
Алгоритм MEME: оптимизация уклонения от вредоносных программ посредством извлечения модели и обучения с подкреплением
18 апреля 2024 г.:::информация Авторы:
(1) Мария Ригаки, факультет электротехники, Чешский технический университет в Праге, Чешская Республика, и maria.rigaki@fel.cvut.cz;
(2) Себастьян Гарсия, факультет электротехники, Чешский технический университет в Праге, Чехия, и sebastian.garcia@agents.fel.cvut.cz.
:::
Таблица ссылок
Справочная информация и сопутствующая работа
Заключение, благодарности и ссылки
4 Методика
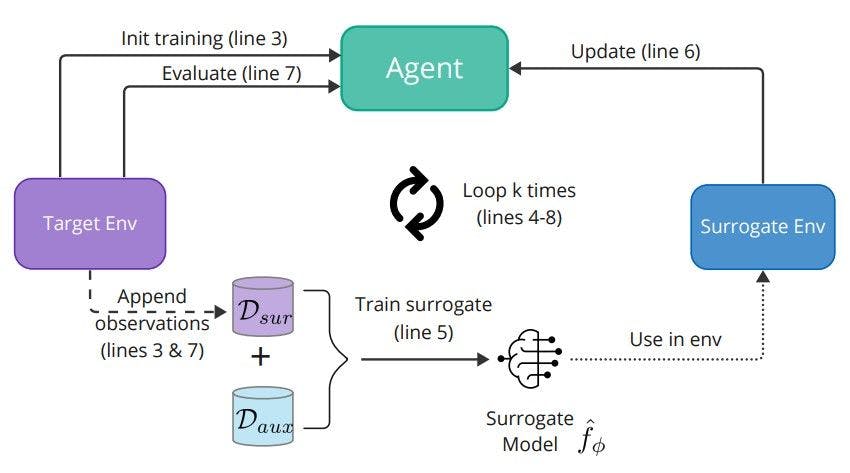
Алгоритм MEME сочетает в себе методы извлечения моделей и обучения с подкреплением (RL) для улучшения генерации скрытых двоичных файлов вредоносного ПО. Алгоритм использует тот факт, что злоумышленник полностью контролирует часть среды, связанную с двоичными модификаторами, но не контролирует целевую модель, которая представляет собой черный ящик. Однако злоумышленник может использовать данные, собранные в ходе обучения агента RL, для создания и обучения суррогатной модели цели. Алгоритм реализуется в виде нескольких раундов обучения/тестирования до тех пор, пока не будет изучена окончательная политика обучения с подкреплением, которая может создавать состязательные двоичные файлы для заданной цели. На рисунке 2 представлено общее описание алгоритма, а подробный листинг представлен в алгоритме 1.

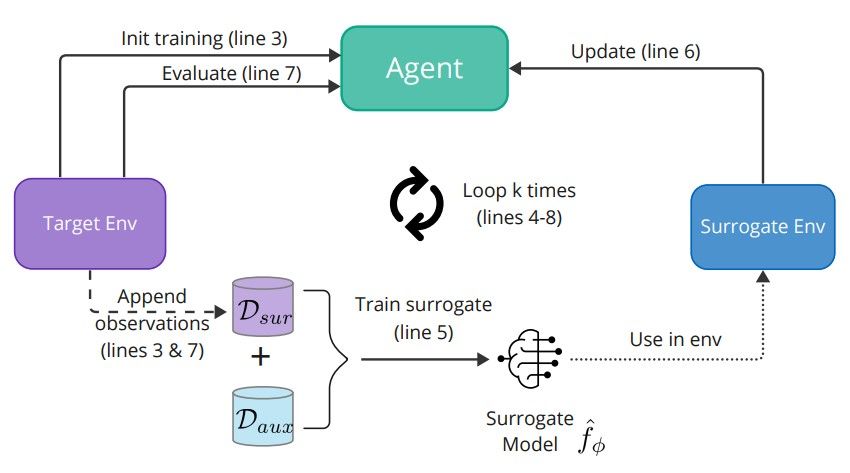
Следуя алгоритму 1, MEME инициализирует алгоритм RL оптимизации проксимальной политики (PPO) [35 (строки 1 и 2) для выполнения первого поезда политики PPO с использованием целевой модели и ограниченного количества шагов (с использованием MalwareGym). Цель этого шага — сохранить небольшое количество наблюдений и меток в Dsur (строка 3). Затем Dsur объединяется со вспомогательным набором помеченных данных (Daux), которым должен обладать злоумышленник, и этот объединенный набор данных используется для обучения суррогатной модели для атаки с извлечением модели (строка 5). Улучшенный суррогат заменяет целевую модель в новой среде Malware-Gym, которая обучает лучшую политику (агента) уклонению (строка 6). Наконец, улучшенная политика сравнивается с исходной целевой моделью (строка 7) для получения окончательных показателей уклонения. На этом последнем шаге мы воспользуемся запросами, выполненными к цели, чтобы добавить их выходные данные в набор данных Dsur.
