Когда и зачем переходить на микросервисы
Одно из ключевых решений, которое вы должны принять при разработке архитектуры системы с использованием микросервисов, — выяснить, как разделить ваше приложение на набор микросервисов. Итак, в этом блоге разработчики Java описали различные стратегии разбиения, которые вы можете использовать. Важно помнить, что одной из целей разделения является обеспечение параллельной или параллельной разработки. Таким образом, разработка различных сервисов может происходить одновременно с развитием других сервисов, насколько это возможно.
Потому что, если вы сможете это сделать, это значительно увеличит скорость вашей команды. Итак, есть несколько различных стратегий разбиения, которые вы можете использовать. Таким образом, один из подходов заключается в
- Разбиение по существительному: Итак, вы создаете службу, отвечающую за все операции над определенным типом бизнес-объекта. Примером этого является служба каталога продуктов, которая отслеживает информацию о продуктах. Служба каталогов — это место, где хранится вся информация о продукте. У него также будет REST API для добавления и обновления продуктов, а также их поиска и извлечения.
Еще один способ разделения вашей системы:
- Разбиение по глаголу: Итак, у вас будет служба, отвечающая за конкретный вариант использования. Так, например, у вас может быть веб-приложение, реализующее пользовательский интерфейс Add-to-Cart. Это просто реализация тех веб-страниц, которые являются частью процесса добавления товаров в корзину. Например, у вас может быть служба доставки, которая отвечает за все аспекты доставки. Итак, это услуги, ориентированные на глаголы.
Другой способ разбиения:
- Разделение по поддоменам. Возьмите несколько идей из дизайна, ориентированного на домен. Это был бы домен, если бы вы рассмотрели все, что делает ваша компания. Однако внутри этого домена есть несколько поддоменов, каждый из которых представляет отдельный функциональный сектор вашей компании. В результате вы можете создать сервис, реализующий бизнес-логику для определенного домена.
Тогда мы могли бы также подумать о некоторых идеях объектно-ориентированного проектирования.
- Принцип единой ответственности. Боб Мартин, эксперт по объектно-ориентированному проектированию, разработал набор рекомендаций или принципов. Одним из них был принцип единоличной ответственности. Он имел в виду, что класс должен меняться только по одной причине. Другими словами, он должен нести ответственность только за одну вещь. Мы можем применить этот принцип к дизайну услуг и предложить, чтобы каждая услуга имела единую точку контакта. В результате мы получили бы довольно маленькие и связные сервисы. Термин «ответственность» имеет довольно неоднозначное определение. В результате разные люди могут интерпретировать это по-разному.
- UNIX: Если мы подумаем о командной строке Unix, то это будет не просто монолитный процесс командной строки, а набор утилит — cat, grep, find и т. д. Каждая из этих вещей выполняет довольно целенаправленную задачу. Мы могли бы использовать эту метафору для разработки нашего сервиса, иметь сервисы, которые просто хорошо выполняют одну конкретную задачу. А затем мы можем связать их вместе с помощью механизмов связи для выполнения более крупных задач.
Основные проблемы при разбиении
Но одна из интересных проблем с разделением сервисов — это разделение нашей фактической бизнес-логики и базы данных. И это создает действительно интересную проблему — как обеспечить согласованность данных или, другими словами, как обеспечить соблюдение инвариантов в нескольких микросервисах без использования двухэтапной фиксации. Но вот один из примеров, которые я использовал.
Предположим, вы получили заказы. Для каждого заказа есть общее количество заказов. После этого предположим, что у вас есть клиенты. Однако есть загвоздка, когда у клиента есть кредитный лимит. Идея здесь заключается в том, что непогашенные заказы клиента не должны превышать кредитный лимит. Итак, это пример инварианта, который представляет собой бизнес-правило, которому необходимо постоянно следовать в рамках программы. Если это монолитная программа, вы можете просто использовать транзакции ACID, чтобы выполнить ее.
Вы можете подумать, что одной из целей транзакций ACID является обеспечение согласованности или, другими словами, обеспечение соблюдения этих инвариантов. Но тогда, если мы разобьем систему на службы, где у нас есть служба управления заказами, которая хранит заказы, и служба управления клиентами, которая держит клиентов, как нам обеспечить соблюдение инварианта, охватывающего эти две службы? Мы хотим иметь возможность разделить нашу систему. Но мы также должны обеспечить последовательность.
