Является ли вся область машинного обучения слишком сложной задачей для людей, чтобы освоить или понять ее? За кодами и цифрами стоит множество научных рассуждений и статистических данных, но поскольку весь мир охвачен информационной революцией, не помешает узнать немного больше, чем окружающие.
Данные окружают вас повсюду и играют в вашей жизни такую большую роль, что вы, вероятно, в большинстве случаев даже не замечаете их. Безумие машинного обучения — это маленькая капля в море, которая делает возможными некоторые из этих ролей. Все от умного чат-бота в систему рекомендаций вашего любимого интернет-магазина работает во главе некоторых интеллектуальных алгоритмов, разработанных для того, чтобы упростить и упростить взаимодействие с пользователем.
Прямо к основам
Представьте типичный случай, когда такой же пользователь, как и вы, бродит по веб-сайтам, создает контент, делится мнениями и создает огромные объемы данных. Эти данные могут показаться просто последовательностью строк и чисел, но при их применении к вычислительной системе они могут дать великолепные результаты.
В случае машинного обучения группа инженеров и аналитиков сначала передает данные в такие программы, как SPSS и MATLAB. Цель здесь состоит в том, чтобы предоставить системе как входные, так и желаемые выходные данные, чтобы машина могла пройти через строительные блоки и в конечном итоге «научиться», как получить результат.
С технической точки зрения это осуществляется с помощью системы слоев и узлов, которые распределяют информационный ввод с разным весом. Эти узлы могут представлять точки данных и влиять на точность конечной модели. Таким образом, основной целью машинного обучения становится тестирование моделей путем настройки параметров и сравнения полученных результатов с фактическими результатами.
Пришло время освежить статистический анализ. Вспомните все уроки, посвященные изучению стандартного отклонения в школе. Стандартное отклонение становится инструментом для оценки того, насколько близко значения модели соответствуют фактическим значениям.
Вам может быть интересно, как это делается так? Аналитики разделяют части данных на одну часть для «обучения» данных и одну для их «тестирования». В этом контексте обучение и тестирование означают предоставление системе возможности изучить обученные данные или обучить их, а затем сопоставить их с данными тестирования для обеспечения точности.
КОМПОНЕНТЫ ТИПИЧНОЙ СЕТИ
Вы будете слышать слова "нейронные сети" много раз в любом тексте по машинному обучению. Это потому, что алгоритмическая система машинного обучения очень похожа на органическая нейронная сеть, в которой данные передаются и ретранслируются из точки в точку. Но для аналитика есть некоторые другие компоненты, о которых нужно позаботиться:-
Predictor: — Причудливый способ ссылки на параметры, переменные или входные данные, которые влияют на результат и используются в алгоритмической модели для создания вариантов использования. Не все предикторы играют открытую роль в выходных данных, поэтому аналитики тратят некоторое время на определение корреляций и коэффициентов между ними.
Неконтролируемые данные: неконтролируемые данные относятся к информации и наборам данных, в которых выходные данные прямо не указаны или не упомянуты, и, таким образом, система работает над разработкой нейронной сети, понимая, что отличает один вход от другого и как все параметры связаны с каждым. другой. Хорошим примером неконтролируемого набора данных могут быть изображения, которые должны быть классифицированы в соответствии с их типом, который явно не упоминается. Неконтролируемые данные обычно обрабатываются с использованием методов кластеризации и ассоциации.
