

Мастер -геопространственные данные: от Python's .apply () до расширенных альтернатив
22 июля 2025 г.Использование некоторых методов и модулей для разработки программирования и данных в наборе данных геопространственного (GPS Location)
Привет всем 👋👋,
Python-это мощный, гибкий и дружелюбный язык для начинающих. Но давайте будем честными - это не всегда самое быстрое. Особенно при работе с большими наборами данных производительность Python может стать узким местом. Это особенно верно при использовании Pandas '.apply () или петли - задачи, которые могут занять мучительно много времени.
Хорошие новости? Есть много более быстрых альтернатив - и в этом посте я проведу вас через них.
Вы научитесь:
- Генерировать синтетические геопространственные данные (например, координаты GPS) в Python,
- Применить расчеты расстояния к каждой строке DataFrame,
- Заменить Apply () с более быстрыми альтернативами (например, векторизацией и параллелизмом),
- Оценки различных стратегий, включая встроенные встроенные вкладки, Numpy и параллельные вычислительные библиотеки, такие как Pandarallel и Swifter.
🧪 Шаг 1: Настройка чистой среды Python
Чтобы сохранить все опрятные, давайте начнем с виртуальной среды:
Python3 -m Pip установить VirtualEnv Python3 -m venv my_env source my_env/bin/activate
Если вы используете Jupyter (например, с VS -кодом), выберите ядро `my_env`, когда его предъявлено.

my_env активируется на ZSH (Fino Theme) -Изображение автора
my_envактивируется.
Если вы поработаете над расширением кода Visual Studio Jupyter, вы получите всплывающее окно об установке ядра для ноутбука Jupyter. Для кода он может использовать ноутбук Jupyter или продление кода jupyter. Следует отметить, что вы должны выбрать ядро Юпитераmy_envПри использовании ноутбука Jupyter или кода VS.
Вы можете удалитьmy_envПапка, если вам больше не нужно, и снова и снова воссоздайте новую виртуальную среду ...
🛠 Шаг 2: Проблема - Обработка каждой строки в DataFrame
Допустим, у вас есть данные о данных со случайными распределениями координат GPS-подобных (широта, долгота), и вы хотите применить функцию (например, расчет расстояния) к каждой строке.
Это распространенный сценарий в науке о данных, и то, как вы обрабатываете строки, очень важно, когда производительность является ключевой.
🐌 Обычный способ - петли и .apply () (медленная полоса)
Иногда нам нужно выполнять одну и ту же операцию в каждой строке в кадре данных. Первый метод для этого - это использование примитивной петли. Пример можно увидеть ниже. У нас есть кадр данных, и я хочу применить операцию вfoo()функцияiterrows()Функция дает мне каждую строку, и после того, как я получу ряды, я могу легко обработать их в цикле FOR.
1. Iterrows (): классическая петля
for index, row in df.iterrows(): df.loc[index, "processed_feature"] = foo(row["A"])
🔻 Этот метод читабелен, но очень медленно. Он обрабатывает строки по одному в Pure Python.
2. Применить (): чище, но все же медленно
df["processed_feature"] = df.apply(lambda row: foo(row["A"]), axis=1)
✅ Синтаксис более короткого
🔻 все еще медленно - особенно с большими данными.
🏃чего Шаг 3: быстрее альтернативы .apply ()
Вот лучшие варианты - более быстрые, более эффективные и столь же читаемые.
3. itertuples (): быстрее, чем iterrows ()
Третий метод - это ирус. Это лучше, чем два метода, упомянутые выше. Для использования инитлурdf.itertuple()Так же, как метод Iterrows.
foo(row.A) for index, row in df.itertuples()
✅ намного быстрее, чемiterrows()
🔻 Все еще не векторизован - производительность может пострадать от очень больших наборов данных.
4. Понимание списка: Pythonic & Lean
Метод понимания списка имеет более конкретный подход. Мы бы предпочли только ту функцию, которая нам нужна, чем использовать все данные DataFrame. Конечно, этот подход ускорит время расчета. Потому что интерпретатор не должен отделять один столбец из других каждый раз. Использование этого подхода можно увидеть в коде ниже.
df["processed_feature"] = [foo(x) for x in df["A"]]
✅ Эффективный и компактный
✅ избегает накладных расходов по ряду операций
🔻 работает только на одном столбце
5. map (): просто и быстро
Функция карты является одним из лучших подходов. Это быстрее, чем примитивные петли или другие, потому что этот метод также используется путем отправки параметра в конкретный столбец. В качестве примера.
df["processed_feature"] = df["A"].map(foo)
✅ Очень быстро
✅ Синтаксис чистого
🔻 Ограничено функциями с одним столбцом
⚡ Шаг 4: скорость с наддувом с векторизацией
6. numpy.vectorize (): векторизованный, но не всегда быстрее
Numpy - это векторная библиотека, написанная для пользователей Python, и она используется почти каждым программистом или ученым, работающим с DataFrames. Для Numpy имя твое численное. Модуль Python имеет функцию, называемую Vectorized, и он может помочь нам, взяв конкретный столбец DataFrame в качестве параметра.