Еще одна трудность с разбиением на разделы заключается в том, что оно требует глубокого понимания структуры вашей системы. Вы должны точно понимать, что вы ломаете. Итак, если у вас уже есть монолит, понять, как его разделить, довольно просто. У вас уже есть набор модулей с взаимозависимостями. У вас есть хорошее представление о том, что вы хотите демонтировать. Для этого может быть трудно распутать его и правильно разбить на модули.
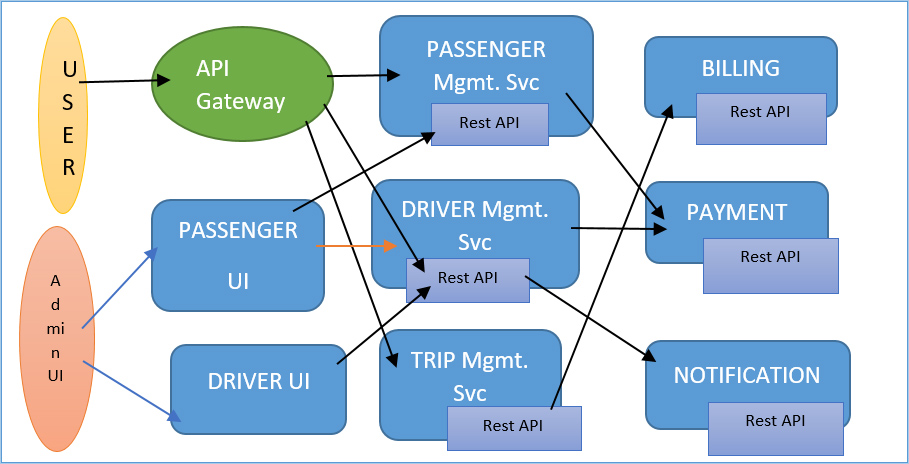
Общий принцип закрытия:
Общий принцип замыкания говорит о том, что компоненты, которые изменяются по одной и той же причине, на самом деле должны быть упакованы вместе. Таким образом, вы можете подумать о том, чтобы поместить компоненты, которые изменяются по той же причине, в один и тот же микросервис. Потому что, если бы они были безразличными микросервисами и менялись синхронно, вам пришлось бы обновлять и повторно развертывать несколько микросервисов.
Когда поездка завершена, биллинговая служба выставляет счет путешественнику. Также есть платежный сервис, который платит водителю по окончании поездки и так далее. Как видите, мы разделили это приложение для поездок на несколько сервисов, каждый из которых отвечает за определенную функцию. В двух словах, это разделение. И, как я уже говорил, это во многом искусство. Кроме того, это очень зависит от вашего конкретного приложения. Однако на практике, как только вы освоите разбиение на разделы, обычно несложно придумать систему, которая хорошо работает для вашего приложения.
Шаблоны и стратегии развертывания:
Итак, после того как вы создали свои микросервисы, вам нужен способ их развертывания. Итак, в этом блоге я обрисовал в общих чертах некоторые проблемы, которые вам необходимо решить. Вы создали свои микросервисы. Вам нужно их развернуть. Существуют различные силы, о которых вам нужно или проблемы, о которых вам нужно подумать.
- Таким образом, сервисы вполне могут быть написаны с использованием различных языков. Они могут использовать разные фреймворки.
- И в некоторых случаях, даже если они написаны на Java, они могут использовать, например, разные версии Java или разные версии среды Spring.
- Таким образом, существует множество вариантов того, как выглядят ваши услуги.
- Во время выполнения каждая служба будет иметь множество экземпляров службы. У вас может быть общее представление об услуге, такой как служба каталогов или платежная служба. Итак, там есть фрагмент кода. Однако вы почти наверняка захотите выполнять множество копий этой программы во время выполнения не только для удовлетворения спроса, но и для обеспечения высокой доступности.
- У вас должно быть достаточно оставшихся экземпляров, чтобы взять на себя и обработать нагрузку, если один из этих экземпляров выйдет из строя. Весь процесс разработки и запуска сервиса должен быть быстрым. Рассмотрим всю идею непрерывного развертывания.
- Если кто-то вносит изменения. Он автоматически тестируется и развертывается. Весь этот процесс должен быть быстрым. Таким образом, сервисы необходимо развертывать и масштабировать независимо друг от друга. Это одна из основных причин Java или любых других микросервисов.
- Независимое развертывание и масштабирование каждой услуги. Требуется изоляция между экземплярами службы. Если одна служба работает неправильно, в идеале мы не хотим, чтобы это влияло на другие службы.