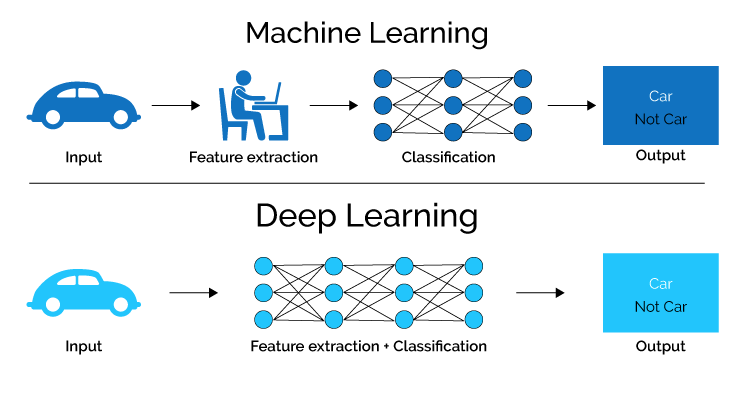
Контролируемые данные: - В отличие от неконтролируемых наборов данных, выходные переменные хорошо понятны в контролируемых наборах данных и могут быть смоделированы на основе входных данных. Контролируемые наборы данных могут иметь несколько выходных и несколько входных данных, что может усложнить машинное обучение. Можно сказать, что такая машина подвергается контролируемому обучению.
Подумайте о наборе данных, в котором есть показатели удержания учащихся в классе в сравнении с такой информацией, как количество часов, потраченных на учебу, контрольные отметки и вовлеченность в классе. Теперь представьте себе машину, работающую с этими данными и создающую модель, которая предсказывает, насколько хорошо новый учащийся успевает, на основе исходных данных.
Классификация. Классификация — это метод машинного обучения, обычно используемый для классификации и выделения отдельных подмножеств в данных, чтобы сообщить аналитикам, какие условия приводят к результату. Выходные данные в этом случае не являются числовыми и принадлежат классу.
Общие методы классификации включают древовидную структуру, таблицы решений, байесовские классификаторы и многие другие алгоритмы. Используя методы классификации, вы можете определить, например, какие атмосферные условия приводят к дождям, какая концентрация различных элементов приводит к образованию определенного типа песка или даже какие условия приводят к тому, что человек лишается кредита.
Регрессия: – новаторский инструмент эрудита Фрэнсиса Гальтона. Проще говоря, регрессия представляет собой числовой метод машинного обучения, позволяющий связать выходные данные с входными данными с помощью уравнений.
В отличие от простых графических методов, уравнения которых можно найти в школьной тетради, уравнения регрессии в реальной жизни никогда не бывают такими простыми или упорядоченными. Только представьте, что вы сопоставляете движение цены акции в течение нескольких лет с рядом факторов и строите из этого уравнение. Это сложнее, чем кажется, но регрессию можно использовать для разработки уравнений для реальных случаев, таких как прогнозирование взаимодействия потребителей с продуктом через онлайн-взаимодействия.
Перекрестная проверка: - Перекрестная проверка относится к количеству делений или сгибов, которые выполняются в данных, которые будут использоваться для тестирования или обучения. У вас может возникнуть соблазн подумать: «Почему бы просто не использовать только обучающие данные и получить 100 % точность?».
Использование модели с более высоким соотношением обучения к тестированию обычно дает хорошую точность, поскольку для сравнения используется меньший набор тестов, но в конечном итоге он терпит неудачу при применении к новым данным в будущем.
Что делает модель машинного обучения хорошей 
При этом предпочтительнее иметь хорошее соотношение между тестированием и обучением, поскольку в большинстве симуляций используется десятикратная перекрестная проверка. Другим аспектом является проблема предубеждений и отклонений. Смещения показывают, насколько значения отличаются от целевых значений, а отклонения связаны с различием между самими значениями.
Любая хорошая программа машинного обучения попытается свести к минимуму и то, и другое. в большинстве случаев возникает компромисс между ними, чтобы правильно идентифицировать каждый экземпляр данных.
ОТСЛЕЖИВАНИЕ МАШИННОГО ОБУЧЕНИЯ В РЕАЛЬНОЙ ЖИЗНИ
Помимо более прибыльных случаев использования машинного обучения в беспилотном вождении автомобилями и индивидуальной помощью, о которых мы поговорим в следующем сегменте, давайте пройдемся по некоторым простым случаям прямо из истории данных:-
Google Flu Predictor: Начав проект по сбору поисковых данных в течение длительного периода времени, Google опубликовал результаты динамики поиска лекарств от гриппа во всем мире. Алгоритм поддерживался серией машин опорных векторов (SVM), которые измеряли поисковые индексы по ряду параметров.
