

Уроки из тестирования моделей ИИ по глобальным данным повреждения
13 августа 2025 г.Таблица ссылок
Аннотация и I. Введение
II Набор данных
Iii. Методы
IV Эксперименты
V. Результаты
VI Выводы и ссылки
V. Результаты
Мы смотрим на все проведенные эксперименты и опишем количественные и качественные результаты обнаружения. Количественный балл сравнивает средний балл F1 на протяжении всего экспериментов. После этого мы смотрим на результат прогнозирования, наложенные на изображения для визуального анализа.
А. Количественный результат
Мы показываем совокупный график на рис. 10, с несколькими осями для всех экспериментов, проходящих со средним показателем F1 и гиперпараметрами для сравнения. Это также показывает прогресс, который мы достигли, поскольку мы продолжали вносить изменения в гиперпараметры во время оптимизации. Барсы - это размер партии, а черная пунктирная линия - это изменения скорости обучения во время экспериментов.
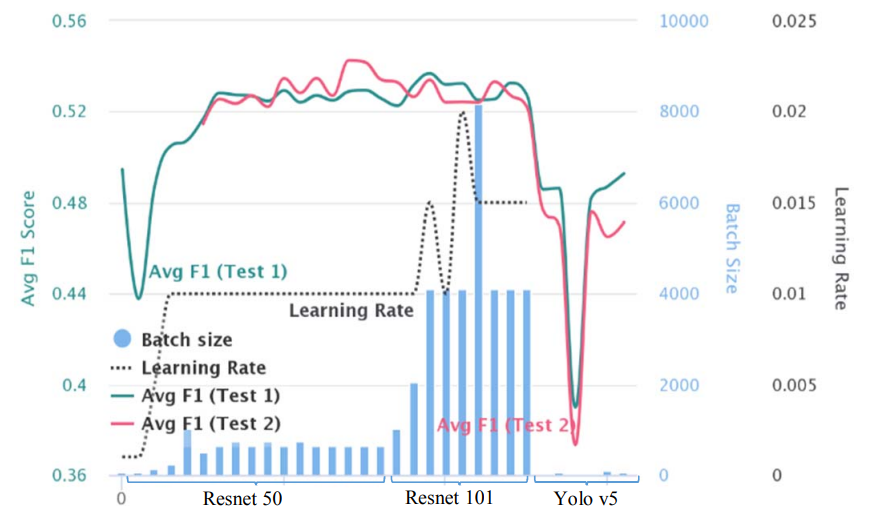
Одно наблюдение в оценке оценки AVG F1 (зеленый для теста 1, Red для теста 2) выделялось, заключается в том, что Resnet 101 [9] с высоким размером партии лучше при оценке теста 1, но не переносится на лучшие результаты при оценке теста 2. Resnet 50 [9] с более низким размером пакета порядка работает ниже, чем тест 1 Оценка RESNET 101, но оценивается лучше, чем RESNET 101 на Test 2 F1. Описание предназначено для обобщенного подхода, но мы видели, что мы всегда можем получить примерно 1,5% выгоду от точности, используя подход к модели в каждой стране.
Б. Качественные результаты
Мы показываем качественные результаты обнаружения, визуально наложенные на предоставленные тестовые изображения. Мы использовали модели, обученные (T+V) композиции данных для демонстрации результатов. Следовательно, изображения, выбранные для этого, взяты из 5% данных теста (T). Сама модель быстрее R-CNN [4] с сетью Resnet 50 [9] и FPN [5]. Мы увидим несколько хороших и неудачных случаев здесь
![Fig. 11. Successful results of detection on India_000052.jpg Test (T) data using Faster R-CNN [4] Resnet50+FPN [5] model. Trained on data from all countries. Multiple damage types like D20, D00 and D40 have been identified accurately. The model predicts small and medium bounding boxes with more than 70% classification accuracy. The lighting conditions are good and the textures in the captured image is clearly visible.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-rw133bw.png)
Мы показываем выходной выход на рис. 11, представляющий случай, когда все убытки были классифицированы и локализованы.

Образец на рис. 12, где дорога находится в поврежденном состоянии. Несмотря на то, что освещение хорошее на одном из изображений, и сеть выучила малые или средние повреждения, эта текстура распространяется по всей ширине дороги и может быть трудно выучить из -за отсутствия таких аннотаций.
V.