Этот цикл повторяется в течение k раундов. Во время последнего раунда оценка выполняется с использованием двоичного набора тестов вредоносного ПО для получения окончательных показателей уклонения (вместо двоичного набора оценки вредоносного ПО, используемого во внутреннем цикле). Общее количество запросов к цели во время обучения равно k ∗ n, где k — общее количество раундов.
Для изучения политики мы используем алгоритм PPO, который представляет собой метод градиента onpolicy без модели, который отсекает целевую функцию, ограничивая обновления, вносимые в политику, чтобы избежать слишком больших положительных изменений или минимума отрицательных изменений, чтобы стабилизировать ее. . Мы использовали реализацию PPO Stable Baselines3 [31], использующую архитектуру Actor-Critic (A2C).
Для обучения суррогатной модели недостаточно использовать данные, собранные в ходе обучения или оценки агента в Dsur. Количества выборок недостаточно, поскольку мы стремимся свести к минимуму запросы к цели. Кроме того, все наблюдения основаны на извлеченных функциях вредоносного двоичного набора данных или их состязательных модификациях. Поэтому для изучения хорошего суррогата необходимо использование вспомогательного набора данных. Предполагается, что этот набор данных относится к тому же распределению, что и распределение обучающих данных цели, однако этого нелегко достичь, если целью является AV или неизвестная система.
Адаптация к среде тренажерного зала MEME был реализован на базе среды Malware-Gym (раздел 3.1) в последней версии1. В среду было внесено несколько изменений, чтобы соответствовать предположениям и ограничениям этой работы:
– Действие «Изменить тип компьютера» было удалено, поскольку наши тесты показали, что оно создает недопустимые двоичные файлы для систем Windows 10.
– Все цели были настроены так, чтобы возвращать жесткие метки (0 или 1), а не оценки.
– Что касается безопасных разделов, реализация Malware-Gym использовала только данные из разделов «.text». В нашей реализации мы используем данные из других разделов, если раздел «.text» недоступен.
– Последняя среда поддерживает в качестве целевых классификаторы Ember и Sorel-LGB. Мы добавили новые среды для поддержки целей Sorel-FFNN, суррогатных и AV. Для AV требуется веб-служба на виртуальной машине, которая вызывает возможности статического сканирования AV.
– Для всех целевых сред мы добавили поддержку сохранения наблюдений (функций) и оценок во время обучения и оценки, чтобы их можно было использовать для обучения суррогатного объекта.
Нашу версию среды и эксперименты, проведенные в рамках этой работы, можно найти по адресу (https://github.com/stratосферips/mememalware rl/releases/tag/v1.0). Обратите внимание, что мы публикуем исходный код нашей реализации для обеспечения воспроизводимости и улучшения; однако мы не публикуем обученные модели или агенты во избежание возможного неправильного использования.