Основываясь на прошлых данных, компания смогла выделить закономерности в течение года и сконцентрироваться на регионах, в которых было зарегистрировано наибольшее количество таких запросов. Это позволило компании построить теоретическую модель, которая предсказала значения для поисковых запросов о гриппе в ближайшие месяцы и, таким образом, предупредила чиновников здравоохранения о необходимости запасаться лекарствами в регионах с наибольшим количеством поисковых запросов.
Случай CHD Университета Огайо: - Вот забавное небольшое упражнение по машинному обучению, в котором используется хорошо известная техника, называемая логистической регрессией. Аналитики из Университета Огайо потратили много лет на изучение заболеваемости ишемической болезнью сердца (ИБС) у пациентов, классифицированных по возрастным группам, полу, расе, образу жизни и диетическим привычкам.
Логистическая регрессия — это особый тип метода машинного обучения, в котором выходная переменная может принимать два значения. В этом случае вывод 1 означал, что у пациента будет диагностирован ИБС, а 0 — нет. Сложность заключалась в том, чтобы проанализировать и подтвердить, будет ли статистический алгоритм хорошо работать с пациентами в будущем, поскольку исследование проводилось, когда компьютерные технологии не были такими продвинутыми.
Благодаря возможностям SAS удалось создать предикторную модель с уменьшенной частотой ошибок, которая помогает понять, что привело к заболеванию. Хотите знать лучшую часть? Набор данных, учебные материалы и кодирование программного обеспечения доступны бесплатно в онлайн-модуле университета.
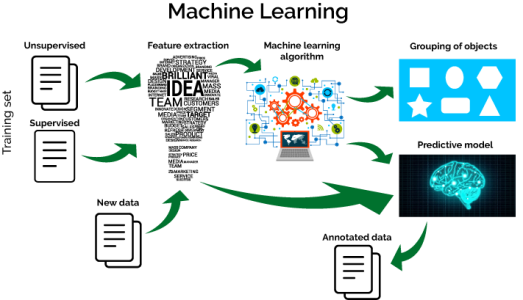
Типичный рабочий процесс машинного обучения
Онлайн-поисковые системы. Весь онлайн-контент распространяется среди бесконечного множества веб-сайтов. Так как же получается, что вы все еще получаете именно то, что является вашим поисковым запросом, за такое короткое время?
Ответ кроется в программном обеспечении. Поисковые системы используют алгоритм «обратных ссылок», который фиксируется на мета-тегах, индексах URL и индексах NAP любого веб-сайта в Интернете (забавный факт: предполагаемое имя Google было выбрано как BackRub). Эти обратные ссылки работают как крошечные криперы, которые просачиваются через Интернет в поисках уникальных тегов и доставляют контент. В большинстве из них используются расширенные системы классификации и иерархии.
Программное обеспечение для веб-скрейпинга, которое хранит пользовательские данные и файлы cookie, также работает аналогичным образом, хотя и с совсем другое предназначение. Вы можете загрузить Twitter или Facebook API и посмотреть, как программное обеспечение собирает данные о пользователях за считанные секунды. Думайте об этом как о форме обработки данных.
Система рекомендаций Netflix. Одной из причин, по которой Netflix стал поистине уникальным средством просмотра, является то, что служба потоковой передачи разработана таким образом, чтобы зритель как можно дольше оставался приклеенным к своим сетам. Идея здесь состоит в том, чтобы рекомендовать шоу и фильмы, которые точно соответствуют содержанию истории пользователя.
Netflix даже опубликовал свои пользовательские данные для использования в сезонных соревнованиях, чтобы понять, как именно они работают. Модели со всего мира объединились, чтобы создать механизм рекомендаций, который работает незаметно, пока зрители смотрят.
Многие из таких механизмов обычно используют расширенные алгоритмы классификации, такие как C45, PART, пни решений, таблицы решений и многоуровневые перцептоны.