- И в идеале мы хотим иметь возможность ограничивать ресурсы, которые предоставляются пользователям данного сервиса. Мы хотим просто сказать, что он может использовать столько ЦП. Он может использовать столько-то памяти и столько-то пропускной способности. Мы не хотим, чтобы служба произвольно росла и поглощала всю доступную память.
- Кроме того, весь процесс развертывания изменений в рабочей среде должен быть надежным.
- Есть несколько различных стратегий, которые вы можете использовать. На высоком уровне существует более традиционный шаблон нескольких служб на хост, когда вы запускаете несколько экземпляров служб на данном хосте. Кроме того, есть более современный подход, при котором на каждом хосте, который может быть виртуальной машиной, физической машиной или контейнером, выполняется ровно один экземпляр службы.
сервисов на контейнер:
В этом java spring boot разработчики четко объяснили шаблон, известный как сервис для каждого контейнера. Итак, основная идея этого подхода заключается в том, что вы берете код для своей службы и упаковываете его как контейнер, а затем, когда вы развертываете экземпляры службы, каждый экземпляр службы является работающим контейнером, и у вас вполне может быть несколько контейнеров. работает на той же виртуальной машине.
В двух словах, это стратегия, но что она влечет за собой на практике? Docker, как вы знаете, является синонимом концепции контейнеров. Docker — это все о контейнерах, поэтому возможно, что его самого по себе недостаточно, и вам нужно будет использовать какое-то решение для кластеризации поверх него. Например, вы можете использовать Kubernetes, кластерное решение Docker от Google, или Marathon, который представляет собой слой поверх Mesos, который позволяет вам управлять своими контейнерами.
Существует также инструмент под названием DCHQ, который предоставляет удобный интерфейс для развертывания контейнеров Docker на виртуальных машинах. Во всех этих случаях идея состоит в том, чтобы иметь пул виртуальных машин, который кластерное решение обрабатывает как один большой пул ресурсов, и он отвечает за получение наших контейнеров и размещение их на машинах, а затем управление ими, поддержание их работоспособности и Бег.
Все упаковано в виде контейнеров Docker, которые впоследствии запускаются на кластере серверов. В результате у этой стратегии есть множество преимуществ. На самом деле он обладает многими преимуществами виртуальных машин, такими как превосходная изоляция. Базовая технология отличается — контейнеры техники виртуализации на уровне ОС, которая преобразуется в каждый контейнер, являющийся набором отдельных потоков песочницы.
Таким образом, независимо от того, какую технологию вы использовали для реализации своего сервиса, вы упаковываете его в виде контейнера и отдаете кому-то для развертывания — интерфейс здесь такой же, как и просто, запускает контейнер. Остановите контейнер. Это делает развертывание очень надежным процессом.
Базовая операционная система используется всеми службами, работающими на одном компьютере. Поскольку они такие легкие, мы получаем отличное использование ресурсов и время развертывания. Например, создание образа Docker занимает пять секунд в среде, в которой вы работаете, тогда как его публикация в реестре занимает 30 секунд. Может потребоваться еще 30 секунд, чтобы перевести его в производственную среду. Таким образом, программа запускается относительно быстро, поскольку не требуется загрузка ОС — при запуске контейнера запускается и процесс Java.
Шаблон связи (шлюз API)
Я описал шаблон шлюза API. Итак, проблема, которую он решает, заключается в следующем. Как клиенты системы взаимодействуют с микросервисами, составляющими систему? Если подумать, в монолитной архитектуре действительно есть одна вещь, которая раскрывает некоторые конечные точки HTTP. И очень понятно, с кем должен разговаривать клиент.
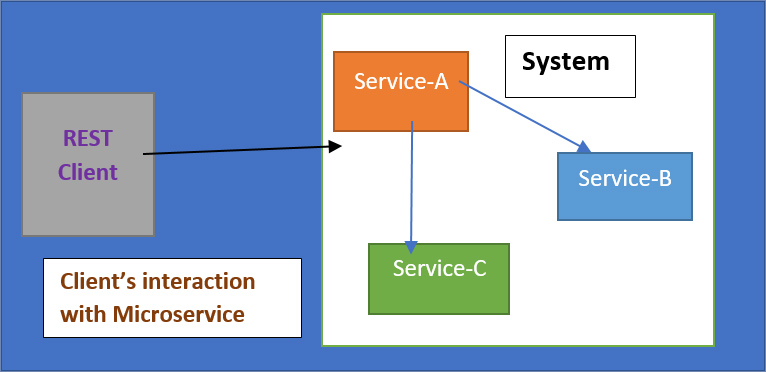
Но в микросервисном приложении у вас могут быть сотни сервисов. И в таком случае, с какой из этих служб должен связаться этот клиент? Там есть некоторые проблемы. В качестве примера здесь приведена страница сведений о продукте Flipkart.
