

Использование API-интерфейсов CUDA низкого уровня для динамической памяти Vattention
12 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 фон
2.1 Модели больших языков
2.2 Фрагментация и Pagegataturation
3 проблемы с моделью Pagegatatturetion и 3.1 требуют переписывания ядра внимания
3.2 Добавляет избыточность в рамки порции и 3,3 накладных расходов
4 понимания систем обслуживания LLM
5 Vattument: проектирование системы и 5.1 Обзор дизайна
5.2 Использование поддержки CUDA низкого уровня
5.3 Служение LLMS с ваттенцией
6 -й ваттиция: оптимизация и 6,1 смягчения внутренней фрагментации
6.2 Скрытие задержки распределения памяти
7 Оценка
7.1 Портативность и производительность для предпочтений
7.2 Портативность и производительность для декодов
7.3 Эффективность распределения физической памяти
7.4 Анализ фрагментации памяти
8 Связанная работа
9 Заключение и ссылки
5.2 Использование поддержки CUDA низкого уровня
Стандартный интерфейс распределения памяти графического процессора Cudamalloc не поддерживает пейджинг спроса, то есть, он выделяет виртуальную память и физическую память одновременно. Тем не менее, недавние версии CUDA предоставляют программистам мелкозернистый контроль над виртуальной и физической памятью [17, 35]. Мы используем эти низкоуровневые API в стиле.
5.2.1 CUDA Virtual Memory API.В таблице 3 представлен обзор высокого уровня API CUDA, которые позволяют отделить распределение виртуальной памяти от физической памяти (см. Самый левый столбец). Распределение гранулярности зависит от размера страницы, используемого графическим процессором, и размера виртуальной памяти
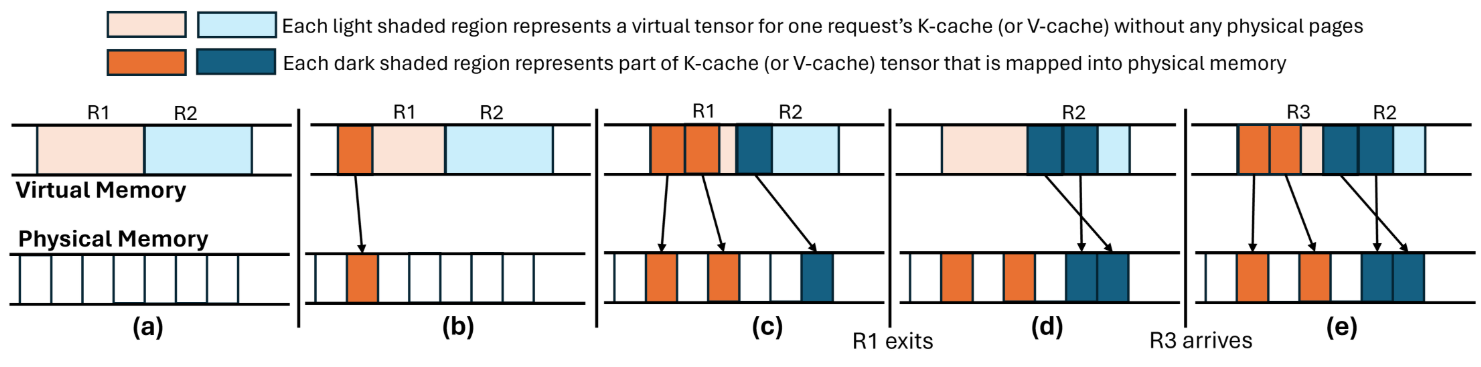
Буфер или ручка с физической памятью должны быть кратным гранулярностью распределения. Различные субрегионы буфера виртуальной памяти могут быть подкреплены физической памятью независимо от других субрегионов в этом буфере (пример см. В рисунке 7C). Для простоты мы ссылаемся на гранулярность, при которой физическая память выделяется как размер страницы.
5.2.2. Расширение распределения кэширования Pytorch:KV-Cache-это коллекция тензоров. В текущих структурах глубокого обучения, такими как Pytorch, тензор, выделенный через API, такие как Torch.empty, поставляется с предварительной физической памятью. Это связано с тем, что распределитель кэширования Pytorch использует интерфейс Cudamalloc для распределения памяти GPU (как виртуальной, так и физической). Опираясь на поддержку API низкого уровня со стороны CUDA, мы расширяем распределитель кэширования Pytorch, чтобы позволить приложению зарезервировать буфер виртуальной памяти для тензора, не совершая физическую память заранее. Мы называем тензоры, выделяемые через эти API как виртуальные тензоры.
5.2.3 Индексация квэша на уровне запроса:Обратите внимание, что каждый виртуальный тензор представляет собой k-cache (или v-cache) слоя для максимального размера партии B. В этих тензорах различные запросы занимают различные непересекающиеся субрегионы (скажем, подтяжки). Мы обнаруживаем подтянутель запроса с уникальным идентификатором целочисленного идентификатора, который находится в диапазоне от 0 до 𝐵-1 (обратите внимание, что не более 𝐵 запросы выполняются одновременно). Смещение k-cache (или v-cache) субпензора запроса в виртуальном тензоре всей партии является Requd × 𝑆 𝑆, где 𝑆 максимальный размер k-cache (или v-cache) запроса на рабочего. Повторный идентификатор запроса распределяется в результате пособия.
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
Авторы:
(1) Рамья Прабху, Microsoft Research India;
(2) Аджай Наяк, Индийский институт науки и участвовал в этой работе в качестве стажера в Microsoft Research India;
(3) Джаяшри Мохан, Microsoft Research India;
(4) Рамачандран Рамджи, Microsoft Research India;
(5) Ашиш Панвар, Microsoft Research India.
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)