У нас есть сервис, взаимодействующий с внешним миром и очень высоконагруженный (мы прикинули и подготовились к 100 RPS). Назовем эту службу ServiceX, своего рода службу прокси-оркестратора. Этот сервис взаимодействует с набором наших внутренних сервисов и смотрит во внешний мир.
Мы тестировали этот сервис и думали, что готовы к высоким нагрузкам, но это оказалось не так. Да, нам удалось спасти сервис под обстрелом, и на это у нас ушло меньше двух дней.
Однако в результате мы осознали необходимость лучше готовиться к таким проблемам заранее, а не тогда, когда сервис засыпают 100 RPS, а бизнес терпит сбой.
Краеугольный камень проблемы
Как оказалось, эмулируемая нами нагрузка по записи составляет всего 5 % от нагрузки на ServiceX, а остальная часть нагрузки по записи приходится на другие системы позже.
Для лучшего понимания проиллюстрируем схематически
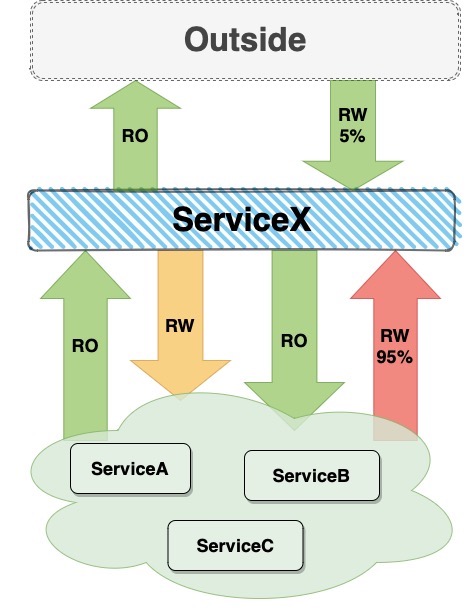
* Если заходит стрелка RO - ServiceX откуда-то читает - грузится на другой сервис * Если стрелка RO выходит - это нагрузка на ServiceX
* Зеленый - мы хорошо эмулировали * Желтый — «как-то эмулируется»: на стороне тестов других систем * Красный — не эмулируется вообще
Почему? Потому что после наших тестов, с точки зрения бизнеса, конечно, во внешний мир ничего не вышло. Служба выполнила запись в свою базу данных, и задание cron очистило ее, но после этого ничего не произошло.
В конце концов, проблема, обозначенная красной стрелкой, дорого нам обошлась. Как я уже писал, мы все исправили, но если бы мы знали об этой проблеме заранее, то проблемы бы не было, и мы бы все исправили раньше. В этой статье я не буду вдаваться в подробности того, как мы исправили сервис, изменив архитектуру и добавив сегментированные PostgreSQL - эта статья не об этом. Вместо этого речь идет о том, как теперь мы можем быть уверены, что действительно стали сильнее, устранили это узкое место и поняли, какие у нас есть варианты.
Общий список причин и проблем
- Для загрузки RW нужно создавать какие-то "моки", уводящие трафик записи куда-то "в сторону", что сложно.
- Код зарастает операторами if, что усложняет его поддержку.
- Репрезентативность теряется.
- В качестве альтернативы трем описанным выше сценариям тестовые данные будут записываться рядом с реальными данными, распространяться по системам, нарушать аналитику, занимать место и т. д.
Как только в коде появляется функция is_test_user(), большинство ваших тестов в той или иной мере становятся недостаточно репрезентативными. Вот почему в период высокой нагрузки на ServiceX мы не были должным образом подготовлены.
Стратегии тестирования распределенных систем
Постановка
- Во-первых, постановка не показательна. Формула «если мы можем обрабатывать 100 RPS на одном сервере, мы можем обрабатывать 1000 RPS на 10 серверах» здесь не работает. Почему? Хотя бы из-за теоремы CAP. Вообще об этом можно было бы написать целую отдельную статью, а здесь мы просто примем это как факт — распределенные системы масштабируются нелинейно.
- Необходимо много аппаратного обеспечения, что экономически неэффективно, так как практически требует копирования производственной среды, которую также необходимо обслуживать таким же образом. Так что постановка — не панацея.
- Невозможно протестировать географическое распределение.
