

Графики пламени процессора Lua-Land в OpenResty XRay
22 ноября 2022 г.
Код Lua, работающий внутри серверов OpenResty или Nginx, в настоящее время очень распространен, поскольку люди хотят, чтобы их неблокирующие веб-серверы были одновременно производительными и гибкими. Некоторые люди используют Lua для очень простых задач, таких как проверка и изменение определенных заголовков запросов и тел ответов, в то время как другие люди используют Lua для создания очень сложных веб-приложений, программного обеспечения CDN и шлюзов API. Lua известен своей простотой, небольшим объемом памяти и высокой эффективностью выполнения, особенно при использовании JIT-компиляторов, таких как LuaJIT. . Но иногда код Lua, работающий поверх серверов OpenResty или Nginx, может потреблять слишком много ресурсов ЦП из-за ошибок программиста, обращения к дорогостоящему коду библиотеки C/C++ или по другим причинам.
Лучший способ быстро найти все узкие места производительности ЦП в онлайн экземпляре OpenResty или Nginx — это инструмент выборки графа пламени процессора Lua-land, предоставляемый Продукт OpenResty XRay. Он не требует каких-либо изменений в целевых процессах OpenResty или Nginx и не оказывает заметного влияния на рабочие процессы.
В этой статье вы познакомитесь с идеей графиков пламени процессора Lua и используете OpenResty XRay для создания реальных графиков пламени для нескольких небольших и автономных Примеры Луа. Мы выбираем небольшие примеры, потому что гораздо проще предсказать и проверить результаты профилирования. Та же идея и инструменты одинаково хорошо применимы к самым сложным приложениям Lua. И мы добились больших успехов в использовании этой техники и визуализации, чтобы помочь нашим корпоративным клиентам с очень загруженными сайтами и приложениями за последние несколько лет.
Что такое Flame Graph
Flame-графики – это метод визуализации, изобретенный Бренданом Греггом, чтобы показать количественное распределение системных ресурсов или показателей производительности. по всем путям кода в целевом программном обеспечении.
системный ресурс или метрика может включать время ЦП, время вне ЦП, использование памяти, использование диска, задержку или любые другие параметры, которые вы можете себе представить.
Пути кода здесь определяются обратными трассировками в коде целевого программного обеспечения. След обычно представляет собой стек фреймов вызовов функций, как в выводе команды bt GDB и в сообщении об ошибке исключения программы Python или Java. Например, ниже приведен пример обратной трассировки программы на Lua:
C:ngx_http_lua_ngx_timer_at
at
cache.lua:43
cache.lua:record_timing
router.lua:338
router.lua:route
v2_routing.lua:1214
v2_routing.lua:route
access_by_lua.lua:130
В этом примере стек Lua растет от базового фрейма access_by_lua.lua:130 до верхнего фрейма C:ngx_http_lua_ngx_timer_at. На нем ясно показано, как различные функции Lua или C вызывают друг друга, формируя приблизительное представление «пути кода».
Когда мы говорим «все пути кода», мы на самом деле подразумеваем это со статистической точки зрения, а не буквально повторяем каждый отдельный путь кода в программе. Очевидно, что последнее было бы непозволительно дорого сделать в реальности из-за комбинаторных взрывов. Мы просто следим за тем, чтобы все пути выполнения кода с нетривиальными накладными расходами отображались на наших графиках, и мы могли с достаточной уверенностью определить их стоимость в количественном выражении.
В этой статье мы просто сосредоточимся на типах графиков пламени, которые показывают, как время ЦП (или ресурсы ЦП) количественно распределяется по всем путям кода Lua в целевом процессе (или процессах) OpenResty или Nginx, отсюда и название «Lua- Графики пламени ЦП земли».
На заголовке этой статьи показан пример графика пламени, и мы увидим еще несколько в следующих частях этого поста.