Клиентом в этом случае может быть приложение. Эта страница отображается веб-приложением. Чтобы отобразить страницу, она должна собрать множество фрагментов данных из нескольких микросервисов. В результате он должен получать основную информацию о продукте, а также, среди прочего, обзоры, предложения и рейтинг продаж. Чтобы отобразить этот веб-сайт, он должен собрать большое количество отдельных фрагментов данных. При определении того, как клиенты приложения взаимодействуют с программой на основе микросервисов, необходимо учитывать ряд факторов или проблем.
Обычно существует несоответствие между детализированными микросервисами и требованиями клиента. Итак, клиенту, отображающему веб-страницу, просто необходимо большое количество информации о продукте. Однако эта информация рассредоточена по ряду сервисов. Данные проверки хранятся в службе проверки. Служба информации о продукте содержит информацию о продукте, тогда как служба рекомендаций содержит рекомендации. В результате данные, которые требуются веб-приложению, рассредоточены по многочисленным микросервисам. Более того, разным клиентам могут потребоваться разные данные.
Таким образом, веб-приложению, отображающему страницу браузера, может потребоваться намного больше данных, чем клиенту, работающему на мобильном устройстве с маленьким экраном. Существуют также различия в характеристиках сети. Так, например, веб-приложение, работающее в локальной сети, имеет доступ к сети с гораздо более высокой пропускной способностью и гораздо меньшей задержкой, чем приложение, работающее через Интернет, глобальную сеть или мобильное приложение, которому приходится использовать мобильную сеть.
Кроме того, количество экземпляров службы и сетевых расположений, а также их IP-адреса и порты могут регулярно меняться. Когда вы закрываете экземпляр службы и перезапускаете его, он может работать или не работать на том же хосте или на том же порту. Если вы используете автоматическое масштабирование, количество имеющихся у вас экземпляров может резко меняться в зависимости от нагрузки. В результате это чрезвычайно динамичная и изменчивая атмосфера.
Реальная сегментация системы на сервисы может меняться со временем. Вы можете разделить услугу на две части. Возможно, вы решите объединить две услуги в одну. И вы хотели бы иметь возможность скрывать это от своих клиентов. Клиенты могут использовать устройства, которые вы не контролируете, или вы не можете заставить их обновляться синхронно по мере улучшения вашей системы. В результате, вы должны держать это закрытым.
Итак, пример ситуации. Итак, слева у вас есть традиционное веб-приложение на стороне службы, которое обращается к микрослужбам в локальной сети. И тогда у вас также есть мобильный клиент. Это может быть какой-то JavaScript, работающий в мобильном браузере. Или это может быть нативное приложение. И это доступ к приложению через мобильную сеть. Кроме того, само приложение состоит из различных микросервисов, некоторые из которых имеют интерфейс REST, а некоторые другие могут иметь интерфейс, отличный от HTTP. В данном случае бинарный протокол TCP.
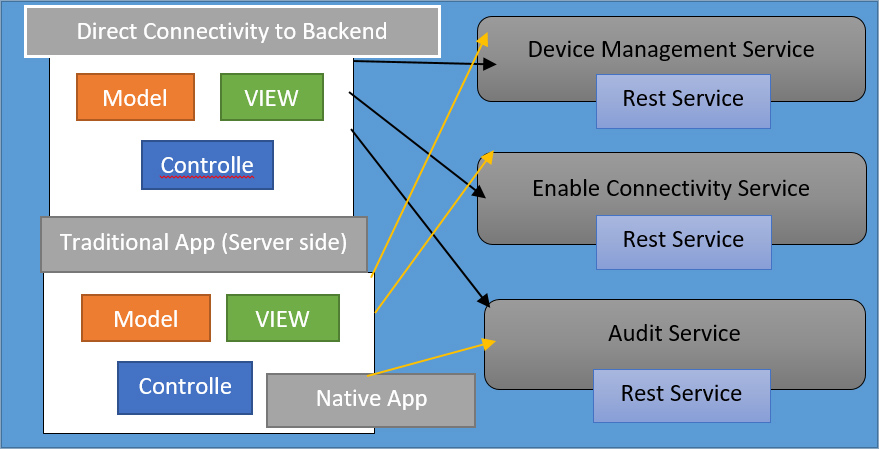
В результате одним из способов связи клиентов является обращение непосредственно к микрослужбам. И с этим куча проблем. Во-первых, API может быть несколько разговорчивым. В результате сбор данных, необходимых для отображения страницы сведений о продукте, требует выполнения нескольких внутренних запросов к службе. Это вряд ли будет проблемой для типичного веб-приложения, работающего в локальной сети. Однако для мобильного клиента, подключенного к мобильной сети, это вряд ли будет работать успешно. Еще одна проблема, с которой вы можете столкнуться, заключается в том, что некоторые службы могут предоставлять протоколы, которые не подходят для Интернета. Они действительно не проходят через брандмауэры.