Вид неудач: На рис. 12 и рис. 13 мы видели изображения с неудачными обнаружениями. Основные проблемы на изображениях связаны с условиями низкого освещения, положениями крепления камеры, артефактами или тенями вокруг интересующих объектов и неспособности гео-финансирования пространственного диапазона для обнаружений, которые должны быть интересующей областью захвата, и не смотрят далеко вниз по дороге.
VI Выводы
В этой работе мы экспериментировали с небольшим количеством подходов и пошли с одной моделью, обученной данными по всей чешской, Японии и Индии по модели обнаружения конкретной страны из -за его упрощенного процесса развертывания. Тем не менее, существует аргумент против обобщения, учитывая обучение модели на страну, обеспечивает 1,5% улучшение по сравнению с обобщенной моделью. Сегментация дорожной поверхности в качестве этапа предварительной обработки не принесла пользы моделям обнаружения объектов, учитывая, что основанная на основе истины локализованная область не влияет фоновые особенности.
Мы сравниваем двухэтапную более быструю R-CNN [4] с одноэтапной моделью обнаружения Yolov5 [15] для оценки структуры и наблюдаем значительное улучшение среднего показателя F1 с двухэтапной сетью. В наших экспериментах с такими основными цепь, как FPN [5], Resnet 50 и Resnet 101 [9] в более быстром r-CNN [4], Resnet 101 выполняет и подходит для обучающих данных и лучшего тестирования 1 по сравнению с его аналогом Resnet 50, который работает лучше при тестировании 2 оценок.
В целом, мы видим, что с более крупным сетевым и большим размером партии модель подходит для набора оценки Test 1 и в противном случае в наборе данных оценки Test 2. Тем не менее, задача несбалансированного и ограниченного набора данных запрещает модели больше обучения. Именно здесь могут быть генеративные состязательные сети (GAN) [21] или более структурированный подход изоляции функций повреждения на дорожной поверхности с использованием предварительной обработки. Возможность изучения различных частей ущерба может быть полезна как в генерации, а также реконструкции таких артефактов в захваченных изображениях. Семантический набор данных сегментации выиграл бы, предоставив точную структуру и текстуру урона. Это могло привести к снижению ложных срабатываний за счет лучшего понимания убытков. Информация о глубине на изображении или пространственное ограждение на изображении может помочь ограничить обнаружения на ущерб, наблюдаемые ближе к точке зрения камеры.
Ссылки
[1] H. Maeda, Y. Sekimoto, T. Seto, T. Kashiyama и H. Omata, «Обнаружение и классификацию урона дорожного движения с использованием глубоких нейронных сетей с изображениями смартфонов», Компьютерная гражданская и инфраструктурная инженерия, 2018 год.
[2] D. Arya, H. Maeda, S.K. Ghosh, D. Toshniwal, A. Mraz, T. Kashiyama, & Y. Sekimoto. «Передача обнаружения повреждений на основе обучения для нескольких стран». Arxiv Preprint arxiv: 2008.13101, 2020.
[3] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg и L. Fei-Fei, «ImageNet крупномасштабного визуального признания», Международный журнал компьютерного зрения (IJCV), вып. 115, нет. 3, с. 211–252, 2015.
[4] S. Ren, K. He, R. Girshick и J. Sun, «Более быстрый R-CNN: на пути к обнаружению объектов в реальном времени с помощью региональных сетей предложений», в области авансов в системах обработки нейронной информации, стр. 91–99, 2015.
[5] Т.-Ю. Лин, П. Доллар, Р. Б. Гиршик, К. Хе, Б. Харихаран и С. Дж. 1, с. 4, 2017.
[6] Т.-Ю. Лин, М. Мейр, С. Удостоит, Дж. Хейс, П. Перона, Д. Раманан, П. Доллар и С. Л. Зитник. «Microsoft Coco: Общие объекты в контексте. На европейской конференции по компьютерному видению, страницы 740–755. Springer, 2014.
[7] Т.-Ю. Лин, П. Гоял, Р. Гиршик, К. Хе, П. Доллар. Фокусная потеря для обнаружения плотного объекта. В материалах Международной конференции IEEE 2017 года по компьютерному видению (ICCV), с. 2380–7504, Венеция, Италия, 22–29 октября 2017 года.
[8] K. He, G. Gkioxari, P. Dollar и R. Girshick, «Mask R-CNN», Международная конференция IEEE по компьютерному видению (ICCV), с. 2980–2988, IEEE, 2017.
