косинусное преобразование (DCT). Я не буду вдаваться в математические объяснения того, что это такое и как работает, поскольку при желании вы легко сможете найти эту информацию. Однако я могу объяснить простыми словами, как это может нам помочь и почему это полезно. DCT используется во многих областях, включая сжатие изображений (например, формат JPEG). Он преобразует данные в более компактный формат, сохраняя только важные части изображения и удаляя неважные детали. Если мы применим DCT к нашему изображению размером 300x300, содержащему только красные точки, мы получим матрицу значений 300x300, которую можно преобразовать в массив (или вектор), взяв каждую строку отдельно.
Давайте, наконец, напишем для него какой-нибудь код. Во-первых, нам нужно создать простой объект, который будет представлять нашу точку (точку).
enum Category {
case red
case blue
case none
}
struct Point: Hashable {
let x: Int
let y: Int
let category: Category
}
Вы можете заметить, что у нас есть дополнительная категория под названием none. В конце концов мы создадим три вектора: один для точек красных, второй для точек синих и третий для всего остального, что представлено none< /код>. Хотя мы могли бы иметь только два из них, наличие обученного вектора не для красного и не для синего немного упростит задачу.
У нас есть `Point`, соответствующий протоколу Hashable, позволяющий использовать Set, чтобы избежать наличия точек с одинаковыми координатами в нашем тестовом векторе.
func randomPoints(from points: [Point], percentage: Double) -> [Point] {
let count = Int(Double(points.count) * percentage)
var result = Set<Point>()
while result.count < count {
let index = Int.random(in: 0 ..< points.count)
result.insert(points[index])
}
return Array<Point>(result)
}
Теперь мы можем использовать его для получения случайных 0,2% точек из исходного изображения для красных, синих точек и отсутствия точек.
redTrainPoints = randomPoints(from: redPoints, percentage: 0.002)
blueTrainPoints = randomPoints(from: bluePoints, percentage: 0.002)
noneTrainPoints = randomPoints(from: nonePoints, percentage: 0.002)
Мы готовы преобразовать эти обучающие данные с помощью DCT. Вот реализация:
final class CosTransform {
private var sqrtWidthFactorForZero: Double = 0
private var sqrtWidthFactorForNotZero: Double = 0
private var sqrtHeightFactorForZero: Double = 0
private var sqrtHeightFactorForNotZero: Double = 0
private let cosLimit: Int
init(cosLimit: Int) {
self.cosLimit = cosLimit
}
func discreteCosTransform(for points: [Point], width: Int, height: Int) -> [[Double]] {
if sqrtWidthFactorForZero == 0 {
prepareSupportData(width: width, height: height)
}
var result = Array(repeating: Array(repeating: Double(0), count: width), count: height)
for y in 0..<height {
for x in 0..<width {
let cos = cosSum(
points: points,
width: width,
height: height,
x: x,
y: y
)
result[y][x] = cFactorHeight(index: y) * cFactorWidth(index: x) * cos
}
}
return result
}
func shortArray(matrix: [[Double]]) -> [Double] {
let height = matrix.count
guard let width = matrix.first?.count else { return [] }
var array: [Double] = []
for y in 0..<height {
for x in 0..<width {
if y + x <= cosLimit {
array.append(matrix[y][x])
}
}
}
return array
}
private func prepareSupportData(width: Int, height: Int) {
sqrtWidthFactorForZero = Double(sqrt(1 / CGFloat(width)))
sqrtWidthFactorForNotZero = Double(sqrt(2 / CGFloat(width)))
sqrtHeightFactorForZero = Double(sqrt(1 / CGFloat(height)))
sqrtHeightFactorForNotZero = Double(sqrt(2 / CGFloat(height)))
}
private func cFactorWidth(index: Int) -> Double {
return index == 0 ? sqrtWidthFactorForZero : sqrtWidthFactorForNotZero
}
private func cFactorHeight(index: Int) -> Double {
return index == 0 ? sqrtHeightFactorForZero : sqrtHeightFactorForNotZero
}
private func cosSum(
points: [Point],
width: Int,
height: Int,
x: Int,
y: Int
) -> Double {
var result: Double = 0
for point in points {
result += cosItem(point.x, x, height) * cosItem(point.y, y, width)
}
return result
}
private func cosItem(
_ firstParam: Int,
_ secondParam: Int,
_ lenght: Int
) -> Double {
return cos((Double(2 * firstParam + 1) * Double(secondParam) * Double.pi) / Double(2 * lenght))
}
}
Давайте создадим экземпляр объекта CosTransform и протестируем его.