API-шлюз в микросервисах Java:
Шаблон шлюза API имеет целый ряд преимуществ. Он подключает всех клиентов к различным микросервисам. Он предоставляет прекрасный REST API, и когда приходит запрос, он может перенаправить его в соответствующий микросервис в простом экземпляре. Он действительно может предоставить клиентский API для каждого клиента. Таким образом, веб-приложение, работающее в локальной сети, доступ к которому осуществляется локально в локальной сети, может иметь просто диалоговый интерфейс, который сопоставляется один к одному с микросервисами.
Однако он может предоставить крупнозернистый API для клиента, работающего на мобильном устройстве, например, предоставить входные данные о продукте, которые он может обработать, отправив запрос ко всем внутренним службам, агрегируя результат и передавая его обратно в мобильный клиент. Таким образом, мобильный клиент должен совершить только одну поездку туда и обратно, что является значительным улучшением, если он использует мобильную сеть.
Преобразование протоколов — это нечто большее, чем шлюз API. В результате он может переводить между миром веб-HTTP и любыми внутренними протоколами. Другой замечательный пример — брокер сообщений, который использует AMQP для внутренних целей. Шлюз API может преобразовывать сообщения в сообщения WebSocket, которые затем можно отправить в браузер. Netflix — фантастический пример корпорации, выбравшей эту стратегию.
Вместо того, чтобы предоставлять единый API для всех своих потоковых клиентов, они решили создать свой собственный. Они решили, что это то, что вы могли бы считать API-шлюзом, они запускают специфичный для клиента код на стороне сервера, который предоставляет каждому клиенту свой собственный настраиваемый API, который хорошо подходит для нужд этого клиента. А затем, когда приходит запрос, этот код шлюза фактически преобразует этот запрос в вызовы различных серверных служб. Он разветвляется на семь различных вызовов внутренних служб.
Основные преимущества:
- Отделяет разбиение от клиентов. Клиент просто видит API, который предоставляет шлюз. Затем шлюз имеет код, который перемещает разделы. Он защищает клиентов от необходимости знать, где в сети находятся все экземпляры службы.
- Шлюз API выбирает лучший API для каждого клиента. Это упрощает жизнь клиента, гарантируя совместимость API с сетью клиента. И в большинстве случаев это соответствует меньшему количеству циклов между клиентом и сервером, что важно в мобильной сети.
- Шлюз API также упрощает клиент, перемещая логику выполнения нескольких запросов в логику, выполняющую один вызов шлюза API, где есть логика, выполняющая разветвление. И он также переводит другие протоколы в веб-протоколы, ориентированные на HTTP.
Основным недостатком является повышенная сложность. Вы должны эксплуатировать и поддерживать этот шлюз API, который должен быть высокодоступным и т. д.
Шаблон обнаружения сервисов в микросервисах:
Предположим, вы создаете код, который будет использовать HTTP для вызова службы. Для этого ваш клиент должен сначала определить сетевое расположение экземпляра службы, который он пытается вызвать. В контексте современного микросервиса проблему, с которой вы столкнулись, довольно сложно решить. В результате в этой статье я представил несколько шаблонов, которые можно применить для решения этой проблемы.
Можно выбрать различные узоры. Есть обнаружение на стороне клиента, обнаружение на стороне службы и шаблон реестра службы, и это лишь некоторые из них. Итак, проблема открытия заключается в следующем. Итак, у вас есть клиент, который хочет вызвать службу. Эта служба состоит из различных экземпляров службы. И есть несколько разных проблем, которые делают знание сетевого местоположения немного сложным.