Почему Flame Graphs
Flame Graph — отличный способ показать "общую картину" всех узких мест в количественном выражении на одном небольшом графике, независимо от того, насколько сложно целевое программное обеспечение.
Традиционные профилировщики обычно бросали пользователю в лицо массу деталей и цифр. И пользователь может утратить представление о картине в целом и лезть в кроличьи норы за вещами, которые на самом деле не имеют значения. Еще одним недостатком традиционных профилировщиков является то, что они просто дают вам задержки всех функций, в то время как контекст этих вызовов функций трудно увидеть, не говоря уже о том, что пользователь также должен различать исключительное время и инклюзивное время вызова функции.
С другой стороны, Flame Graphs может очень компактно втиснуть большой объем информации в график ограниченного размера (обычно умещающийся на одном экране). Пути кода, которые не имеют значения, исчезают естественным образом, в то время как действительно важные пути кода выделяются. Не больше и не меньше, только нужное количество информации для пользователя.
Как читать Flame Graph
Flame Graphs может быть немного сложно читать новичку. Но с небольшим руководством пользователь сочтет это интуитивно понятным. Flame Graph — это двумерный график. Ось Y показывает контекст кода (или данных), т. е. следы целевого языка программирования, а ось X показывает, какой процент системных ресурсов занимает конкретный след. Полная ось X обычно означает 100% системных ресурсов (например, процессорного времени), затраченных на целевое программное обеспечение. Порядок следования вдоль оси x обычно не имеет значения, поскольку они обычно просто сортируются по именам функциональных кадров в алфавитном порядке. Однако есть исключения, когда я изобрел тип графиков пламени с временными рядами, где ось X на самом деле означает ось времени, а порядок обратных следов соответствует порядку времени. В этой статье нас интересуют только классические графы пламени, где порядок по оси x не имеет никакого значения.
Лучший способ научиться читать флейм-граф — это читать примеры флейм-графов. Ниже мы увидим несколько примеров с подробным объяснением приложений Lua OpenResty и Nginx.
Простые примеры Lua
В этом разделе мы рассмотрим несколько простых примеров Lua с очевидными характеристиками производительности и будем использовать OpenResty XRay для профилирования реальные процессы nginx для отображения графиков пламени процессора Lua-land и проверки поведения производительности на графиках. Мы проверим различные случаи, например, с включенной компиляцией JIT для кода Lua и без нее, а также вызов кода Lua во внешний код библиотеки C.
JIT-компилированный код Lua
Сначала мы исследуем пример программы Lua с включенной компиляцией JIT (которая включена по умолчанию в LuaJIT).
Давайте рассмотрим следующее автономное приложение OpenResty. Мы будем использовать этот пример в этом разделе с небольшими изменениями для разных случаев.
Сначала мы подготавливаем макет каталога приложений:
mkdir -p ~/work
cd ~/work
mkdir conf logs lua
Затем мы создаем файл конфигурации conf/nginx.conf следующим образом:
master_process on;
worker_processes 1;
events {
worker_connections 1024;
}
http {
lua_package_path "$prefix/lua/?.lua;;";
server {
listen 8080;
location = /t {
content_by_lua_block {
require "test".main()
}
}
}
}
Здесь мы загружаем внешний модуль Lua с именем test и немедленно вызываем его функцию main в нашем обработчике Lua для местоположения /t. Мы используем директиву lua_package_path, чтобы добавить каталог lua/ в модуль Lua. пути поиска, поскольку вскоре мы поместим вышеупомянутый Lua-модуль test в lua/.