let math = CosTransform(cosLimit: Int.max)
...
redCosArray = cosFunction(points: redTrainPoints)
blueCosArray = cosFunction(points: blueTrainPoints)
noneCosArray = cosFunction(points: noneTrainPoints)
Здесь мы используем несколько простых вспомогательных функций:
func cosFunction(points: [Point]) -> [Double] {
return math.shortArray(
matrix: math.discreteCosTransform(
for: points,
width: 300,
height: 300
)
)
}
В CosTransform есть параметр cosLimit, который используется внутри функции shortArray, назначение которого я объясню позже, а пока давайте проигнорируем его и проверим результат 3000 случайных точек. из исходного изображения против наших созданных векторов redCosArray, blueCosArray и noneCosArray. Чтобы это заработало, нам нужно создать еще один вектор DCT из одной точки, взятой из исходного изображения. Мы делаем это точно так же и используя те же функции, которые мы уже использовали для наших векторов Red, Blue и None. Но как узнать, какому из них принадлежит этот новый вектор? Для этого существует очень простой математический подход: Скалярное произведение. Поскольку перед нами стоит задача сравнить два Вектора и найти наиболее похожую пару, скалярное произведение даст нам именно это. Если вы примените операцию скалярного произведения к двум одинаковым векторам, она даст вам некоторое положительное значение, которое будет больше, чем любой другой результат скалярного произведения, применимый к тому же вектору и любому другому вектору, имеющему разные значения. И если вы примените скалярное произведение к ортогональным векторам (векторам, которые не имеют ничего общего между собой), в результате вы получите 0. Учитывая это, можно придумать простой алгоритм:
- Пройдитесь по всем нашим 3000 случайным точкам одну за другой.
- Создайте вектор из матрицы 300x300 только с одной точкой, используя DCT (дискретное косинусное преобразование).
- Примените скалярное произведение для этого вектора с помощью
redCosArray, затем с помощьюblueCosArray, а затем с помощьюnoneCosArray. - Наибольший результат предыдущего шага укажет нам на правильный ответ:
Красный,Синий,Нет.
Единственная недостающая функциональность здесь — это скалярное произведение, давайте напишем для него простую функцию:
func dotProduct(_ first: [Double], _ second: [Double]) -> Double {
guard first.count == second.count else { return 0 }
var result: Double = 0
for i in 0..<first.count {
result += first[i] * second[i]
}
return result
}
А вот реализация алгоритма:
var count = 0
while count < 3000 {
let index = Int.random(in: 0 ..< allPoints.count)
let point = allPoints[index]
count += 1
let testArray = math.shortArray(
matrix: math.discreteCosTransform(
for: [point],
width: 300,
height: 300
)
)
let redResult = dotProduct(redCosArray, testArray)
let blueResult = dotProduct(blueCosArray, testArray)
let noneResult = dotProduct(noneCosArray, testArray)
var maxValue = redResult
var result: Category = .red
if blueResult > maxValue {
maxValue = blueResult
result = .blue
}
if noneResult > maxValue {
maxValue = noneResult
result = .none
}
fillPoints.append(Point(x: point.x, y: point.y, category: result))
}
Все, что нам нужно сделать сейчас, это нарисовать изображение из fillPoints. Давайте посмотрим на использованные нами точки поезда, векторы DCT, которые мы создали на основе наших данных о поездах, и конечный результат, который мы получили:
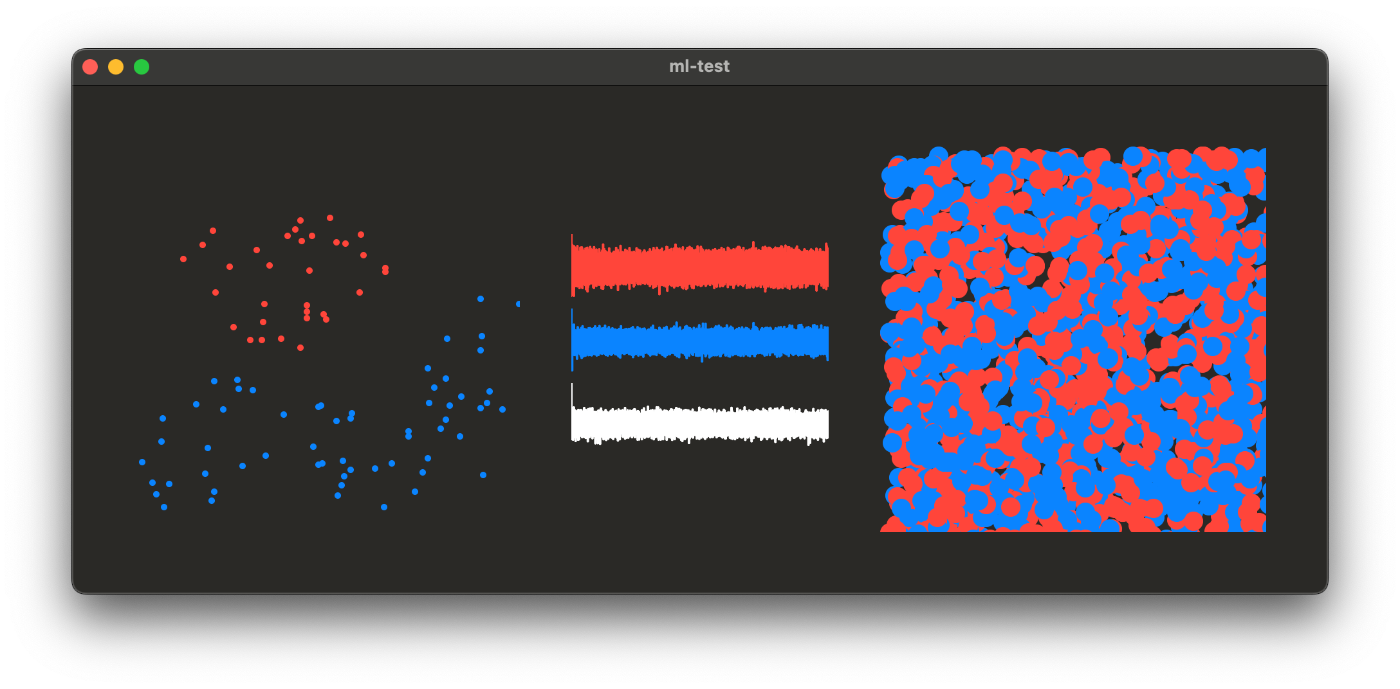
Ну, похоже на случайный шум. Но давайте взглянем на визуальное представление векторов. Вы можете увидеть там несколько всплесков, это именно та информация, на которой нам нужно сосредоточиться и удалить большую часть шума из нашего результата DCT. Если мы посмотрим на простое визуальное представление матрицы DCT, то обнаружим, что самая полезная информация (та, которая описывает уникальные особенности изображения) сосредоточена в верхнем левом углу:
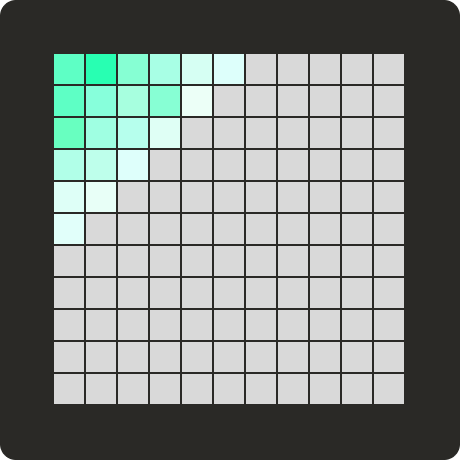
Теперь давайте сделаем шаг назад и еще раз проверим функцию shortArray. Мы используем здесь параметр cosLimit именно по той причине, что мы берем верхний левый угол матрицы DCT и используем только самые активные параметры, которые делают наш вектор уникальным.