Эта функция обеспечивает быстрое вычисление в векторном пространстве. Точно так же, с модулями Numba или CFFI, они вычисляют быстрее, чем другие параметры, поскольку они могут компилировать код после преобразования блока кода в язык низкого уровня, такой как C, C ++. Метод numpy.vectorize может использоваться, как ниже.
import numpy as np
df["processed_feature"] = np.vectorize(foo)(df["A"])
✅ Векторизованный синтаксис
🔻 Не обеспечивает истинную векторизованную производительность - это все еще петля под капюшоном
7. True Pandas Vectorization 💥 (Золотой стандарт)
Методы векторизации панда - очень простой подход для решения этой проблемы, и они чрезвычайно быстры. Единственное, что нужно сделать, это разделить операцию в качестве функции и вызвать функцию в основном блоке. Новая функция получает DataFrame в качестве параметра и вычисляет процессы, а затем возвращает обработанный столбец. Пожалуйста, проверьте код ниже.
def func(df):
return df['A']*10
df["procecessedfeature"]=func(df)
✅ Самый быстрый вариант для цифровых или столбцевых операций
✅ Чистый и элегантный
🔻 Ограничено операциями, которые могут быть векторизированы
🔥 Шаг 5: Перейти параллельно! (Со всеми вашими ядрами процессора)
Для еще большей мощности давайте используем параллельные вычисления со специализированными библиотеками.
8. Пандараллель: параллель .apply () с легкостью
pandarallelэто модуль, который может использовать ядра процессоров более одного, например, Swifter. Если у вас много процессоров, вы можете распространять операции расчета по ядрам. Для установки вы можете использовать PIP и репозиторий PYPI.
pip install pandarallel from pandarallel
Основное использование:
import pandarallel
pandarallel.initialize()
df["processed_feature"] = df.parallel_apply(lambda row: foo(row["A"]), axis=1)
✅ Использует несколько ядер ЦП
✅ Легкая замена замены для.apply()
🔻 Небольшая настройка над головой
9. Swifter: умнее, параллельно.apply()
swifterеще один отличный инструмент для ускоренияpandasоперации. Он автоматически решает наилучший путь выполнения - будь то Pandas, DASK или параллелизированный подход - на основе размера и сложности ваших данных.
Это делает его чрезвычайно удобным для пользователя: просто замените.apply()с.swifter.apply()и пустьswifterОптимизируйте скорость за кулисами.
Для установки:
pip install swifter
Основное использование:
import swifter
df["processed_feature"] = df.swifter.apply(lambda row: foo(row["A"]), axis=1)
✅ Автоматически выбирает стратегию оптимальной вычисления
✅ Не требуется ручная параллельная настройка
🔻 немного более высокое использование памяти на небольших данных
🔻 May May Starkback в однопоточный режим на небольших данных о данных
💰🎁 Шаг 6 (бонус): используйте двигатели R или Julia для ускорения программ
Методы этого раздела не посещают сравнительные тесты.
10. Применить функцию в R
R Language имеет много функций, и его можно использовать с основными трюками в среде Python. Для использования нам нужен модуль RPY2 и пакет R-базы.
apt install r-base -y ## or brew install if you use mac pip install rpy2
Затем в вашей записной книжке:
%load_ext rpy2.ipython
##Push a pandas DataFrame 'df' to R environment
%Rpush df
И определите функцию R для работы на вашем рамке данных:
%%R foo <- function(df) {
##Example operation: calculate the sum of each column
df[] <- lapply(df, function(col) col * 2) # Just doubling each element return(df) }
df <- foo(df)
Затем вы можете потянуть модифицированный DF обратно в Python, если это необходимо с%Rpull df.
✅ Разблокирует производительность и функции R
🔻 Требуется дополнительная настройка
11. Используйте функции Джулии Ланг с Pyjulia
Так же, как RPY2 позволяет использовать R -функции внутри Python, вы можете использоватьPyJuliaДля плавного запуска кода Джулии в вашей среде Python. Это означает, что вы можете написать высокопроизводительные функции Julia для ваших тяжелых вычислений, а затем позвонить им непосредственно с Python-разблокируя скорость Джулии, не оставляя свой рабочий процесс Python.