Модуль test Lua определен в файле lua/test.lua следующим образом:
local _M = {}
local N = 1e7
local function heavy()
local sum = 0
for i = 1, N do
sum = sum + i
end
return sum
end
local function foo()
local a = heavy()
a = a + heavy()
return a
end
local function bar()
return (heavy())
end
function _M.main()
ngx.say(foo())
ngx.say(bar())
end
return _M
Здесь мы определяем функцию Lua с большим объемом вычислений, heavy(), которая вычисляет сумму чисел от 1 до 10 миллионов (1e7). Затем мы дважды вызываем эту функцию heavy() в функции foo() и только один раз в функции bar(). Наконец, функция входа в модуль _M.main() вызывает foo и bar только один раз по очереди и выводит их возвращаемые значения соответственно Тело ответа HTTP через ngx.say.
Интуитивно понятно, что для этого обработчика Lua функция foo() будет занимать ровно вдвое больше процессорного времени, чем функция bar(), потому что foo() дважды вызывает heavy(), тогда как bar() вызывает heavy() только один раз. Мы можем легко проверить это наблюдение на графиках пламени процессора Lua, выбранных OpenResty XRay ниже.
Поскольку в этом примере мы не затрагивали настройки JIT-компилятора LuaJIT, JIT-компиляция включена по умолчанию, поскольку современные версии платформы OpenResty всегда используют LuaJIT в любом случае (поддержка стандартного интерпретатора Lua 5.1 давно удалена).
Теперь мы можем запустить это веб-приложение OpenResty следующим образом:
cd ~/work/
/usr/local/openresty/bin/openresty -p $PWD/
при условии, что OpenResty установлен в /usr/local/openresty/ в текущей системе (это место установки по умолчанию).
Чтобы сделать это приложение OpenResty загруженным, мы можем использовать такие инструменты, как ab и weighttp для загрузки URI http://localhost:8080/t или генератор нагрузки, предоставляемый продуктом OpenResty XRay. В любом случае, пока рабочий процесс nginx целевого приложения OpenResty занят, мы можем получить следующий график пламени процессора Lua-land в OpenResty XRay:

Из этого графика мы можем сделать следующие выводы:
- Все трассировки Lua на этом графике исходят из одной и той же точки входа,
content_by_lua(nginx.conf:24), что и ожидалось.
2. На графике показаны в основном два пути кода, которые
content_by_lua -> test.lua:основной -> test.lua:бар -> test.lua:тяжелый -> трассировка#2:test.lua:8
а также
content_by_lua -> test.lua:основной -> test.lua:foo -> test.lua:тяжелый -> трассировка#2:test.lua:8
Единственная разница между этими двумя путями кода — foo и bar. Это также ожидается.
3. Путь кода слева, включающий bar, вдвое меньше, чем путь кода справа, включающий foo. Другими словами, их отношение ширины по оси X составляет 1:2, что означает, что путь кода bar занимает всего 50% времени, затрачиваемого foo. Наведя указатель мыши на кадр (или прямоугольник) test.lua:bar на графике, мы увидим, что он занимает 33,3% от общего числа выборок (или общего времени процессора), в то время как Кадр test.lua:foo показывает 66,7%. Очевидно, что он очень точен по сравнению с нашими прогнозами, даже несмотря на выборочный и статистический подход.
4. Мы не увидели на графике других путей кода, таких как ngx.say(), поскольку такие пути кода просто занимают слишком мало процессорного времени по сравнению с двумя доминирующими путями кода Lua, включающими heavy( ). Тривиальные вещи — это просто шумы, которые не привлекут наше внимание на графике пламени. Мы всегда концентрируемся на действительно важных вещах и не можем отвлекаться.