Изоляция
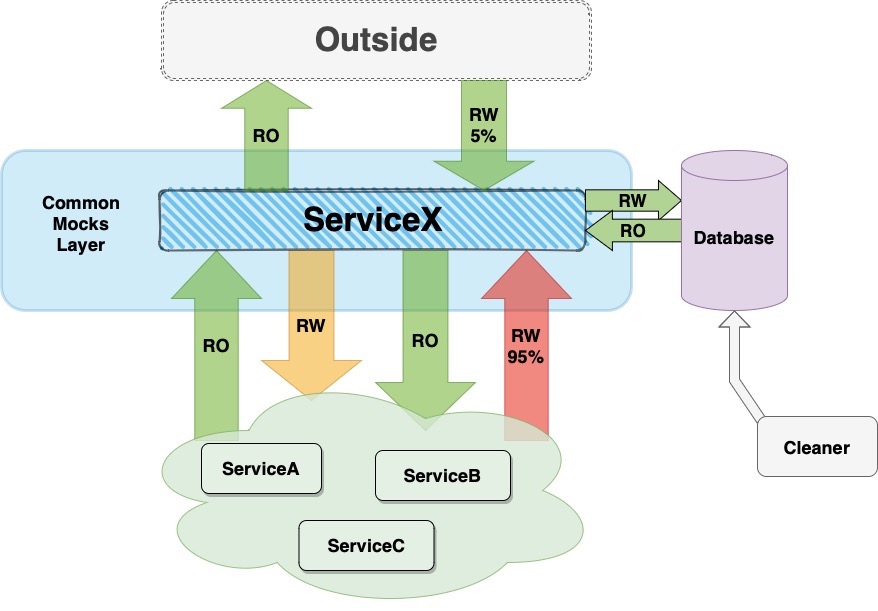
Необходимо создать структуру, позволяющую встроить в код службы и убедиться, что все исходящие и входящие данные эмулируются. То есть приходит реальная нагрузка, а потом все замыкается по какому-то периметру и дальше не идет.
Формально бизнес-логику мы описываем в тест-кейсах, а ServiceX загружается сам. Очиститель очищает базы данных по определенному контракту — необходимо производить запись в базы данных.
К сожалению, альтернативы этому нет, так как очень часто узким местом может стать база данных. В то же время это не должна быть отдельная база данных for_tests — она просто нерепрезентативна.
| Плюсы такого решения | Минусы такого решения | |----|----| | Можно проверить загрузку записи | Слабая репрезентативность | | Изолированное тестирование каждой системы | Сложно поддерживать в коде |
Однако, конечно, есть варианты развития этого пути
* Что такое слой макетов? Это библиотека/фреймворк (что-то вроде reflection или runkit), который не выпускает тестовые запросы вне службы, заменяя ответы?
* Это какое-то решение для обнаружения служб и/или балансировки нагрузки, которое отправляет тестовые запросы в специальные «фиктивные» модули?
Вероятно, каждый бизнес должен ответить на этот вопрос самостоятельно, так как эта ветка обсуждения зависит от конкретной архитектуры.
Эмуляция
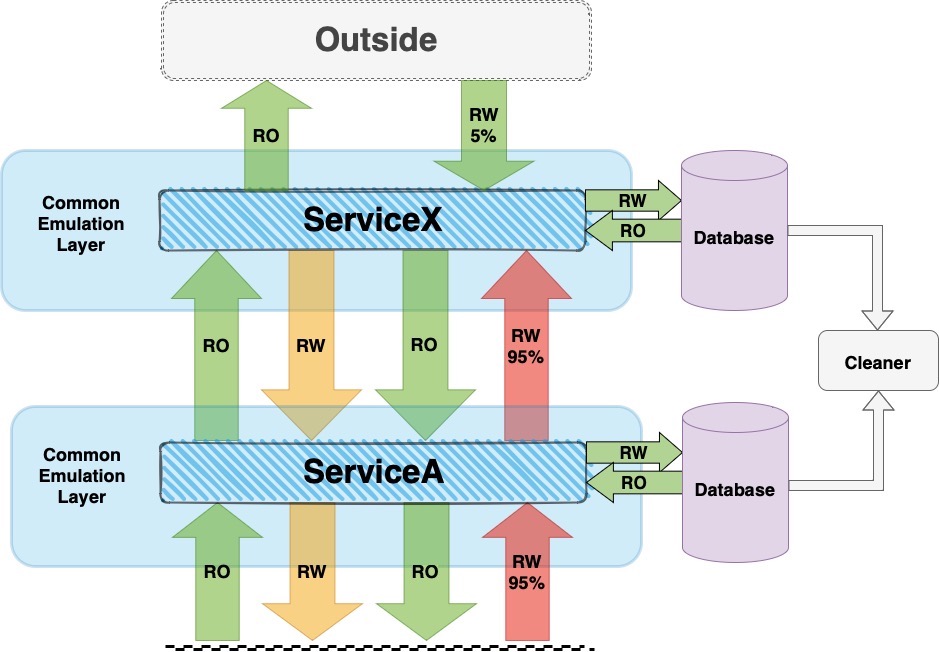
В этом методе ServiceX получает помеченный трафик (от ServiceA), никак не закрывается и идет дальше — также помеченный дальше вниз по системам. В этом сценарии общий уровень эмуляции проводит такой помеченный трафик и отслеживает его на уровне промежуточного программного обеспечения, например, отслеживая пересылку. Очиститель очищает базы данных по определенному контракту, как в примере выше.