IP-адреса и номера портов назначаются динамически. Такова природа современных систем развертывания, где мы можем использовать контейнеры или виртуальные машины. IP-адреса, а также номера портов назначаются динамически. Фактическое количество экземпляров службы может изменяться на лету. Вы можете автоматически масштабировать вверх и вниз в зависимости от нагрузки. В результате динамически назначаются не только сетевые местоположения, но и набор экземпляров службы.
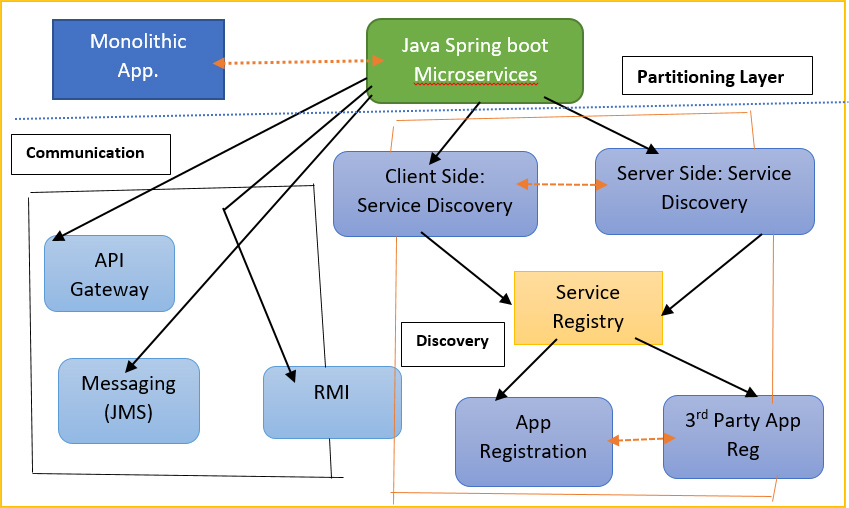
Вы должны знать, где они находятся, что сложно. И затем вам также нужно найти способ балансировки нагрузки между ними. Вот два распространенных решения, которые мы можем придумать для этой проблемы.
- Первый известен как обнаружение службы на стороне клиента, где мы используем интеллектуальный HTTP-клиент. Экземпляры службы при запуске регистрируют свои сетевые местоположения в реестре службы. Таким образом, служба Order запустится и сообщит своему реестру служб, что она здесь, и это служба Order, и она работает на этом IP-адресе и порте.
- И другие экземпляры службы Product будут делать то же самое. Когда клиент хочет сделать HTTP-запрос к каталогу продуктов, он сначала просматривает реестр служб, чтобы узнать, какие экземпляры служб доступны. И реестр служб укажет, что они работают на определенном порту и IP-адресе. Затем клиент может сбалансировать нагрузку между этими экземплярами службы. В результате он полагается на службы, регистрирующиеся в реестре служб, который работает как база данных, а затем имеет интеллектуальные возможности для запроса реестра служб для определения фактического расположения в сети.
- Открытый исходный код Netflix является прекрасной иллюстрацией этого. Eureka — это сервисная регистрация, которую они используют. Итак, это сервер с HTTP-интерфейсом, через который службы могут регистрироваться, а клиенты могут запрашивать базу данных доступных экземпляров службы.
- Они также оснащены интеллектуальным HTTP-клиентом с поддержкой реестра. Когда вы используете Ribbon для отправки запроса, он может запросить Eureka, чтобы узнать, где в сети расположены службы, к которым вы пытаетесь получить доступ.
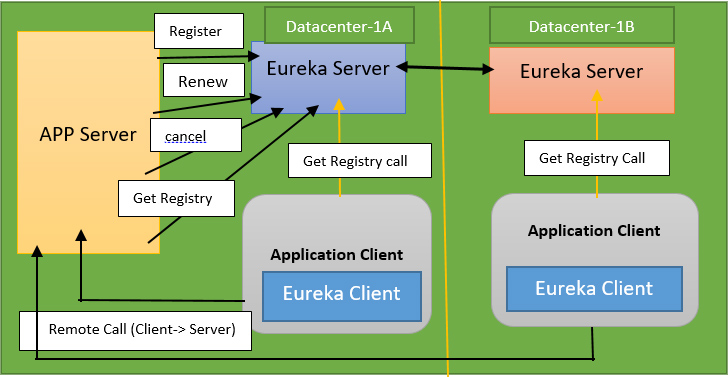
- Это позволяет гибко выполнять балансировку нагрузки для конкретного приложения. В результате клиент узнает о доступных экземплярах и может применить логику конкретного приложения, чтобы выбрать, к какому из них отправить запрос. Возможно, он пытается использовать согласованные стратегии хеширования, такие как отправка одного и того же запроса для одного и того же объекта в один и тот же экземпляр службы, чтобы воспользоваться преимуществами кэширования.