5. Верхние кадры для обоих путей кода (или обратных трасс) одинаковы, то есть trace#2:test.lua:8. Это не настоящий кадр вызова функции Lua, а скорее псевдокадр, указывающий, что он выполняет скомпилированный JIT путь кода Lua, который в терминологии LuaJIT называется «трассировкой» (потому что LuaJIT — JIT-компилятор трассировки). И эта «трассировка» имеет идентификатор 2 и путь к скомпилированному коду Lua, начиная с строки исходного кода Lua 8 файла test.lua. test.lua:8 — это строка кода Lua:
сумма = сумма + i
Замечательно видеть, что наш неинвазивный инструмент выборки может получать такие точные графики пламени из стандартной бинарной сборки OpenResty без каких-либо дополнительных модулей, модификаций или специальных флагов сборки. Инструмент вообще не использует какие-либо специальные функции или интерфейсы среды выполнения LuaJIT, даже функция LUAJIT_USE_PERFTOOLS или ее встроенный профилировщик. Вместо этого он использует передовые технологии динамической трассировки, которые просто считывают информацию, уже имеющуюся в самом целевом процессе. . И мы можем получить достаточную информацию даже из скомпилированного JIT кода Lua.
Подать заявку на пробную версию OpenResty XRay СЕЙЧАС и получить БЕСПЛАТНЫЙ отчет
Интерпретируемый код Lua
Интерпретированный код Lua обычно может привести к идеально точным обратным трассировкам и графикам пламени. Если инструмент выборки может нормально обрабатывать JIT-компилированный код Lua, то он может работать только лучше при работе с интерпретируемым кодом Lua. Одна интересная особенность интерпретатора LuaJIT заключается в том, что интерпретатор почти полностью написан на созданном вручную ассемблере (конечно, LuaJIT вводит свой собственный синтаксис языка ассемблера под названием DynASM).
В нашем продолжающемся примере Lua мы просто добавляем следующий фрагмент nginx.conf внутрь блока конфигурации server {}:
init_by_lua_block {
jit.off()
}
А затем перезагрузите или перезапустите серверные процессы и по-прежнему сохраняйте загрузку трафика.
На этот раз мы получаем следующий график пламени процессора Lua-land:

Этот график очень похож на предыдущий в следующем:
- Мы по-прежнему видим только два основных пути кода:
barиfoo. - Путь кода
barпо-прежнему занимает примерно одну треть общего времени ЦП, а путьfooпо-прежнему занимает почти всю оставшуюся часть (т. е. около двух третей) . - Точкой входа для всех путей кода, показанных на графике, является элемент
content_by_lua.
Однако этот график по-прежнему имеет важное отличие: кончики путей кода (или обратных следов) больше не являются «следами». Это ожидаемо, поскольку на этот раз пути кода Lua, скомпилированные JIT, невозможны. Подсказки или верхние фреймы теперь являются функциональными фреймами C, такими как lj_BC_IFORL и lj_BC_ADDVV. Эти кадры функций C, отмеченные префиксом C:, на самом деле не являются функциями C как таковыми. Вместо этого они представляют собой фреймы ассемблерного кода, соответствующие обработчикам интерпретации байт-кода LuaJIT, специально аннотированным такими символами, как lj_BC_IFORL. . Естественно, lj_BC_IFORL предназначен для инструкции LuaJIT байт-кода IFORL, а lj_BC_ADDVV предназначен для инструкции байт-кода ADDVV. IFORL предназначен для интерпретируемых циклов Lua for, а ADDVV — для арифметических сложений. Все это ожидается в соответствии с нашей функцией Lua heavy(). Существуют также некоторые вспомогательные процедуры сборки, такие как lj_meta_arith и lj_vm_foldarith.
Глядя на процентные значения для этих кадров функций, мы также можем понять, как процессорное время распределяется внутри LuaJIT виртуального машину и интерпретатор, прокладывая путь к оптимизации самой виртуальной машины и интерпретатора.
Вызов внешних функций C/C++
Код Lua очень часто вызывает внешние библиотечные функции C/C++. Мы также хотим видеть их пропорциональные доли на графике пламени процессора Lua-land, потому что такие вызовы функций C в любом случае инициируются из кода Lua. Это также то, где профилирование на основе динамической трассировки действительно блестяще, где такие внешние вызовы функций C никогда не станут слепыми зонами для профилировщика1.