[9] К. Хе, Х. Чжан, С. Рен и Дж. Сан. Глубокое остаточное обучение для распознавания изображений. В материалах конференции IEEE по компьютерному видению и распознаванию образцов, страницы 770–778, 2016.
[10] С. Иоффе и С. Сегеди. Нормализация партии: ускорение глубокого сетевого обучения за счет сокращения внутреннего ковариатного сдвига. На Международной конференции по машинному обучению, страницы 448–456, 2015.
[11] W. Liu, D. Anguelov, D. Erhan, C. Szeedy, S. Reed, C.-Y. Фу и А. С. Берг, «SSD: одноразовый мультипокс -детектор», в Европейской конференции по компьютерному видению (ECCV), 2016.
[12] М. Эмингем, Л. Ван Гул, К. К. Уильямс, Дж. Винн и А. Зиссерман. Задача классов Visual Object (VOC). Международный журнал компьютерного видения, 88 (2): 303–338, 2010.
[13] Дж. Редмон и А. Фархади. Yolo9000: лучше, быстрее, сильнее. В CVPR, 2017.
[14] Y. Wu, A. Kirillov, F. Massa, W.-Y. Ло и Р. Гиршик. Detectron2. https://github.com/facebookresearch/detectron2, 2019.
[15] G. Jocher, A. Stoken, J. Borovec, Nanocode012, Christopherstan, L. Changyu, Laughing, A. Hogan, Lorenzomamma, Tkianai, Yxnong, Alexwang1900, L. Diaconu, Marc, Wanghaoyang0106, Ml5ah, Doug, J. poznans, L. y. y. y. y. y. y. y. y. y. y. y. y. y. y. y. y. y., l. P. Rai, R. Ferriday, T. Sullivan, W. Xinyu, Yuriribeiro, E. R. Claramunt, Hopesala, Pritul Dave и Yzchen, «Ultralytics/Yolov5: v3.0», август 2020. [Online]. Доступно: https://doi.org/10.5281/zenodo.3983579.
[16] C.Y. Ван, Х.Ю. Марк Ляо, Y.H. Wu, P.Y. Чен, J.W. Ши, И.Х. Дари. CSPNet: новая основа, которая может улучшить возможности обучения CNN, в: Труды конференции IEEE/CVF по компьютерным зрению и семинарам по распознаванию моделей, стр. 390–391, 2020.
[17] К. Хе, Х. Чжан, С. Рен, Дж. Сан. Пространственная пирамида в глубоких сверточных сетях для визуального распознавания. IEEE Транзакции по анализу шаблонов и интеллектую машины 37, 1904–1916. URL: https: // doi.org/10.1109/tpami.2015.2389824, doi: 10.1109/tpami.2015. 2389824, 2015
[18] L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff и H. Adam. Encoderdecoder с Atrous Scretabible Svolution для сегментации семантического изображения. DeepLabv3plus, ECCV, 2018.
[19] L. Liu, W. Ouyang, X. Wang et al. Глубокое обучение для обнаружения общего объекта: опрос. Международный журнал Computer Vision 128, 261–318. Https://doi.org/10.1007/S11263-019-01247-4, 2020.
[20] S. Xie, R. Girshick, P. Dollár, Z. Tu, K. He. Агрегированные остаточные преобразования для глубоких нейронных сетей, Arxiv Preprint Arxiv: 1611.05431, 2016.
[21] I. J. Goodfellow, J.P.- Abadie, M. Mirza, B. Xu, D. W.-Farley, S. Ozair, A. Courville, Y. Bengio. Генеративные состязательные сети, NIPS, 2014
[22] JRA. Групп по техническому обслуживанию и ремонту Pavement 2013. Японская дорожная ассоциация, 1 -й. издание, 2013.
[23] Д. Арья, Х. Маэда, С. К. Гош, Д. Тошнивал, Х. Омата, Т. Кашияма и Ю. Секимото. «Глобальное обнаружение урона дороги: современные решения». Arxiv: 2011.08740, 2020.
Авторы:
(1) Рахул Вишвакарма, Лаборатория Analytics & Solutions и Solutions, Hitachi America Ltd., Санта -Клара, Калифорния, США (Rahul.vishwakarma@hal.hitachi.com);
(2) Равигопал Веннелаканти, Лаборатория Analytics & Solutions, Hitachi America Ltd., Research & Development, Санта -Клара, Калифорния, США (Ravigopal.vennelakanti@hal.hitachi.com).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)