| Плюсы такого решения | Минусы такого решения | |----|----| | Можно проверить загрузку записи | Трудно поддерживать (не как изоляция) | | Высокая представительность | Все сервисы должны его поддерживать |
Однако и здесь есть варианты развития этого пути
* Что такое слой эмуляции? Это решение для обнаружения служб и/или балансировки нагрузки и промежуточное ПО, которое помечает все тестовые запросы и отслеживает сохранение разметки, например трассировку?
Скорее всего, ответ на этот вопрос также зависит от конкретного бизнеса.
Технические детали
Наш ServiceX получает большинство событий через Kafka< /а>. Какие варианты доступны для тестирования асинхронных взаимодействий?
Самый простой способ
- Есть сроки, в течение которых мы можем обеспечить бизнес-процесс.
- Создайте показатель, отражающий количество входящих сообщений от Kafka.
- Узнайте у бизнес-клиентов, как долго мы можем прекратить доставку этих сообщений.
- Остановите Kafka, аккумулируйте задержку и измерьте скорость обработки этих сообщений.
| Плюсы | Минусы | |----|----| | Весьма актуально для структуры данных | Всегда проверяйте максимальную пропускную способность | | Всегда проверяйте максимальную пропускную способность | Может выполняться только вручную | | | Может повредить подключенные услуги | | | Не подходит для регулярного тестирования | | | SLA страдает для критически важных систем | | | Оценить скорость только по задержке |
Второй простой способ
- Использовать прокси-сервер Kafka-rest
- Создать обычный прокси или специально разработанный сервис с асинхронным взаимодействием
- Можно применять любую нагрузку
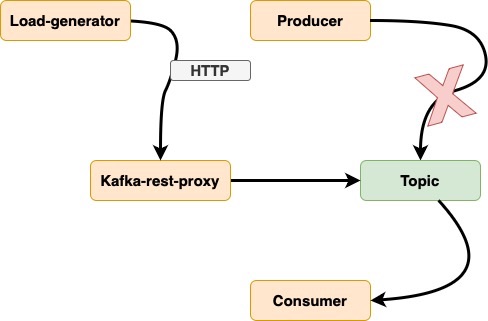
| Плюсы | Минусы | |----|----| | Может применять любую нагрузку | Высокие накладные расходы (REST→Kafka) | | Можно протестировать на производстве | Дополнительный сервисный уровень может повредить результатам | | | Оцените скорость с помощью показателей задержки и USE | | | Просмотр нагрузки на метрики RED по генератору | | | Возрастает сложность анализа |
Единый генератор нагрузки Kafka
Оба этих варианта нас не удовлетворили, и мы решили реализовать свое решение, которое назвали унифицированным генератором нагрузки Kafka.
Что может эта служба?
- Может добавлять любые данные в любую тему с заданной интенсивностью.
- Автоматически устанавливать тестовые флаги в заголовке
- Может использовать статистику из специальной темы и смешивать ее с результатами.
- Разрешает загрузку топологии.
- Просмотрите результат загрузки в метриках генератора
- Не требует специальных решений для сбора статистики.
Заключение
В этой статье мы подробно рассмотрели различные методы и стратегии тестирования производительности в распределенных системах, сосредоточив внимание на асинхронных взаимодействиях и использовании Kafka. Мы описали плюсы и минусы стадирования, изоляции, эмуляции и других подходов, что позволяет специалистам выбрать наиболее подходящий метод для своих проектов.
Мы также обсудили технические аспекты и представили два простых способа тестирования асинхронных взаимодействий, а также уникальное решение — единый генератор нагрузки для Kafka, предлагающий гибкие возможности и преимущества для тестирования.
Важно помнить, что разработка и сопровождение системы производительности — сложный и непрерывный процесс, и не существует универсального решения, которое подходило бы всем. Крайне важно проанализировать специфику конкретного бизнеса и системной архитектуры, чтобы выбрать наиболее оптимальный подход к тестированию производительности.