Давайте изменим функцию Lua heavy() в нашем текущем примере следующим образом:
local ffi = require "ffi"
local C = ffi.C
ffi.cdef[[
double sqrt(double x);
]]
local function heavy()
local sum = 0
for i = 1, N do
-- sum = sum + i
sum = sum + C.sqrt(i)
end
return sum
end
Здесь мы сначала используем API LuaJIT FFI для объявления стандартной библиотечной функции C sqrt(), а затем вызываем непосредственно из Lua-функции heavy(). Это должно отображаться на соответствующих графиках пламени процессора Lua-land.
На этот раз мы получили следующий график пламени:

Интересно, что мы действительно видим кадр функции C C:sqrt, появляющийся как подсказки этих двух основных путей кода Lua. Также стоит отметить, что мы по-прежнему видим кадры trace#N вверху, что означает, что наш FFI вызовы функции C также могут быть скомпилированы JIT (на этот раз мы удалили оператор jit.off() из init_by_lua_block директива).
График пламени на линейном уровне
Предыдущие флейм-графы, которые мы видели, являются флейм-графами на уровне функций, потому что почти все фреймы функций, показанные на флейм-графах, имеют только имена функций, а не исходные строки, инициирующие вызовы.
К счастью, инструменты профилирования Lua-land OpenResty XRay также могут генерировать имена файлов исходных строк Lua и номера строк на уровне строк. графики пламени, по которым мы можем легко узнать, какие исходные строки Lua горячие. Ниже приведен такой пример для нашего текущего примера Lua:

Мы видим, что теперь над каждым соответствующим фреймом имени функции добавлен еще один фрейм исходной строки. Например, внутри функции main в строке 32 файла test.lua происходит вызов функции foo(). А внутри функции foo() в строке 22 файла test.lua есть вызов функции heave(), и и т. д.
Графики пламени на уровне строк очень полезны для определения самых горячих строк исходного кода и операторов Lua. Это может сэкономить много времени, когда тело соответствующей функции Lua большое.
Несколько процессов
Обычно настраивается несколько рабочих процессов nginx для одного экземпляра сервера OpenResty или Nginx в системе с несколькими ядрами ЦП. Инструменты профилирования OpenResty XRay поддерживают одновременную выборку всех процессов в определенной группе процессов. Это полезно, когда входящий трафик умеренный и распределяется между произвольными рабочими процессами nginx.
Сложные приложения Lua
Мы также можем получить графы пламени процессора Lua-land из очень сложных приложений OpenResty/Lua в дикой природе. Например, ниже приведен график пламени процессора Lua-land, выбранный на одном из наших серверов мини-CDN, на котором запущен наш продукт OpenResty Edge, которое представляет собой сложное приложение Lua, включающее в себя динамический шлюз CDN, DNS-сервер с географической привязкой и брандмауэр веб-приложений (WAF):

Из этого графика видно, что WAF занимает большую часть процессорного времени, в то время как встроенный DNS-сервер также занимает значительную часть. Наша глобальная сеть мини-CDN также защищает и ускоряет работу наших собственных веб-сайтов, таких как openresty.org и openresty.com.
Он также может анализировать программное обеспечение шлюза API на основе OpenResty, такое как Kong.
Накладные расходы на выборку
Поскольку мы используем подход, основанный на выборке, а не полный инструментарий, накладные расходы, связанные с выборкой для создания графиков пламени процессора Lua-land, обычно незначительны, что делает такие инструменты пригодными для использования в производственной или онлайн-среде. Объем данных и нагрузка на ЦП минимальны.