- У вас много гибкости. Кроме того, очень мало сетевых переходов. Клиенты просто разговаривают напрямую со службами. И кроме наличия реестра служб, нет никаких других компонентов инфраструктуры. один недостаток заключается в том, что клиент должен знать о реестре службы.
Архитектура обнаружения на стороне сервера:
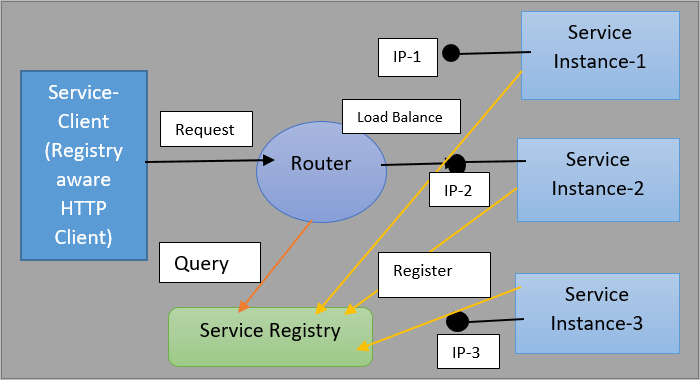
Весь вопрос, связанный с необходимостью наличия смарт-клиента, доступного для целого ряда фреймворков, немного затруднителен. Обнаружение на стороне сервера — это альтернативный способ решения этой проблемы. И он работает так же, как и раньше: экземпляры службы регистрируются в реестре службы. Итак, есть сервисный реестр. Оно в курсе всех событий. Затем клиент просто отправляет запрос компоненту маршрутизации. Ему не нужно делать ничего умного; все, что ему нужно сделать, это связаться с этим компонентом маршрутизации. Затем компонент маршрутизации выполняет балансировку нагрузки, запрашивая реестр службы.
Итак, мы переместили логику из службы в маршрутизатор, потому что это означает, что служба может просто снова стать тупым HTTP-клиентом. Вы могли бы сказать, что хорошим примером этого является Amazon, он использует эластичный балансировщик нагрузки для балансировки нагрузки как трафика, поступающего из Интернета, так и внутреннего трафика в вашей системе. А есть и другие примеры. Как это довольно часто используется, чтобы использовать что-то вроде Nginx, чтобы действовать как этот умный маршрутизатор.
В результате эта стратегия имеет ряд преимуществ. Прежде всего, это удаляет интеллект клиента. Клиенту не нужно быть умным. Вам не придется беспокоиться о создании интеллектуального клиента, который работает на многих языках и платформах. Это также просто особенность некоторых сред. Вы просто получаете его ни за что. Вы также можете использовать эластичный балансировщик нагрузки в AWS. Если вы используете Kubernetes или Marathon, вы заметите, что каждый компьютер в кластере Kubernetes имеет компонент маршрутизации: локальный прокси. Он получает запрос от клиента и передает его одному из доступных экземпляров службы. Это просто бесплатно и предустановлено.
Модель домена источника событий в микросервисах
Как создать модель предметной области, которая использует преимущества источников событий. В этой части мы рассмотрим реальный пример кода, вариант использования размещения заказа, который имеет две службы: службу заказа и обслуживание клиентов. И вы увидите, как выглядит код в этих микросервисах. Итак, как я упоминал в предыдущем разделе, существуют различные модели программирования, некоторые из которых функциональные, а некоторые — объектно-ориентированные.
Я объяснил здесь объектно-ориентированную версию в этой части. Итак, это Java-код, изменяемые объекты предметной области в традиционном понимании. Когда дело доходит до объектно-ориентированного программирования, основная концепция заключается в том, что у вас есть объекты, которые содержат состояние и поведение.