4.1 Оценка уклонения
Чтобы разумно и реалистично оценить производительность моделей уклонения, мы ограничили количество запросов, которые они выполняют, к целевой модели и продолжительность их выполнения. Идея сокращения времени работы заключается в том, что процент, с которым авторы вредоносных программ создают новые вредоносные программы, высок, а метод, который занимает слишком много времени для создания уклончивых вредоносных программ, непрактичен. Отраслевые измерения, подобные тем, что предоставлены AV-ATLAS [18], показывают, что в минуту создается 180 новых вредоносных программ. Virus Total [41] предоставляет еще более высокие показатели — 560 отдельных новых файлов, загружаемых в минуту по состоянию на 21 мая 2023 года. Эти глобальные измерения различаются, но показывают, как быстро появляются новые варианты вредоносного ПО, возможно, из-за распространения вредоносных программ как вредоносных программ. Фреймворки a-Service. В недавнем и более консервативном исследовании Blackberry отмечается, что их клиенты подвергаются атакам 1,5 новых вредоносных программ в минуту [39]. Учитывая приведенные выше измерения, мы решили ограничить продолжительность каждого эксперимента четырьмя часами. Учитывая, что тестовый набор состоит из 300 двоичных файлов вредоносного ПО, это соответствует 1,25 обрабатываемых двоичных файлов в минуту, что ниже самого консервативного показателя, который мы смогли найти.
Основным показателем, используемым для оценки задачи уклонения от вредоносного ПО, был коэффициент уклонения E, который представляет собой долю вредоносного ПО, которое становится уклоняющимся в течение четырех часов, от общего количества вредоносных программ, первоначально обнаруженных каждой целью: E = nev/ нет .
Мы также сообщаем о среднем количестве двоичных модификаций, необходимых для того, чтобы двоичный файл вредоносного ПО уклонился от цели. Для методов Random, PPO и MEME это эквивалентно средней длине эпизода по всем обнаруженным двоичным файлам вредоносного ПО в тестовом наборе. Длина эпизода для неуклончивого двоичного кода равна максимальному количеству попыток, а для уклончивого — количеству изменений, необходимых для того, чтобы стать уклончивым. Для структуры MAB для уклончивых двоичных файлов мы рассматривали только минимальные двоичные файлы с наименьшим количеством действий. Среднее количество двоичных модификаций при GAMMA-атаке измерить было невозможно, поскольку платформа SecML (с помощью которой была реализована GAMMA) не обеспечивает прямого способа измерения этого показателя.
4.2 Суррогатная оценка
Суррогатные модели, обученные в MEME, оценивались с использованием двух разных показателей: согласования меток и согласования признаков на основе объяснимости [37]. Согласование меток двух моделей f и ˆf соответственно определяется как среднее количество похожих прогнозов по тестовому набору Xtest и является стандартной метрикой для атак на точность извлечения модели [19]:

Метрика согласия признаков вычисляет долю общих признаков между наборами топ-k признаков двух объяснений. Учитывая два объяснения Et (цель) и Es (суррогат), метрику согласованности функций можно формально определить как:
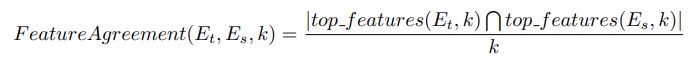
где top Features(E, k) возвращает набор топ-k признаков объяснения E на основе величины значений важности признаков. Максимальное значение согласия признаков равно 1. Для этой работы мы измерили согласие признаков для k = 10 и k = 20, а использованным методом объяснительности был SHAP (SHapley Additive exPlanations) [25]. SHAP использует принципы теории игр для объяснения результатов модели машинного обучения, связывая эффективное распределение кредитов с локализованными объяснениями через значения Шепли, возникшие из теории игр. SHAP не зависит от модели и в прошлом эффективно использовался для создания состязательных вредоносных программ [33]. Для целей LightGBM мы использовали TreeSHAP, разработанный специально для древовидных моделей, а для Sorel FFNN мы использовали вариант KernelSHAP.
:::информация Этот документ доступен на arxiv по лицензии CC BY-NC-SA 4.0 DEED.
:::
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27103)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)