!apt-get install julia -y !pip install julia
Затем инициализируйте Джулию внутри Python и определите свою функцию Julia:
from julia import Main
##Define a Julia function in Python
Main.eval(""" function haversine(lat1, lon1, lat2, lon2)
R = 6371.0 # Earth radius in kilometers
dlat = deg2rad(lat2 - lat1)
dlon = deg2rad(lon2 - lon1)
a = sin(dlat/2)^2 + cos(deg2rad(lat1)) * cos(deg2rad(lat2)) * sin(dlon/2)^2
c = 2 * atan2(sqrt(a), sqrt(1 - a))
return R * c end """)
Используя функцию Юлии в ваших данных:
Предполагая, что у вас есть Pandas DataFrame DF с столбцами LAT1, LON1, LAT2, LON2, примените функцию Юлии так:
import pandas as pd
##Example DataFrame
df = pd.DataFrame({ "lat1": [34.05, 40.71], "lon1": [-118.25, -74.01],
"lat2": [36.12, 42.36], "lon2": [-115.17, -71.06] })
##Call the Julia haversine function row-wise
df["distance_km"] = [Main.haversine(*row) for row in df.itertuples(index=False)]
print(df)
✅ Разблокирует выступление Джулии внутри Python
🔻 Требуется установка Джулии и начальная настройка
Резюме и заключение
Результаты теста на 100 тысяч записей
В этом исследовании мы исследовали и оценивали различные методы выполнения операций по строке в пандах, начиная с базовыхiterrows()иapply()для более оптимизированных методов, таких какvectorizationВswifter, иpandarallelПолем
Используя выборку из 100 000 геопространственных записей, мы измерили и визуализировали время выполнения каждого метода с постоянными интервалами, чтобы понять их вычислительную эффективность.

Результаты показывают резкий контраст в производительности:
- 🔵
iterrows()был безусловно самым медленным, с общим временем исполнения, превышающим2 секундыПолем Это подтверждает его репутацию метода, которого лучше избегать в критических приложениях.
- 🟠
apply()лучше, но все же продемонстрировал значительные накладные расходы по сравнению с более эффективными альтернативами, почти в1 секундаПолем
- 🟢 методы, как
itertuplesВmap, иlist comprehensionпоказали существенные улучшения скорости, обрабатывая весь набор данных вдо 0,1 секунды, делая их твердыми вариантами, когда векторизация невозможна.
- 🟣
np.vectorizeвыполняется сравнительно с вышеизложенным, но не давал никакого четкого преимущества по сравнению с нативными методами питона.
- 🔴
numpy_direct_vectorizedбыл самым быстрым из всех - выполнение задания в просто~ 0,02 секунды- Демонстрация силы истинного векторизованного вычисления с Numpy.
- ⚫
swifterи 🟡pandarallelДоставлено достойное ускорение, используя параллельные вычисления, но не превосходил векторизацию Numpy в этой установке с одним узлом. Их истинный потенциал, вероятно, сияет с большими наборами данных или более сложными операциями строк.
- Еслимаксимальная производительностьимеет решающее значение, и операция может быть математически векторизованной,Векторизация Numpyэто явный победитель.
- ЕслиВекторизация невозможна(например, сложная логика на строку),
itertuplesВmap, илиlist comprehensionПредложите чистый компромисс между читаемости и скоростью. - Дляболее крупные данные или многоядерные машины, модули, как
swifterиpandarallelможет значительно ускорить операции по строкам, используя параллельное выполнение.
Результаты теста 10M записей
В этом расширенном эталоне с использованием 10 миллионов строк, обработанных в кусках 10 000 строк, мы оценили производительность нескольких популярных панд-совместимых методов работы по строке. Цель состояла в том, чтобы оценить их масштабируемость и практическую эффективность при более тяжелой вычислительной нагрузке.