func shortArray(matrix: [[Double]]) -> [Double] {
let height = matrix.count
guard let width = matrix.first?.count else { return [] }
var array: [Double] = []
for y in 0..<height {
for x in 0..<width {
if y + x <= cosLimit {
array.append(matrix[y][x])
}
}
}
return array
}
Давайте создадим наш объект math с другим cosLimit:
let math = CosTransform(cosLimit: 30)
Теперь вместо использования всех 90 000 значений мы будем использовать только 30 x 30/2 = 450 из верхнего левого угла матрицы DCT. Давайте посмотрим на полученный результат:
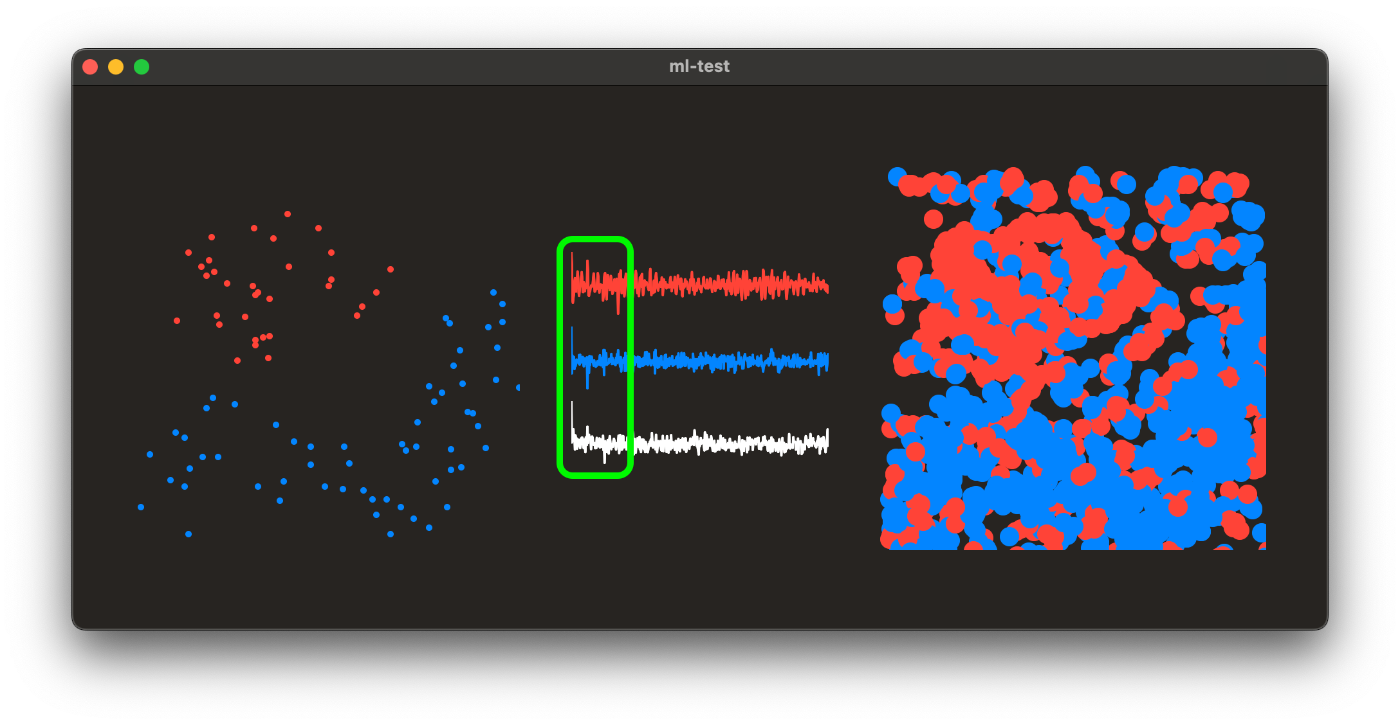
Как видите, уже лучше. Мы также можем заметить, что большинство шипов, которые делают векторы уникальными, по-прежнему расположены в передней части (как выделено зеленым на рисунке). Давайте попробуем использовать CosTransform(cosLimit: 6), что означает, что мы будет использовать только значения 6 x 6/2 = 18 из 90 000 и проверять результат:
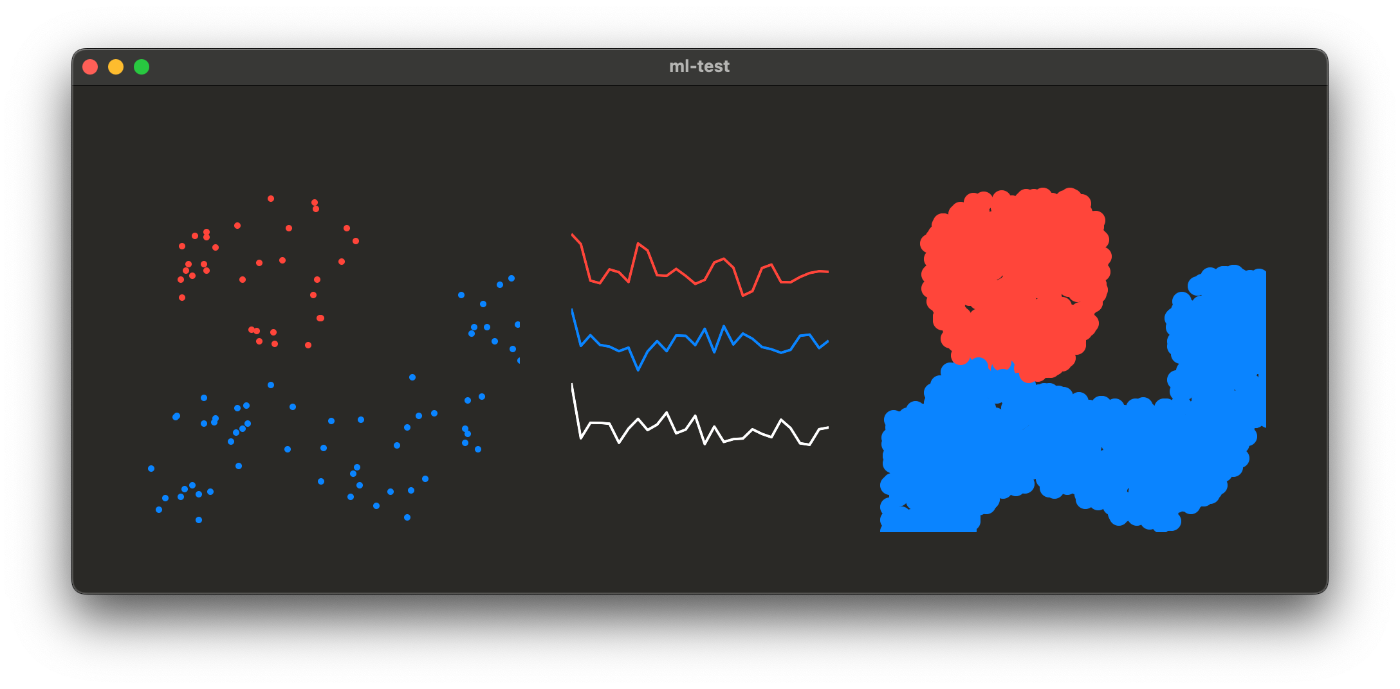
Теперь оно стало намного лучше и очень близко к исходному изображению. Однако есть только одна маленькая проблема — эта реализация медленная. Вам не нужно быть экспертом по сложности алгоритмов, чтобы понять, что DCT — это трудоемкая операция, но даже скалярное произведение, имеющее линейную временную сложность, недостаточно быстро при работе с большими векторами с использованием массивов Swift. Хорошей новостью является то, что мы можем сделать это намного быстрее и проще в реализации, используя vDSP из платформы Apple Accelerate, которая у нас уже есть в качестве стандартной библиотеки. Вы можете прочитать о vDSP здесь, но, говоря простыми словами, это набор методы для максимально быстрого выполнения задач цифровой обработки сигналов. Он имеет множество низкоуровневых оптимизаций, которые идеально работают с большими наборами данных. Давайте реализуем наше скалярное произведение и DCT, используя vDSP:
infix operator •
public func •(left: [Double], right: [Double]) -> Double {
return vDSP.dot(left, right)
}
prefix operator ->>
public prefix func ->>(value: [Double]) -> [Double] {
let setup = vDSP.DCT(count: value.count, transformType: .II)
return setup!.transform(value.compactMap { Float($0) }).compactMap { Double($0) }
}
Чтобы сделать его менее утомительным, я использовал несколько операторов, чтобы сделать его более читабельным. Теперь вы можете использовать эти функции следующим образом:
let cosRedArray = ->> redValues
let redResult = redCosArray • testArray
В новой реализации DCT существует проблема, связанная с текущим размером матрицы. Это не будет работать с нашим изображением размером 300 x 300, поскольку оно оптимизировано для работы с определенными размерами, степенью двойки. Поэтому нам нужно будет приложить некоторые усилия для масштабирования изображения, прежде чем передавать его новому методу.
Сводка
Спасибо всем, кто успел прочитать этот текст до сих пор или поленился пролистать, не читая. Целью этой статьи было показать, что многие задачи, которые люди не считают решенными с помощью некоторых собственных инструментов, можно решить с минимальными усилиями. Приятно искать альтернативные решения и не ограничиваться интеграцией библиотеки Python как единственного варианта решения таких задач.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27521)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)