ПЕРЕХОД К ПРОДВИНУТЫМ ДЕЛАМ
Большинство данных, которые вы видели до сих пор, основаны на простых инструментах и алгоритмах машинного обучения. Но по мере развития технологий растет и потребность в сложных случаях, которые могут помочь машине быстрее обучаться и продолжать работу без какого-либо контроля со стороны разработчиков.
Звучит как создание самодумающих машин, работающих на ИИ, но нет, это просто машины, которые используются с пользой. Некоторые продвинутые концепции машинного обучения охватывают идеи байесовской кластеризации, обучения с несколькими экземплярами, локально требуемой линейной регрессии, индукции модельного дерева и часто обсуждаемой многоуровневой нейронной сети.
Если вы когда-нибудь видели схему нейронной сети, то увидели бы, что она имеет несколько более мелких узлов, которые пересекаются с другими узлами, которые на выходе объединяются. В каждом узле и стыке работают еще более сложные алгоритмы, такие как градиентный спуск, стохастический градиент, линейная цепь, Левенберг-Марквардт, сигмоидальный.

Эти более мелкие узлы заполняются собственными весами и смещениями, установленными аналитиком. Еще одним важным параметром, который необходимо контролировать, является количество симуляций или итераций, которые могут повлиять на окончательную точность модели, а также определить, насколько хорошо модель соответствует будущим входным данным.
Возможно, вам интересно, где используются эти сложные инструменты машинного обучения, и ответ: практически везде.
Обработка естественного языка (NLP): — Обработка естественного языка — это растущая часть индустрии машинного обучения, которая просочилась через ИИ, маркетинг и контекстуальный анализ. По всему Интернету вы найдете файлы корпусов, в которых хранятся гигабайты текстовых и голосовых данных от обычных потребителей. НЛП лучше всего использовать в качестве резервного агента по обслуживанию клиентов, который быстро передает клиентам информацию, которую они ищут.
Что еще более важно, он используется как средство для интерпретации текстов со многих языков (в основном в юридических кругах) и преобразования их в простой язык, чтобы помочь людям понять их. Microsoft тоже когда-то реализовала аналогичный проект под названием Tosh, который был выпущен в виде онлайн-бота, языковые способности которого улучшались по мере того, как все больше и больше людей общались с ним, в конечном итоге достигая возможностей самообучения.
Безопасность и обнаружение вредоносных программ. Компания Deep Instinct совместно с Лабораторией Касперского разработала отличный самообучающийся алгоритм, который использует высокопроизводительную машину поддержки векторов с SMO (упрощенная минимальная оптимизация). В результате появилось программное обеспечение, которое «самообучается» обнаруживать мошеннические и вредоносные программы в файлах.
Вредоносное ПО имеет тенденцию развиваться с точки зрения своего кода с лишь незначительными изменениями от итерации к итерации. Таким образом, становится важным иметь систему безопасности, которая одновременно развивается для проверки доступа к облаку, обнаружения аномалий и прогнозирования нарушений безопасности.
Финансовая торговля. Трудная основа для работы, но несколько команд энтузиастов машинного обучения создали программы-предикторы, которые изучают ценовые модели определенных акций по набору параметров. Многие из этих программ, как правило, используют наивный байесовский классификатор, дополненный методами регрессии. Некоторые из наиболее точных из них попадают в прайс-лист лучших продавцов и дистрибьюторов.
Однако следует понимать, что причина, по которой он называется «наивным», заключается в том, что он работает на основе предположения, что все входные параметры независимы друг от друга. Тем не менее, такие программы по-прежнему популярны среди трейдеров и хеджеров в Интернете.
БУДУЩЕЕ И ПОСЛЕДНИЕ
Умные автомобили, системы персонализированного маркетинга и автоматизированные каналы доставки лекарств — это лишь некоторые из немногих достижений, обучение подарило миру. Когда мы учим машины «учиться», они учат нас, как решать некоторые из наиболее насущных проблем современности.