Если мы загружаем целевой рабочий процесс nginx запросами с постоянной скоростью, то использование ЦП целевым процессом изменяется, в то время как выборка графа пламени ЦП Lua-land часто выполняется следующим образом:
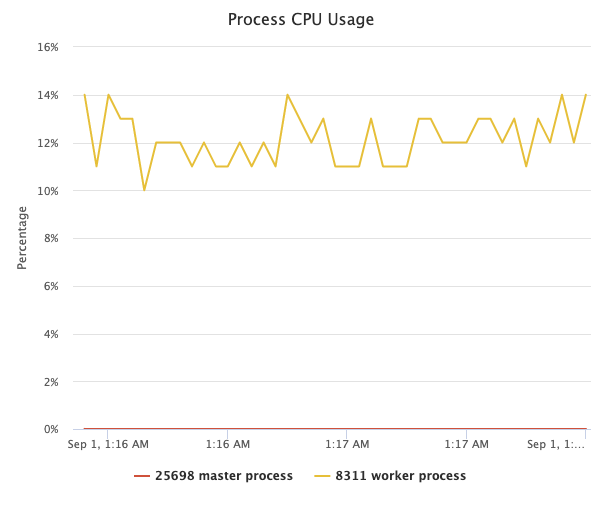
Эта линейная диаграмма использования ЦП также создается и визуализируется с помощью OpenResty XRay автоматически.
А затем мы вообще прекращаем выборку, и кривая использования ЦП того же рабочего процесса nginx очень похожа:
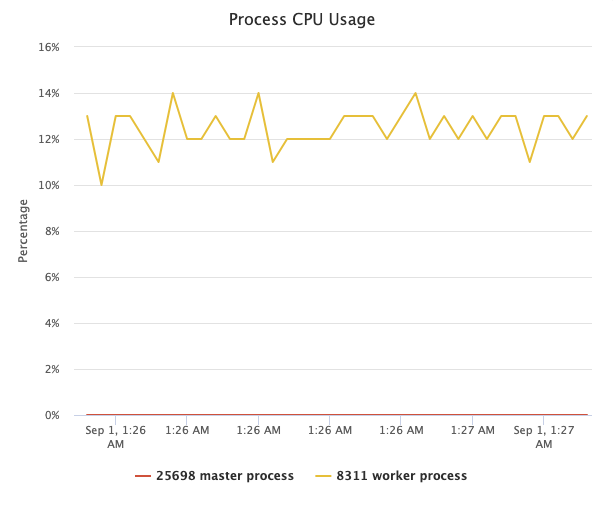
Мы не можем увидеть никакой разницы между этими двумя кривыми невооруженным глазом. Таким образом, стоимость профилирования и выборки действительно очень мала.
Когда инструменты не используют выборку, влияние на производительность строго равно нулю, поскольку мы все равно ничего не меняем в целевых процессах.
Безопасность
Поскольку мы используем технологии динамической трассировки, мы не меняем никакого состояния в целевых процессах, ни единого бита информации2. Это гарантирует, что целевой процесс ведет себя (почти) точно так же, как и в случае, когда выборка не выполняется. Это гарантирует, что надежность целевого процесса (отсутствие неожиданных изменений поведения или сбоев процесса) и поведение не будут скомпрометированы инструментом профилирования. Они остаются такими же, как если бы никто не смотрел, точно так же, как при съемке рентгеновского снимка на фоне живого животного.
Традиционные продукты Application Performance Manager (APM) могут потребовать загрузки специальных модулей или подключаемых модулей в целевое программное обеспечение или даже кровавых исправлений или внедрения машинного кода или байтового кода в исполняемый файл или пространство процесса целевого программного обеспечения, что серьезно ставит под угрозу стабильность и правильность пользовательских систем. .
По этим причинам эти инструменты безопасно использовать в производственных средах для анализа действительно сложных проблем, которые сложно воспроизвести в автономном режиме.
Совместимость
Инструмент выборки графа пламени процессора Lua-land, предоставляемый продуктом OpenResty XRay, поддерживает любые двоичные файлы OpenResty или Nginx, включая скомпилированные самими пользователями с произвольными параметрами сборки, оптимизированными или неоптимизированными, с использованием режим GC64 или не-GC64 режим в библиотеке LuaJIT и т. д.