Реализации:
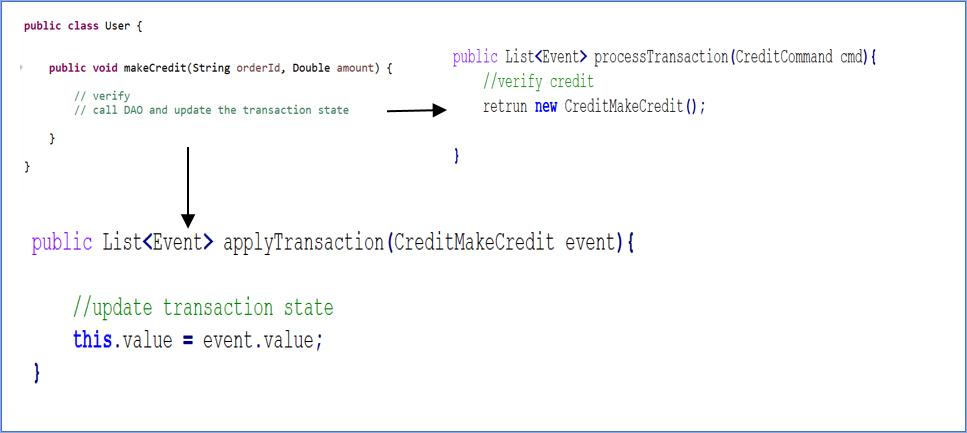
Таким образом, в совокупности клиентов есть такие поля, как кредитный лимит и резервирование кредита, которые представляют собой хэш-карту идентификатора заказа в общую сумму заказа. Он показывает, сколько резервирований было сделано по этому кредитному лимиту. Затем поведение выражается двумя типами методов: методом процесса, который принимает команду и возвращает список событий, и методом события приложения, который принимает событие и изменяет состояние агрегата.
В результате мы организовали доменную логику несколько иначе. Вы можете серьезно подумать, как бы вы регулярно делали это. Вы бы использовали такой механизм, как резервный кредит, который принимает идентификатор заказа и сумму к оплате.
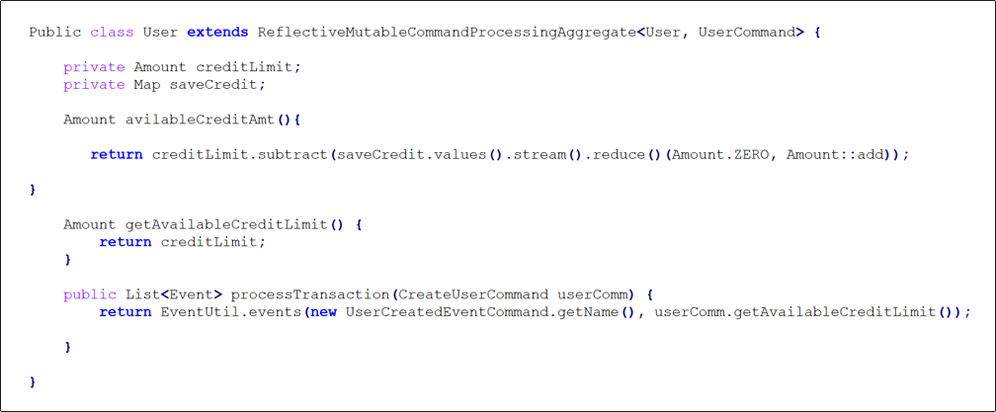
Вот фактическая совокупность клиентов. Итак, вы можете видеть, что у него есть поле кредитного лимита, поле резервирования кредита, которое является картой. Затем есть некоторая бизнес-логика, такая как доступный кредит, который просто использует хороший Java 8 Streams API, чтобы суммировать резервирование кредита и вычесть его из кредитного лимита. Вы можете видеть, что он расширяет агрегат обработки изменяемых команд Reflective и определяет некоторые методы команд процесса.
Команда создания клиента передается методу команды процесса, который возвращает событие, созданное клиентом. Вот и все; просто пройти через логику. Техника команды резервного кредита команды процесса немного интереснее. Однако он содержит некоторую бизнес-логику. Возвращает событие зарезервированного кредита клиента, если доступный кредит больше или равен общей сумме заказа. В противном случае верните превышенный кредитный лимит клиента, даже если проверка кредитного лимита не пройдена. В результате мы добавили в него некоторую бизнес-логику.
Когда мы смотрим на применяемые методы, мы видим, что их два. Есть еще метод apply, который принимает событие, созданное клиентом, и действует как функция Object() { [собственный код] }. Кредитный лимит установлен на ноль, а резервирование кредита установлено на пустую карту.
Хэш-карта резервирования кредита обновляется в соответствии с фактическим методом приложения для события резервирования кредита клиентом. Тогда кредитный лимит клиента превышен, метод приложения события ничего не дает. Это не означает изменение состояния. Он не должен ничего менять, но он должен быть применим к этому событию. Вот пример коллекции.