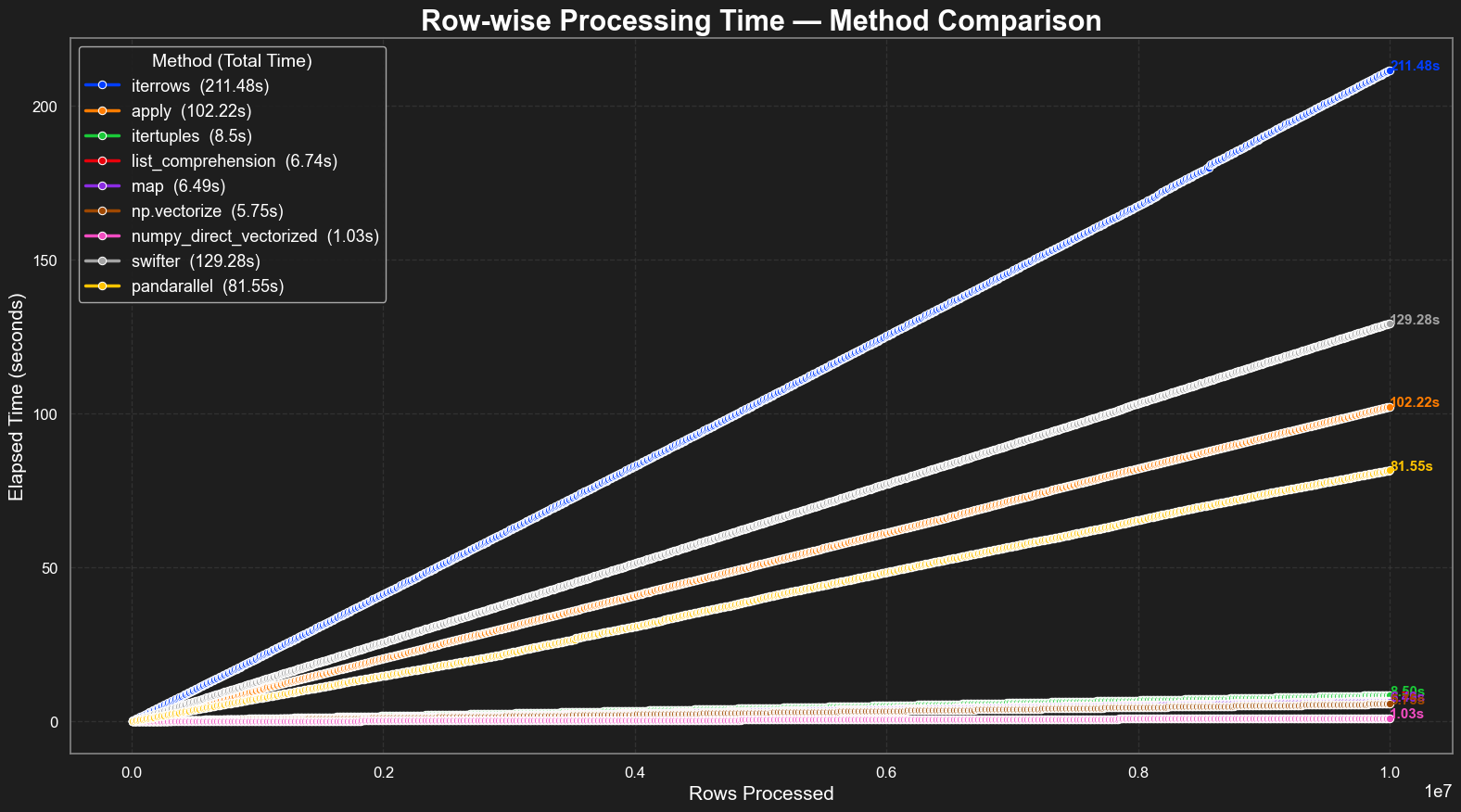
Результаты ясно показывают, чтоВыбор метода имеет значение еще больше в масштабе:
- 🔵
iterrows()еще раз оказался самым медленным с широким отрывом, с полным временем выполнения211,48 секундыПолем Его неэффективность становится экспоненциально выраженной по мере роста объема данных, усиливая, что его следует избегать во всех чувствительных к производительности приложениям.
- 🟠
apply()обеспечил лучшую производительность, чемiterrows, но все еще наступил в102,22 секунды, указывая на высокую накладную и умеренную масштабируемость.
- 🟢
itertuplesВmapи понимание списка значительно превзошли оба, с временем в диапазоне от6,49 с 8,5 сПолем Эти методы обеспечивают хороший баланс между читаемости и эффективностью для не векторизируемой логики.
- 🟣
np.vectorizeдостигнуто5,75 секундынемного опережая местные методы Python, но все же не достигли истинной векторизационной производительности.
- 🔴
numpy_direct_vectorizedснова был самым быстрым, выполняя задачу просто1,03 секундыПолем Это подчеркивает непревзойденную скорость низкоуровневых операций на основе массива, когда это применимо.
- ⚫
swifterи 🟡pandarallelОба предлагали значительный рост производительности (129,28 и 81,55 с,соответственно) над нативными методами пандов путем использования параллельных вычислений. Тем не менее, они все еще отставали от оптимизированной логики на основе Numpy. Их преимущества, вероятно, более выражены со сложными рядами вычислений или многоядерными средами, обрабатывающими большие рабочие нагрузки.
В конечном счете, выбор правильного метода зависит от вашего варианта использования - и этот эталон содержит действенную ссылку для принятия обоснованных решений для эффективной обработки данных в Python.
Все коды здесь и бесплатны для обзора на общественной сути.
https://gist.github.com/nuhyurdev/53249123ff9dacb7cc3935016abe15ea
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г.
⭐ Самое популярное
-
4 признака того, что ваш Instagram взломали (и что делать)
16 ноября 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Предстоящие эксклюзивы для PS5 — график выхода подтвержденных игр
24 октября 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (26645)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)