Серверные процессы OpenResty и Nginx, запущенные внутри контейнеров Docker или Kubernetes, также могут быть прозрачно проанализированы с помощью OpenResty XRay и идеальных графиков пламени процессора Lua-land. может быть отображено без проблем.
Наш инструмент также может анализировать консольные пользовательские программы Lua, запускаемые resty или luajit утилиты командной строки.
Мы также поддерживаем старые операционные системы Linux и старые ядра, такие как CentOS 6 с ядром 2.6.32.
Другие типы графиков пламени Lua-land
Как упоминалось ранее в этом посте, пламенные графики можно использовать для визуализации любых системных ресурсов или показателей производительности, а не только процессорного времени. Естественно, в нашем продукте OpenResty XRay есть и другие типы графов пламени на языке Lua, такие как графы пламени вне процессора, сборщик мусора (GC) диаграммы пламени размера объекта и пути ссылки на данные, новые диаграммы пламени распределения объектов GC, диаграммы пламени времени выдачи сопрограммы Lua, диаграммы пламени задержки ввода-вывода файлов и многое другое.
Мы расскажем об этих различных видах графиков пламени в будущих статьях нашего блога.
Заключение
В этой статье мы представляем очень полезную визуализацию Flame Graphs для профилирования производительности программного обеспечения. И мы внимательно изучили один конкретный тип пламенных графов, Lua-land CPU Flame Graphs, для профилирования приложений Lua, работающих поверх OpenResty и Nginx. Мы исследуем несколько небольших программ-примеров на Lua, используя реальные графики пламени, созданные OpenResty XRay, чтобы продемонстрировать силу наших инструментов выборки, основанных на динамической трассировке. технологии. И, наконец, мы смотрим на снижение производительности выборки и безопасность использования в Интернете.
Об авторе
Ичунь Чжан (дескриптор на Github: agentzh) является первоначальным создателем проекта с открытым исходным кодом OpenResty® и генеральным директором < a href="https://openresty.com/en/">OpenResty Inc..
Ичунь — один из первых сторонников и лидеров «технологии с открытым исходным кодом». Он работал во многих всемирно известных технологических компаниях, таких как Cloudflare, Yahoo!. Он является пионером в области «граничных вычислений», «динамической трассировки» и «машинного кодирования» с более чем 22-летним опытом программирования и 16-летним опытом работы с открытым исходным кодом. Ичунь хорошо известен в среде открытого исходного кода как руководитель проекта OpenResty®, который используется более чем в 40 миллионах доменов веб-сайтов по всему миру.
OpenResty Inc., стартап корпоративного программного обеспечения, основанный Ичуном в 2017 году, имеет клиентов из крупнейших компаний мира. Его флагманский продукт, OpenResty XRay, представляет собой неинвазивное средство профилирования и устранения неполадок, которое значительно улучшает и использует технологию динамической трассировки.
Будучи активным участником открытого исходного кода, Ичунь внес более миллиона строк кода в многочисленные проекты с открытым исходным кодом, включая ядро Linux, Nginx, LuaJIT, GDB, SystemTap, LLVM, Perl и т. д. Он также является автором более 60 библиотеки программного обеспечения с открытым исходным кодом.
Переводы
Мы предоставляем китайский перевод этой статьи на нашем blog.openresty.com.cn. Мы также приглашаем заинтересованных читателей делать переводы на другие естественные языки, если статья полностью переведена без каких-либо пропусков. Мы заранее благодарим их.
- Точно так же не будут слепыми зонами любые примитивные подпрограммы, принадлежащие самой ВМ. Таким образом, мы можем одновременно профилировать саму виртуальную машину. ↩︎
- Средство uprobes ядра Linux по-прежнему будет изменять некоторые второстепенные состояния памяти внутри целевого процесса совершенно безопасным способом (гарантируется ядро), и такие модификации полностью прозрачны для целевых процессов. ↩︎
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27156)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)